«`html
Выравнивание больших языковых моделей с разнообразными пользовательскими предпочтениями с помощью многофасетных системных сообщений: подход JANUS
Текущие методы выравнивания LLMs часто соответствуют общественным предпочтениям, предполагая, что это идеально. Однако это не учитывает разнообразие и тонкую природу индивидуальных предпочтений, что затрудняет масштабирование из-за необходимости обширного сбора данных и обучения модели для каждого человека.
Практические решения и ценность:
Для выравнивания LLMs с широкими человеческими ценностями, такими как полезность и безопасность, разработаны методы, такие как RLHF и настройка инструкций. Однако этот подход должен учитывать противоречивые индивидуальные предпочтения, что приводит к разногласиям в аннотациях и нежелательным характеристикам модели, таким как многословность.
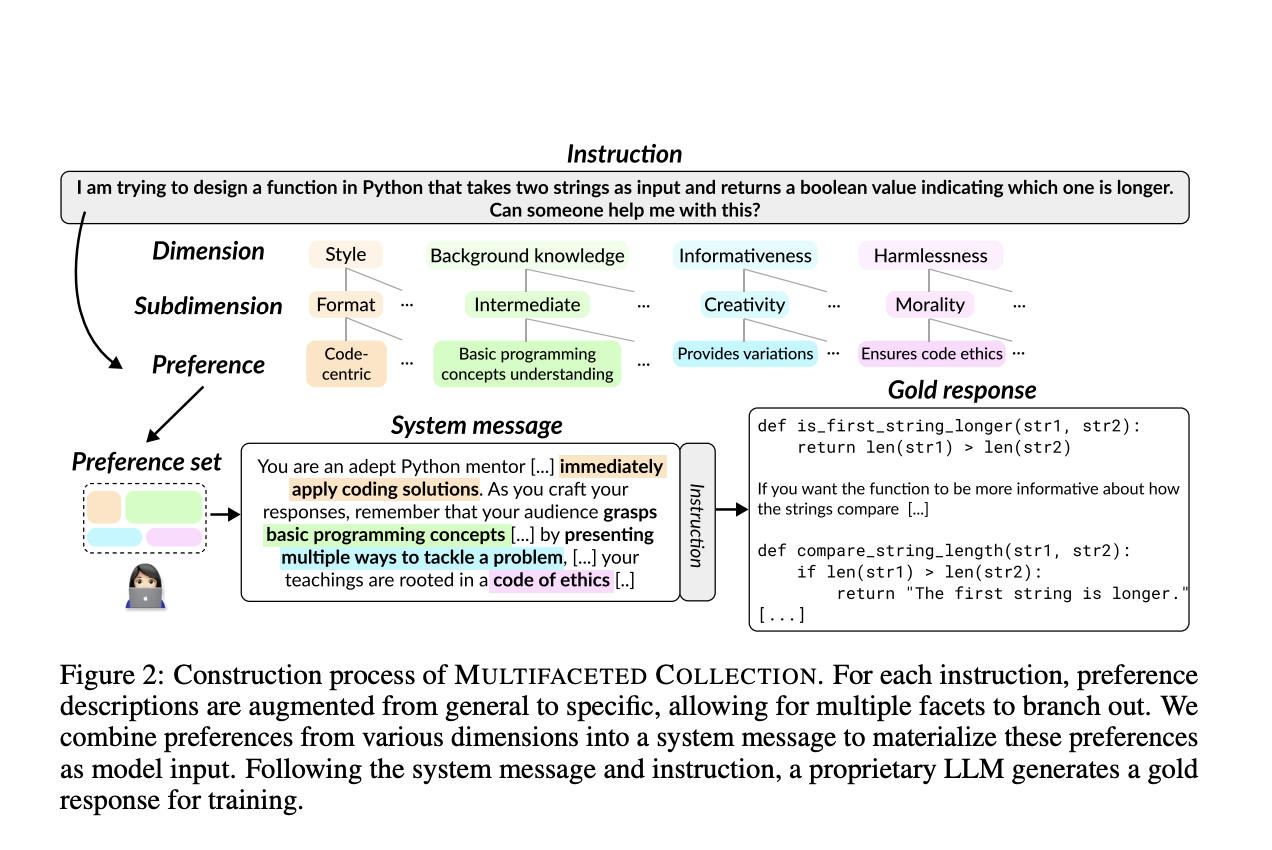
Исследователи KAIST AI и Carnegie Mellon University разработали новую парадигму, в которой пользователи указывают свои ценности в системных сообщениях для лучшего выравнивания LLMs с индивидуальными предпочтениями. Они создали MULTIFACETED COLLECTION, набор данных с 192 тыс. уникальных системных сообщений и 65 тыс. инструкций. Обучив LLM 7B по имени JANUS на этом наборе данных, они успешно протестировали его на различных бенчмарках, достигнув высокой производительности и продемонстрировав, что разнообразное обучение системных сообщений улучшает соответствие индивидуальным и общественным предпочтениям. Их работа доступна на GitHub.
