Важность выбора подходящего бэкенда для обслуживания LLMs
В больших языковых моделях (LLMs) выбор правильного бэкенда для обслуживания LLMs имеет важное значение. Производительность и эффективность этих бэкендов напрямую влияют на опыт пользователя и операционные расходы.
Основные метрики
Для оценки производительности этих бэкендов в исследовании использовались две основные метрики:
- Время до первого токена (TTFT): Это измеряет задержку от отправки запроса до генерации первого токена. Более низкое TTFT критически важно для приложений, требующих мгновенной обратной связи, таких как интерактивные чат-боты.
- Скорость генерации токенов: Это оценивает, сколько токенов модель генерирует в секунду во время декодирования.
Результаты для Llama 3 8B и Llama 3 70B с 4-битной квантованием
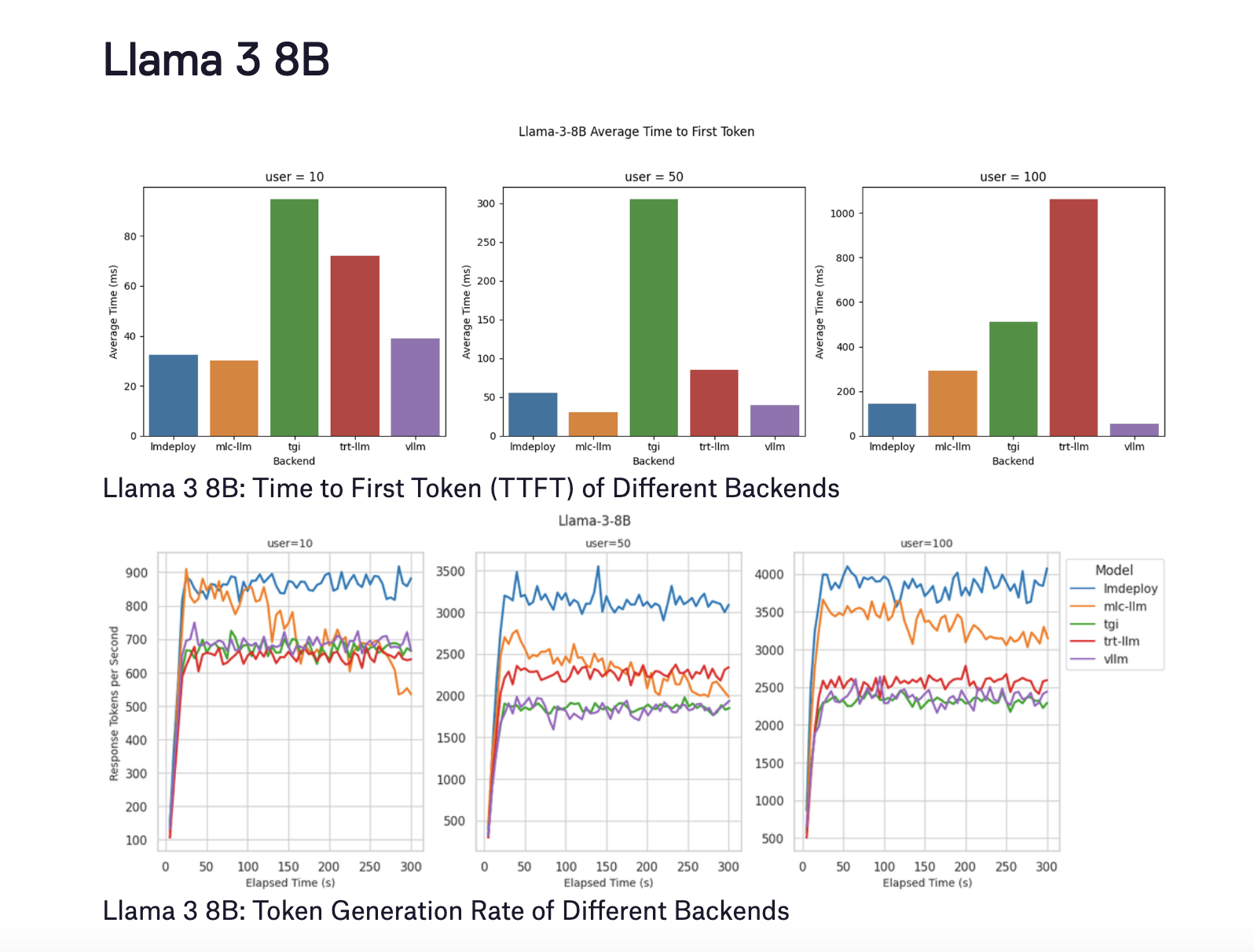
Для модели Llama 3 8B были получены следующие результаты:
- LMDeploy: Показала лучшую производительность декодирования и высокую скорость генерации токенов для 100 пользователей.
- MLC-LLM: Достигла немного более низкой скорости генерации токенов, однако ее производительность ухудшилась после пяти минут бенчмаркинга.
- vLLM: Хотя vLLM отличается в поддержании низкого TTFT, его скорость генерации токенов была менее оптимальной.
Для модели Llama 3 70B с 4-битной квантованием производительность варьировалась между бэкендами.
- LMDeploy: Предоставила самую высокую скорость генерации токенов и поддерживала самое низкое TTFT для всех уровней конкурентности.
- TensorRT-LLM: Показал сходные скорости генерации токенов, но имел значительное увеличение TTFT при достижении 100 одновременных пользователей.
- vLLM: Наблюдалось постоянно низкое TTFT, но скорость генерации токенов отставала из-за отсутствия оптимизации для квантованных моделей.
Заключение
Исследование показывает, что LMDeploy обладает превосходной производительностью в TTFT и скорости генерации токенов, что делает его отличным выбором для сценариев с высокой нагрузкой. vLLM заметен своей способностью поддерживать низкую задержку, что критически важно для приложений, требующих быстрых времен ответа. В то время как MLC-LLM показывает потенциал, ему требуется дальнейшая оптимизация для эффективной работы под нагрузкой.
Эти выводы дают основу для разработчиков и предприятий, желающих развернуть LLMs, для принятия обоснованных решений относительно выбора подходящего бэкенда. Интеграция этих бэкендов с платформами, такими как BentoML и BentoCloud, дальше оптимизирует процесс развертывания, обеспечивая оптимальную производительность и масштабируемость.

























