«`html
Использование Large Language Models (LLMs) в качестве моделей человеческого познания
Ученые, изучающие Large Language Models (LLMs), обнаружили, что LLMs выполняют задачи когнитивного характера аналогично людям, часто принимая решения, которые отклоняются от рациональных норм, таких как риск и устойчивость к потерям. LLMs также проявляют человекоподобные предубеждения и ошибки, особенно в задачах вероятностных оценок и арифметических операций. Эти сходства указывают на потенциал использования LLMs в качестве моделей человеческого познания. Однако остаются значительные проблемы, включая объем данных, на которых обучаются LLMs, и неясные истоки этих поведенческих сходств.
Применение LLMs в качестве моделей человеческого познания
Существуют споры относительно пригодности LLMs в качестве моделей человеческого познания из-за нескольких проблем. LLMs обучаются на гораздо более объемных наборах данных, чем люди, и могли быть выведены на тестовые вопросы, что приводит к искусственному усилению человекоподобных поведенческих черт через процессы выравнивания ценностей. Тем не менее, настройка LLMs, таких как модель LLaMA-1-65B, на наборах данных о человеческих выборах улучшила точность прогнозирования человеческого поведения. Предыдущие исследования также подчеркивают важность синтетических наборов данных для расширения возможностей LLMs, особенно в задачах решения проблем, таких как арифметика. Предварительное обучение на таких наборах данных может существенно улучшить производительность в прогнозировании человеческих решений.
Практические решения и ценность
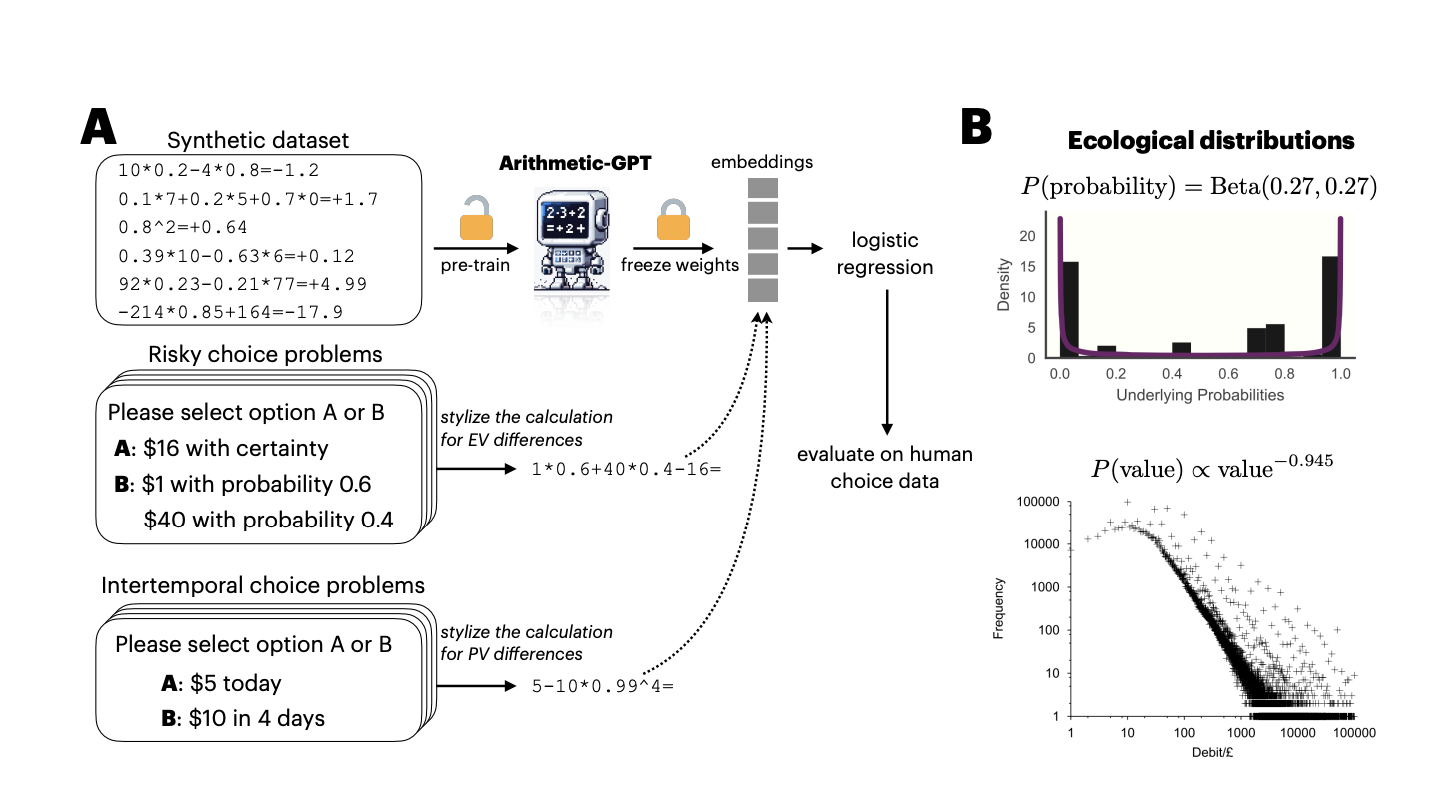
Исследователи из Принстонского и Уорикского университетов предлагают улучшение полезности LLMs в качестве когнитивных моделей путем (i) использования вычислительно эквивалентных задач, которые должны усваивать как LLMs, так и рациональные агенты для решения когнитивных проблем, и (ii) исследования распределения задач, необходимого для проявления LLMs человекоподобного поведения. Применительно к принятию решений, особенно рисковым и межвременным выборам, Arithmetic-GPT, LLM, предварительно обученная на экологически валидном арифметическом наборе данных, прогнозирует человеческое поведение лучше, чем многие традиционные когнитивные модели. Это предварительное обучение достаточно для приближения LLMs к принятию решений, близкому к человеческому.
