Раскрытие моделей видение-язык: глубокое исследование
Модели видение-язык (VLM), способные обрабатывать как изображения, так и текст, приобрели огромную популярность благодаря своей универсальности в решении широкого круга задач, от поиска информации в отсканированных документах до генерации кода по скриншотам. Однако развитие этих мощных моделей затрудняется недостатком понимания критических проектных решений, которые действительно влияют на их производительность. Этот знаковый пробел затрудняет исследователям сделать значительные успехи в этой области. Для решения этой проблемы команда исследователей из Hugging Face и Sorbonne Université провела обширные эксперименты, чтобы раскрыть факторы, которые имеют наибольшее значение при построении моделей видение-язык, сосредотачиваясь на архитектуре модели, мультимодальных процедурах обучения и их влиянии на производительность и эффективность.
Практические решения и ценность
Современные передовые модели VLM обычно используют предварительно обученные одномодальные модели, такие как большие языковые модели и кодировщики изображений, и объединяют их через различные архитектурные выборы. Однако исследователи обнаружили, что эти проектные решения часто принимаются без должного обоснования, что приводит к недопониманию их влияния на производительность. Чтобы прояснить этот вопрос, они сравнили различные архитектуры моделей, включая кросс-внимание и полностью авторегрессивные архитектуры, а также влияние замораживания или размораживания предварительно обученных основ во время обучения.
Исследователи также углубились в мультимодальную процедуру обучения, исследуя стратегии, такие как изученное пулинг для уменьшения количества визуальных токенов, сохранение исходного соотношения сторон и разрешения изображения, а также разделение изображения для обмена вычислений на производительность. Путем тщательной оценки этих проектных решений в контролируемой среде они стремились извлечь экспериментальные результаты, которые могли бы направить разработку более эффективных и эффективных моделей VLM. Вдохновленные этими результатами, исследователи обучили Idefics2, открытую 8-миллиардную параметрическую фундаментальную модель видение-язык, с целью достижения передовой производительности при сохранении вычислительной эффективности.
Одним из ключевых аспектов, исследованных исследователями, был выбор предварительно обученных основ для компонентов видения и языка. Они обнаружили, что для фиксированного числа параметров качество основы языковой модели оказывает более значительное влияние на производительность конечной модели VLM, чем качество основы видения. В частности, замена менее качественной языковой модели (например, LLaMA-1-7B) на более качественную (например, Mistral-7B) привела к более существенному улучшению производительности по сравнению с модернизацией кодировщика видения (например, с CLIP-ViT-H на SigLIP-SO400M).
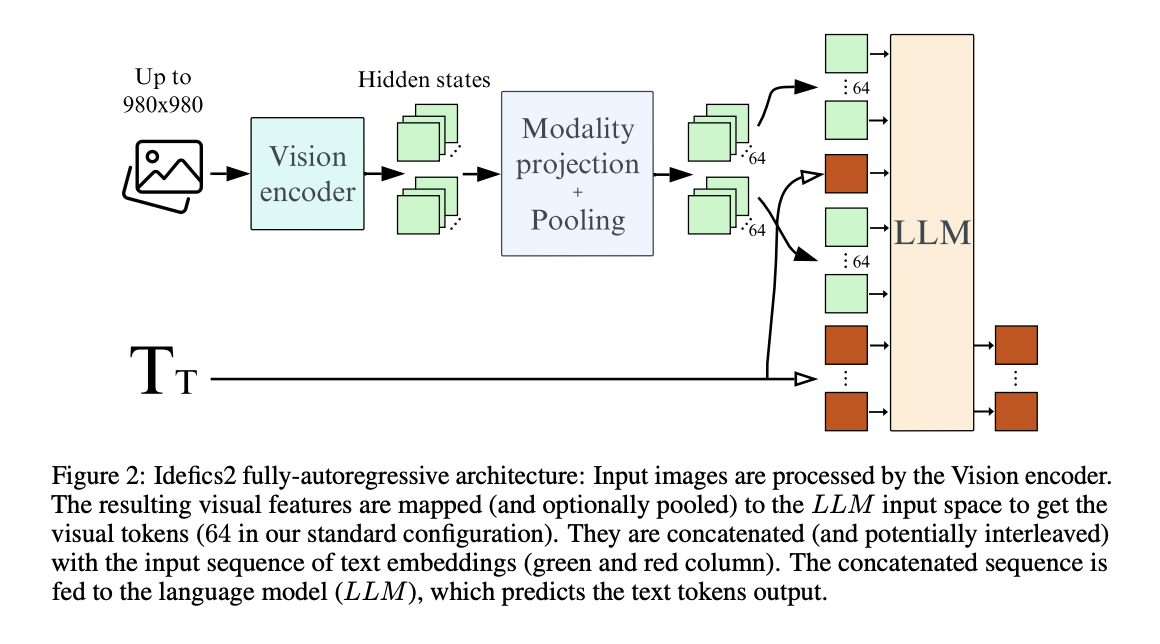
Исследователи затем сравнили кросс-внимательные и полностью авторегрессивные архитектуры, два распространенных выбора в проектировании VLM. В то время как архитектура кросс-внимания изначально показала лучшие результаты, когда предварительно обученные основы были заморожены, полностью авторегрессивная архитектура превзошла ее, когда предварительно обученные основы были разрешены адаптироваться во время обучения. Интересно, что размораживание предварительно обученных основ в рамках полностью авторегрессивной архитектуры могло привести к расхождениям в обучении, которые они смягчили, используя метод низкоранговой адаптации (LoRA) для стабилизации процесса обучения.
