«`html
Продвинутые решения в области искусственного интеллекта
Недавние исследования показали, что Llama 3 значительно превзошел GPT-3.5 и даже GPT-4 в нескольких тестах, продемонстрировав свою эффективность и специализированную производительность, несмотря на меньшее количество параметров. Однако GPT-4o, обладающий расширенными мультимодальными возможностями, вернул себе лидирующее положение. Llama 3, используя инновации, такие как Grouped-Query Attention, преуспевает в переводе и генерации диалогов, в то время как GPT-4 демонстрирует превосходные навыки рассуждения и решения проблем. GPT-4o дополнительно улучшает эти способности, укрепляя свое доминирование с помощью улучшенной нейронной архитектуры и мультимодальной компетентности.
Llama3-V: инновационная мультимодальная модель
Представлена модель Llama3-V, основанная на Llama3, обученная за менее чем $500. Она интегрирует визуальную информацию, встраивая входные изображения в патч-вложения с использованием модели SigLIP. Эти вложения выравниваются с текстовыми токенами через блок проекции с использованием блоков самовнимания, размещая визуальные и текстовые вложения на одной плоскости. Визуальные токены затем добавляются к текстовым токенам, и совместное представление обрабатывается через Llama3, улучшая его способность понимать и интегрировать визуальные данные.
Модель SigLIP для встраивания изображений использует попарную сигмоидальную функцию потерь для обработки каждой пары изображение-текст независимо, в отличие от контрастной функции потерь CLIP с мягкой нормализацией. Визионный кодер SigLIP разделяет изображения на неперекрывающиеся патчи, проецирует их в пространство вложений меньшей размерности и применяет самовнимание для извлечения признаков более высокого уровня. Для выравнивания визуальных вложений модели SigLIP с текстовыми вложениями Llama3 используется модуль проекции с двумя блоками самовнимания. Визуальные токены из этих вложений добавляются к текстовым токенам, создавая совместный вход для Llama3.
Для оптимизации вычислительных ресурсов были использованы две основные стратегии. Во-первых, механизм кэширования предварительно вычисляет вложения изображений SigLIP, увеличивая использование графического процессора и размер пакета без вызова ошибок «недостатка памяти». Это разделение этапов обработки SigLIP и Llama3 повышает эффективность. Во-вторых, использование оптимизаций MPS/MLX позволяет SigLIP, благодаря его меньшему размеру, выполнять вывод на ноутбуках Mac и достигать производительности 32 изображения/сек. Эти оптимизации экономят время обучения и вывода путем эффективного управления ресурсами и максимизации использования графического процессора.
Предварительное вычисление вложений изображений с помощью SigLIP включает загрузку модели SigLIP, предварительную обработку изображений и получение векторных представлений. Изображения высокого разрешения разбиваются на патчи для эффективного кодирования. Сигмоидальная активация применяется к логитам для извлечения вложений, которые затем проецируются в совместное мультимодальное пространство с использованием матрицы весов, изученной в процессе. Эти проецированные вложения, или «латенты», добавляются к текстовым токенам для предварительного обучения Llama3. Предварительное обучение использует 600 000 пар изображение-текст, обновляя только матрицу проекции. Надзорное дообучение улучшает производительность с использованием 1 миллиона примеров, сосредотачиваясь на визионных и проекционных матрицах.