Выравнивание LLMs с разнообразными человеческими предпочтениями крайне важно, так как у разных людей могут быть разные ценности для одной и той же задачи. Большинство исследований используют конвейер RLHF, создавая настраиваемые функции вознаграждения для лучшего отражения различных точек зрения и снижения разногласий в аннотациях. Некоторые исследования сосредотачиваются на изучении нескольких распределений предпочтений или обучении отдельных моделей для пользовательских предпочтений. В то время как эти методы часто включают непрактичное повторное обучение, предложенный подход обучает LLM адаптироваться к явно указанным предпочтениям во время тестирования. Системные сообщения, используемые для предоставления контекста и направления поведения LLM, показали улучшение производительности при диверсификации, но предыдущие исследования ограничивали их область. Эта работа масштабирует системные сообщения для лучшего соответствия пользовательским предпочтениям.
Существующие наборы данных для выравнивания обычно отражают широкие предпочтения, такие как полезность и безопасность. Цель состоит в создании набора данных, отражающего более конкретные предпочтения, такие как «кодо-центрический стиль» или «обеспечение этики кода» для решений по кодированию. Предпочтения представляют собой детальные текстовые описания желательных качеств в ответах. Два требования для отражения разнообразных человеческих предпочтений — это многофасетность и явность. Стратегия иерархического дополнения предпочтений обеспечивает разнообразие фасет предпочтений. Многофасетные предпочтения включаются во входы модели через системные сообщения. Построение данных включает выбор 65 тыс. инструкций, генерацию 192 тыс. системных сообщений и создание эталонных ответов с использованием GPT-4 Turbo. Модели обучаются с использованием нескольких методов, включая настройку инструкций и оптимизацию предпочтений.
Бенчмарки для оценки модели JANUS включают многофасетность, полезность и безопасность. MULTIFACETED BENCH улучшает пять существующих бенчмарков для оценки специфических контекстуальных нюансов. Полезность оценивается с использованием Alpaca Eval 2.0, MT-Bench и Arena Hard Auto v0.1, в то время как безопасность оценивается с помощью RealToxicityPrompts. Базовыми являются различные предварительно обученные, настроенные по инструкциям и оптимизированные по предпочтениям модели. Оценки включают человеческие и LLM-оценки, показывая, что JANUS превосходит в генерации персонализированных ответов, поддерживая полезность и обеспечивая низкую токсичность. Эти результаты демонстрируют способность JANUS адаптироваться к разнообразным предпочтениям и поддерживать соответствие общественным полезным ценностям без ущерба для безопасности.
В заключение, несколько исследований абляции показывают устойчивую производительность JANUS как с системными сообщениями, так и без них. Многофасетные возможности JANUS позволяют ему генерировать качественные ответы независимо от контекста. Включение многофасетных системных сообщений во время обучения улучшает производительность как в многофасетности, так и в полезности. Однако обучение без системных сообщений представляет вызов в эффективном отражении человеческих предпочтений. JANUS также может служить в качестве персонализированной модели вознаграждения, улучшая производительность на MULTIFACETED BENCH через лучший выбор из n образцов. Этот метод выравнивает LLMs с разнообразными пользовательскими предпочтениями с помощью уникального протокола системных сообщений и набора данных MULTIFACETED COLLECTION, обеспечивая высокую производительность и адаптивность без постоянного повторного обучения.
Посмотрите статью и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 43k+ ML SubReddit. Также, посмотрите нашу платформу мероприятий по ИИ.
«`

