Для повышения эффективности исследователи исследовали использование изученного пулинга для уменьшения количества визуальных токенов, необходимых для каждого изображения. Эта стратегия улучшила производительность на последующих задачах и значительно снизила вычислительные затраты во время обучения и вывода. Кроме того, они адаптировали кодировщик видения, предварительно обученный на изображениях фиксированного размера, чтобы сохранить исходное соотношение сторон и разрешение входных изображений, обеспечивая гибкие вычисления во время обучения и вывода без ухудшения производительности.
Для внедрения этих результатов в практику исследователи обучили Idefics2, открытую 8-миллиардную параметрическую фундаментальную модель видение-язык. Idefics2 была обучена с использованием многоступенчатого предварительного обучения, начиная с предварительно обученных моделей SigLIP-SO400M и Mistral-7B. Она была обучена на разнообразных источниках данных, включая переплетенные документы изображение-текст из OBELICS, пары изображение-текст из PMD и LAION COCO, а также документы PDF из OCR-IDL, PDFA и Rendered Text. Эти разнообразные данные обучения направлены на улучшение возможностей Idefics2 в понимании и обработке различных мультимодальных входов, используя понимание исследователей эффективного и эффективного проектирования моделей VLM.
Исследователи оценили производительность своих предложенных методов и проектных решений с использованием различных наборов данных, включая VQAv2, TextVQA, OKVQA и COCO. Общие результаты показали, что разделение изображений на подизображения во время обучения позволило обменять вычислительную эффективность на улучшенную производительность во время вывода, особенно в задачах, связанных с чтением текста на изображении.
Количественные результаты показали, что их подход превзошел текущие передовые модели VLM в той же категории размера, достигнув впечатляющей производительности на бенчмарках, таких как MMMU, MathVista, TextVQA и MMBench. Заметно, что Idefics2 проявила производительность на уровне моделей в четыре раза большего размера и даже соответствовала производительности закрытых моделей, таких как Gemini 1.5 Pro, на нескольких бенчмарках. Например, на бенчмарке MathVista Idefics2 набрала 54,9%, соответствуя производительности Gemini 1.5 Pro. На сложном бенчмарке TextVQA, который тестирует способности OCR, Idefics2 набрала 73,6%, превзойдя более крупные модели, такие как LLaVA-Next (68,9%) и DeepSeek-VL (71,5%).
Эти результаты демонстрируют передовую производительность Idefics2, сохраняя при этом вычислительную эффективность во время вывода, демонстрируя эффективность подхода исследователей в построении мощных и эффективных моделей VLM через обоснованные проектные решения.
Хотя исследователи сделали значительные шаги в понимании критических факторов в развитии VLM, вероятно, существуют дальнейшие возможности для улучшения и исследований. Поскольку область продолжает развиваться, их работа служит прочным фундаментом для будущих исследований и прогресса в моделировании видение-язык. Исследователи также выпустили свой набор данных для обучения, The Cauldron, массовую коллекцию из 50 наборов данных видение-язык. Открыв свою работу для общественности, включая модель, результаты и обучающие данные, они стремятся способствовать развитию области и позволить другим строить на основе их исследований, способствуя сотрудничеству в моделировании видение-язык.

























