Оценка моделей искусственного интеллекта, в частности больших языковых моделей (LLM), является быстро развивающейся областью исследований.
Исследователи фокусируются на разработке более строгих бенчмарков для оценки возможностей этих моделей в широком спектре сложных задач. Это необходимо для продвижения технологии искусственного интеллекта, поскольку предоставляет понимание сильных и слабых сторон различных систем ИИ. Понимая эти аспекты, исследователи могут принимать обоснованные решения по улучшению и совершенствованию этих моделей.
Оценка LLM: проблемы и решения
Одной из основных проблем в оценке LLM является недостаточность существующих бенчмарков в полной мере отражать возможности моделей. Традиционные бенчмарки, такие как оригинальный набор данных Massive Multitask Language Understanding (MMLU), часто не обеспечивают всестороннюю оценку. Эти бенчмарки обычно включают ограниченные варианты ответов и в основном фокусируются на вопросах, не требующих обширного рассуждения. Это подчеркивает необходимость более сложных и всесторонних наборов данных для более точной оценки разнообразных возможностей этих передовых систем ИИ.
Текущие методы оценки LLM, такие как оригинальный набор данных MMLU, предоставляют некоторые идеи, но имеют существенные ограничения. Оригинальный набор данных MMLU включает только четыре варианта ответов на вопрос, что снижает сложность и уменьшает вызов для моделей. Вопросы в основном ориентированы на знания и не требуют глубоких рассуждений, необходимых для всесторонней оценки ИИ. Эти ограничения приводят к неполному пониманию производительности моделей и подчеркивают необходимость улучшенных инструментов оценки.
Новый набор данных MMLU-Pro
Исследователи из TIGER-Lab представили набор данных MMLU-Pro для преодоления этих ограничений. Этот новый набор данных разработан для более строгого и всестороннего бенчмарка для оценки LLM. MMLU-Pro значительно увеличивает количество вариантов ответов с четырех до десяти на каждый вопрос, увеличивая сложность и реализм оценки. Включение большего количества вопросов, ориентированных на рассуждения, решает недостатки оригинального набора данных MMLU. Этот процесс включает ведущие исследовательские лаборатории по ИИ и академические учреждения с целью установления нового стандарта в оценке ИИ.
Конструкция набора данных MMLU-Pro включала тщательный процесс, чтобы обеспечить его надежность и эффективность. Исследователи начали с фильтрации оригинального набора данных MMLU, чтобы сохранить только самые сложные и актуальные вопросы. Затем они увеличили количество вариантов ответов с четырех до десяти, используя GPT-4, передовую модель ИИ. Этот процесс не ограничивался простым добавлением вариантов ответов; он включал генерацию правдоподобных отвлекающих вариантов, требующих дискриминационных рассуждений для навигации. В набор данных использовались вопросы из высококачественных сайтов по STEM, наборов данных вопросов и ответов на основе теорем и экзаменов по научным дисциплинам уровня колледжа. Каждый вопрос прошел тщательный анализ более чем десятью экспертами для обеспечения точности, справедливости и сложности, делая MMLU-Pro надежным инструментом для бенчмаркинга.
Набор данных MMLU-Pro использует десять вариантов ответов на каждый вопрос, что снижает вероятность случайного угадывания и значительно увеличивает сложность оценки. Включение большего количества проблем уровня колледжа в различных дисциплинах обеспечивает надежный и всесторонний бенчмарк. Набор данных менее чувствителен к различным подсказкам, улучшая его надежность. Хотя 57% вопросов взяты из оригинального набора данных MMLU, они были тщательно отфильтрованы для повышенной сложности и актуальности. Каждый вопрос и его варианты ответов прошли тщательный анализ более чем десятью экспертами с целью минимизации ошибок. Без использования цепочки рассуждений (CoT) лучшая модель, GPT-4o, достигает только 53% показателя.
