«`html
Large Language Models (LLMs) for OCR Post-Correction
Оптическое распознавание символов (OCR) преобразует текст с изображений в редактируемые данные, но часто допускает ошибки из-за низкого качества изображения или сложного макета. Технология OCR ценна для цифровизации текста, но достижение высокой точности может быть сложным и обычно требует постоянной доработки.
Практические решения и ценность:
Большие языковые модели (LLMs), такие как модель ByT5, обладают потенциалом для улучшения посткоррекции OCR. Эти модели обучены на обширных текстовых данных и способны понимать и генерировать язык, близкий к человеческому. Используя эту способность, LLMs могут потенциально корректировать ошибки OCR более эффективно, улучшая общую точность процесса извлечения текста. Тонкая настройка LLMs на задачи, связанные с OCR, показала, что они могут превзойти традиционные методы коррекции ошибок, что свидетельствует о значительном улучшении результатов OCR и повышении связности текста.
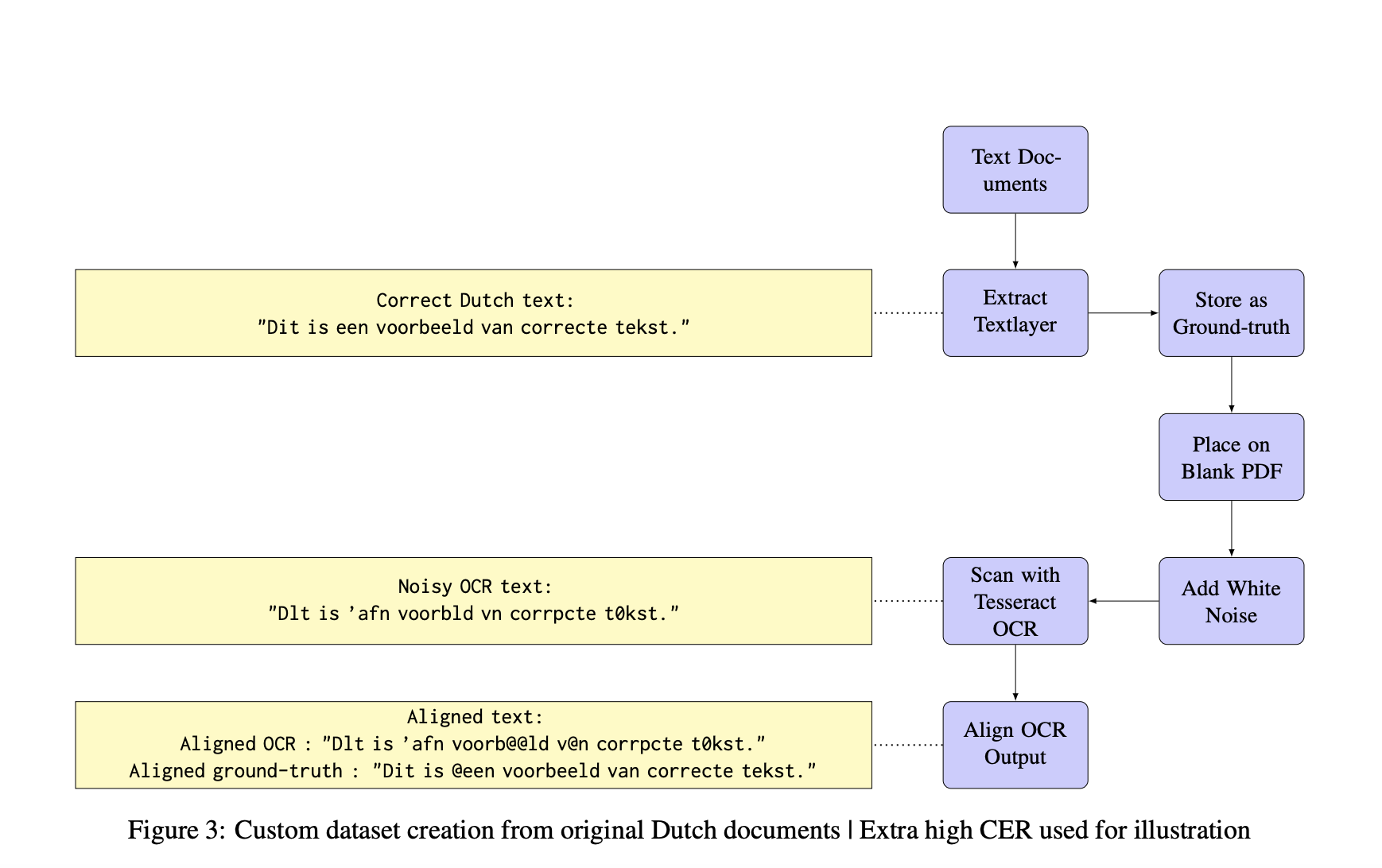
В этом контексте исследователь из Университета Твенте недавно провел работу по изучению потенциала LLMs для улучшения посткоррекции OCR. В этом исследовании рассматривается метод, который использует возможности понимания языка современных LLMs для обнаружения и исправления ошибок в выводах OCR. Применяя этот подход к современным документам клиентов, обработанным с помощью движка OCR Tesseract, и историческим документам из набора данных ICDAR, исследование оценивает эффективность тонко настроенных LLMs на уровне символов, таких как ByT5, и генеративных моделей, таких как Llama 7B.
Предложенный подход включает тонкую настройку LLMs специально для посткоррекции OCR. Методология начинается с выбора моделей, подходящих для этой задачи: ByT5, модель на уровне символов, тонко настраивается на наборе данных выводов OCR, сопоставленных с эталонным текстом, для улучшения ее способности корректировать ошибки на уровне символов. Кроме того, в сравнении включается Llama 7B, общецелевая генеративная LLM, из-за ее большого размера параметров и продвинутого понимания языка.
