From Static to Conversational: MathChat and MathChatsync Open New Doors for Dialogue-Based Math with LLMs
Математическое рассуждение давно является критической областью исследований в области компьютерных наук. С появлением больших языковых моделей (LLM) значительно продвинулись в автоматизации математического решения проблем. Это включает разработку моделей, которые могут интерпретировать, решать и объяснять сложные математические проблемы, что делает эти технологии все более актуальными в образовательных и практических приложениях. LLM преобразуют наш подход к математическому образованию и исследованиям, предоставляя инструменты, которые повышают понимание и эффективность.
Вызовы математического рассуждения
Одним из основных вызовов в математическом рассуждении является обеспечение возможности моделями управлять многоразовыми взаимодействиями. Традиционные бенчмарки обычно оценивают модели на основе их способности решать одноразовые вопросы. Однако реальные сценарии часто требуют продолжительного рассуждения и способности следовать инструкциям в течение нескольких взаимодействий. Эта сложность требует расширенных возможностей в понимании диалога и динамическом решении проблем. Обеспечение возможности моделями управлять этими сложными задачами критически важно для их применения в образовательных инструментах, автоматизированных системах обучения и интерактивных помощниках по решению проблем.
Существующие рамки для математического рассуждения в больших языковых моделях (LLM)
Существующие рамки для математического рассуждения в больших языковых моделях (LLM) включают бенчмарки, такие как GSM8K, MATH и SVAMP, которые оценивают ответы на одноразовые вопросы. Выдающиеся модели, такие как MetaMath, WizardMath и DeepSeek-Math, фокусируются на улучшение производительности через такие техники, как подсказки Chain of Thought (CoT), дистилляция синтетических данных и обширное предварительное обучение на математических корпусах. Эти методы улучшают способности моделей в решении изолированных математических проблем, но нуждаются в улучшении в оценке многоразовых, диалоговых взаимодействий, необходимых для реальных приложений.
Новый бенчмарк — MathChat
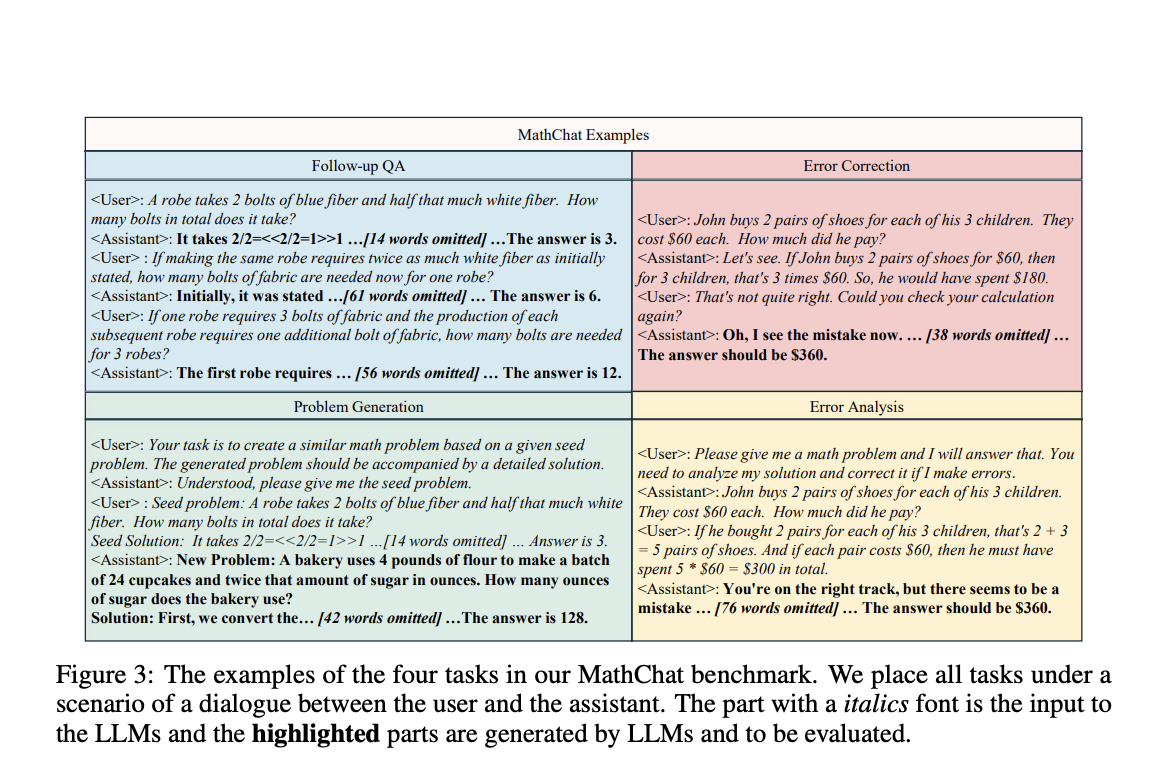
Исследователи из Университета Нотр-Дам и Tencent AI Lab представили новый бенчмарк под названием MathChat, чтобы заполнить этот пробел. MathChat оценивает производительность LLM в многоразовых взаимодействиях и открытом вопросно-ответном формате. Этот бенчмарк нацелен на расширение возможностей LLM в математическом рассуждении через фокусировку на задачах, основанных на диалоге. MathChat включает задачи, вдохновленные образовательными методиками, такими как последующее вопросно-ответное взаимодействие и коррекция ошибок, которые являются важными для разработки моделей, способных понимать и реагировать на динамические математические запросы.