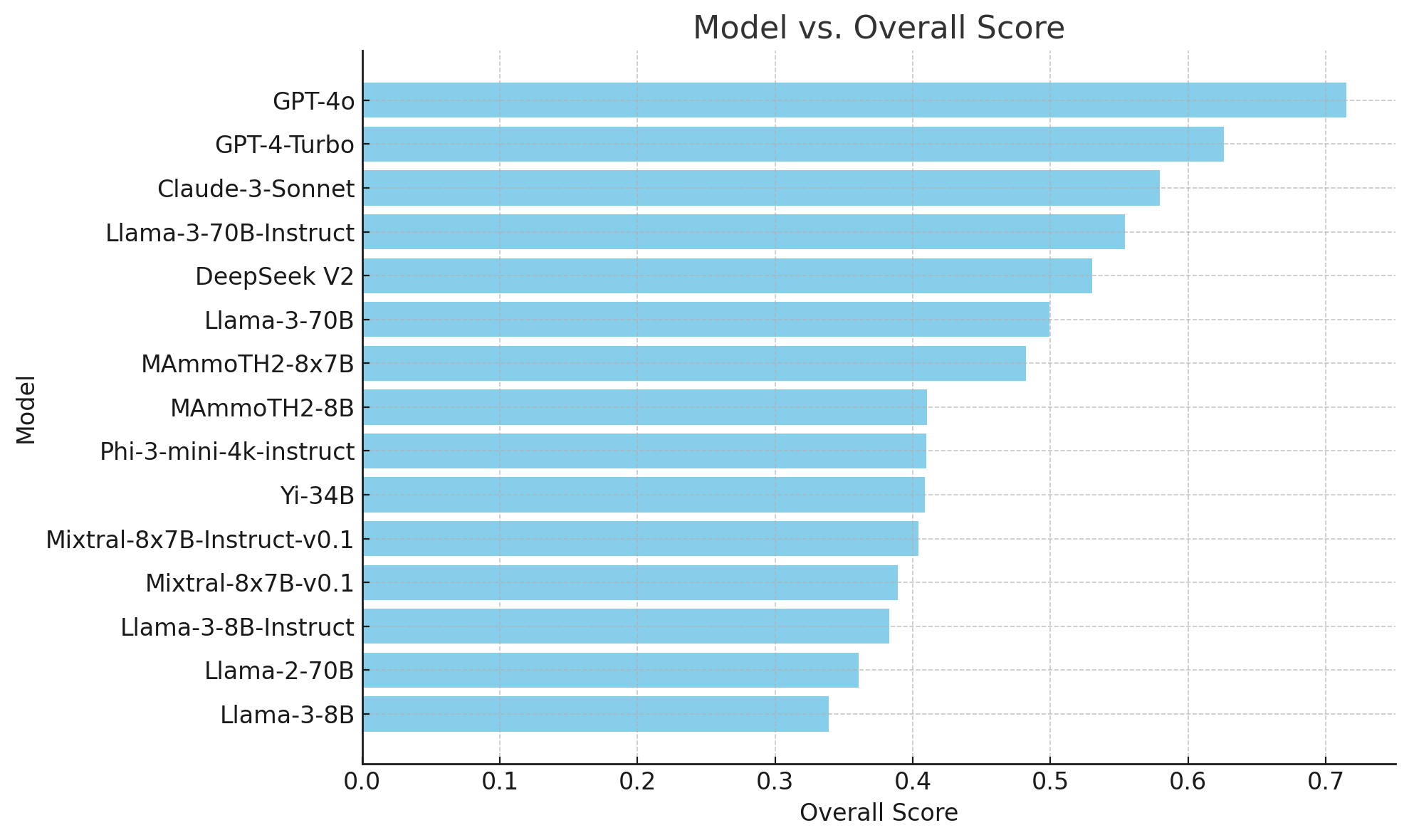
Производительность различных моделей ИИ на наборе данных MMLU-Pro была оценена, что показало значительные различия по сравнению с исходными показателями MMLU. Например, точность GPT-4 на MMLU-Pro составила 71,49%, что существенно ниже, чем его исходный показатель MMLU в 88,7%. Это снижение на 17,21% подчеркивает увеличенную сложность и надежность нового набора данных. Другие модели, такие как GPT-4-Turbo-0409, снизили свою производительность с 86,4% до 62,58%, а производительность Claude-3-Sonnet снизилась с 81,5% до 57,93%. Эти результаты подчеркивают сложность набора данных MMLU-Pro, требующую более глубоких рассуждений и навыков решения проблем.
В заключение, набор данных MMLU-Pro представляет собой переломный шаг в оценке ИИ, предлагая строгий бенчмарк, который вызывает LLM сложными вопросами, ориентированными на рассуждения. Увеличение количества вариантов ответов и включение разнообразных наборов задач делает MMLU-Pro более точным инструментом для оценки возможностей ИИ. Заметное снижение производительности моделей, таких как GPT-4, подчеркивает эффективность набора данных в выявлении областей для улучшения. Этот всесторонний инструмент оценки необходим для продвижения будущих достижений в области ИИ, позволяя исследователям совершенствовать производительность LLM.
Применение искусственного интеллекта в бизнесе
Если вы хотите использовать искусственный интеллект для развития своей компании и оставаться в числе лидеров, обратитесь к TIGER-Lab Introduces MMLU-Pro Dataset for Comprehensive Benchmarking of Large Language Models’ Capabilities and Performance. Проанализируйте, как ИИ может изменить вашу работу, определите области применения автоматизации и ключевые показатели эффективности, которые вы хотите улучшить с помощью ИИ. Подберите подходящее решение и внедряйте его постепенно, начиная с малого проекта и анализируя результаты и KPI. На основе полученных данных и опыта расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram. Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/. Этот ИИ ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