Тонкая настройка адаптирует эти модели к специфическим особенностям ошибок OCR путем их обучения на этом специализированном наборе данных. Различные методы предварительной обработки, такие как приведение текста к нижнему регистру и удаление специальных символов, применяются для стандартизации ввода и потенциального улучшения производительности моделей. Процесс тонкой настройки включает обучение ByT5 в его небольших и базовых версиях, в то время как Llama 7B используется в своем предварительно обученном состоянии для обеспечения сравнительной базы. Эта методология использует LLMs на уровне символов и генеративные LLMs для улучшения точности OCR и связности текста.
Оценка предложенного метода включала сравнение его с техниками коррекции ошибок после OCR, не основанными на LLMs, с использованием ансамбля моделей последовательности-в-последовательность в качестве базовой линии. Производительность измерялась с использованием показателя снижения ошибок на уровне символов (CER) и метрик точности, полноты и F1. Тонко настроенная базовая модель ByT5 с длиной контекста 50 символов показала лучшие результаты на пользовательском наборе данных, снижая CER на 56%. Этот результат значительно улучшился по сравнению с базовым методом, который достиг максимального снижения CER на уровне 48% в лучших условиях. Более высокие значения F1 модели ByT5 в основном были обусловлены увеличением полноты, демонстрируя ее эффективность в коррекции ошибок OCR в современных документах.
В заключение, данная работа представляет новый подход к посткоррекции OCR с использованием возможностей больших языковых моделей (LLMs), в частности тонко настроенной модели ByT5. Предложенный метод значительно улучшает точность OCR, достигая снижения ошибок на уровне символов (CER) на 56% в современных документах, превосходя традиционные модели последовательности-в-последовательность. Это демонстрирует потенциал LLMs в улучшении систем распознавания текста, особенно в ситуациях, где качество текста критично. Результаты подчеркивают эффективность использования LLMs для коррекции ошибок после OCR, открывая путь для дальнейших достижений в этой области.
«`

