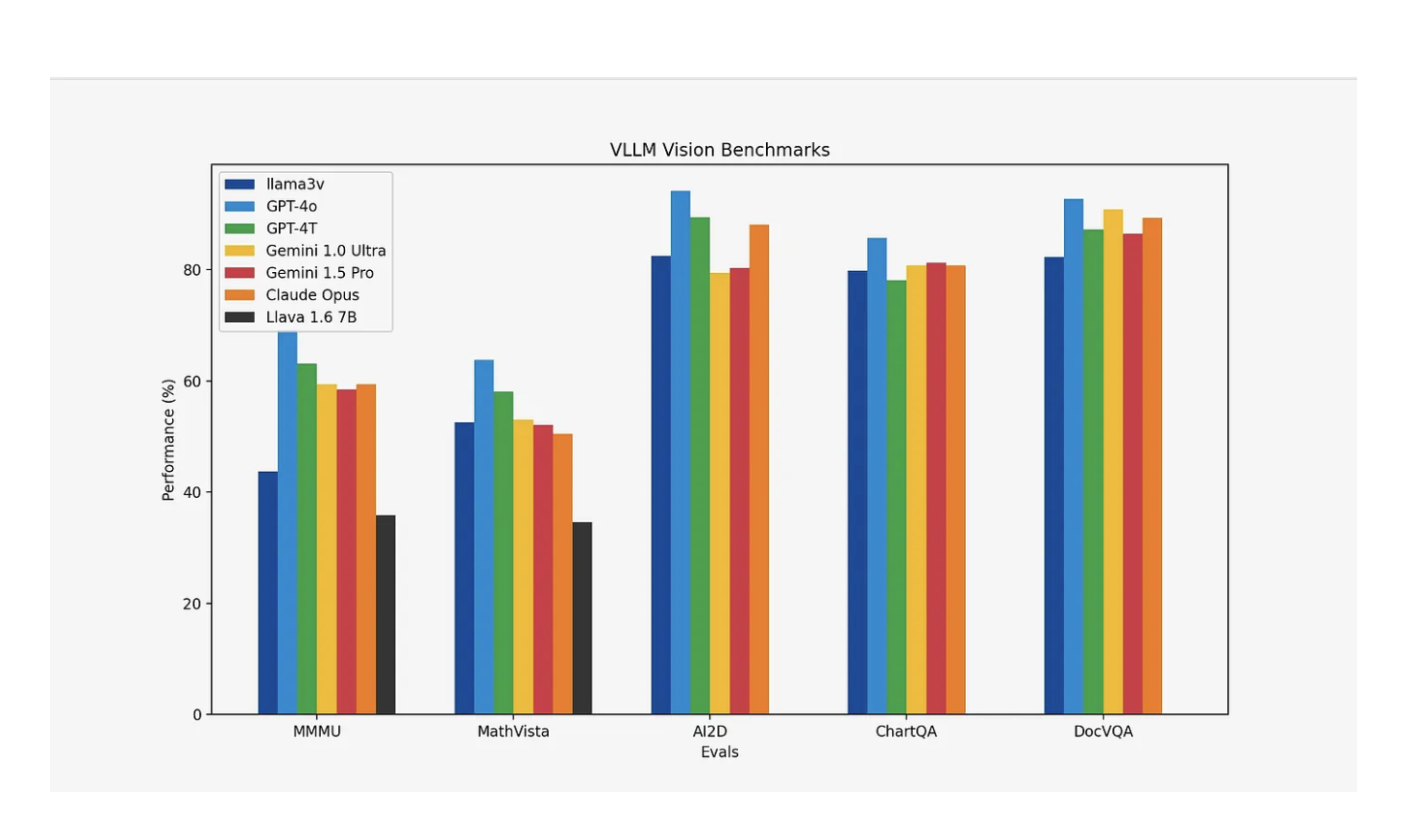
Llama3-V демонстрирует увеличение производительности на 10–20% по сравнению с Llava, ведущей моделью для мультимодального понимания. Она также проявляет сопоставимую производительность с гораздо более крупными закрытыми моделями по большинству метрик, за исключением MMMU, демонстрируя свою эффективность и конкурентоспособность несмотря на меньший размер.
В заключение, Llama3-V демонстрирует значительные достижения в области мультимодального искусственного интеллекта, превосходя Llava и конкурируя с более крупными закрытыми моделями по большинству метрик. Путем интеграции SigLIP для эффективного встраивания изображений и использования стратегических вычислительных оптимизаций Llama3-V максимизирует использование графического процессора и снижает затраты на обучение. Предварительное обучение и надзорное дообучение улучшают ее мультимодальные возможности, приводя к значительному увеличению производительности на 10–20% по сравнению с Llava. Инновационный подход и экономичное обучение устанавливают Llama3-V как конкурентоспособную и эффективную передовую модель для мультимодального понимания.
«`

