Эксперименты и результаты
В ходе экспериментов исследователи обнаружили, что, хотя современные передовые LLM хорошо справляются с одноразовыми задачами, они значительно затрудняются с многоразовыми и открытыми задачами. Например, модели, настроенные на обширные данные вопросов и ответов на одноразовые вопросы, показали ограниченную способность к решению более сложных задач MathChat. Внедрение синтетического диалогового набора данных, MathChatsync, значительно улучшило производительность модели, подчеркивая важность обучения с разнообразными разговорными данными. Этот набор данных сосредоточен на улучшении возможностей взаимодействия и следования инструкциям, важных для многоразового рассуждения.
Исследователи оценили различные LLM на бенчмарке MathChat, отмечая, что эти модели отлично проявляют себя в ответах на одноразовые вопросы, но показывают плохие результаты в сценариях, требующих продолжительного рассуждения и понимания диалога. Например, MetaMath добился точности 77.18% в первом раунде последующего вопросно-ответного взаимодействия, но снизился до 32.16% во втором и 19.31% в третьем. Аналогично, WizardMath начал с точности 83.20%, которая упала до 44.81% и 36.86% в последующих раундах. DeepSeek-Math и InternLM2-Math также показали значительное ухудшение производительности в многоразовых взаимодействиях. Fine-tuning MathChatsync привел к существенным улучшениям: Mistral-MathChat достиг среднего общего показателя 0.661 по сравнению с 0.623 для Gemma-MathChat, указывающий на эффективность разнообразных разговорных данных обучения.
Заключение
Это исследование выявляет критическую проблему в текущих возможностях LLM и предлагает новый бенчмарк и набор данных для решения этой проблемы. Бенчмарк MathChat и набор данных MathChatsync представляют собой значительные шаги в развитии моделей, способных эффективно участвовать в многоразовом математическом рассуждении, открывая путь для более продвинутых и интерактивных приложений ИИ в математике. Исследование подчеркивает необходимость разнообразных данных обучения и всесторонней оценки для улучшения возможностей LLM в реальных сценариях решения математических проблем. Эта работа указывает на потенциал LLM в изменении математического образования и исследований путем предоставления более интерактивных и эффективных инструментов.

