Исследователи решают проблемы использования LLMs в качестве когнитивных моделей путем определения алгоритма генерации данных для создания синтетических наборов данных и получения доступа к нейрональным активациям, важным для принятия решений. Маленькая модель с архитектурой Generative Pretrained Transformer (GPT), названная Arithmetic-GPT, была предварительно обучена на арифметических задачах. Для обучения были созданы синтетические наборы данных, отражающие реалистичные вероятности и значения. Подробности предварительного обучения включают длину контекста 26, размер партии 2048 и скорость обучения 10⁻³. Наборы данных о человеческом принятии решений в рисковых и межвременных выборах были переанализированы для оценки производительности модели.
Экспериментальные результаты показывают, что вложения из модели Arithmetic-GPT, предварительно обученной на экологически валидных синтетических наборах данных, наиболее точно прогнозируют человеческие выборы в задачах принятия решений. Логистическая регрессия, использующая вложения в качестве независимых переменных и вероятности человеческих выборов в качестве зависимой переменной, демонстрирует более высокие скорректированные R² значения по сравнению с другими моделями, включая LLaMA-3-70bInstruct. Сравнение с моделями поведения и многослойными персептронами показывает, что вложения Arithmetic-GPT по-прежнему обеспечивают сильное соответствие с человеческими данными, особенно в задачах межвременных выборов. Надежность подтверждается 10-кратной перекрестной проверкой.
Исследование приходит к выводу, что Large Language Models, в частности Arithmetic-GPT, предварительно обученные на экологически валидных синтетических наборах данных, могут тесно моделировать человеческое когнитивное поведение в задачах принятия решений, превосходя традиционные когнитивные модели и некоторые более продвинутые LLMs, такие как LLaMA-3-70bInstruct. Этот подход решает ключевые проблемы с использованием синтетических наборов данных и нейрональных активаций. Полученные результаты подчеркивают потенциал LLMs в качестве когнитивных моделей, предоставляя ценные исследовательские данные как в когнитивной науке, так и в машинном обучении, с подтверждением надежности через обширные методы валидации.
Проверить Статью. Все права на это исследование принадлежат исследователям данного проекта. Также, не забудьте подписаться на наш твиттер. Присоединяйтесь к нашему Telegram каналу, каналу Discord и группе LinkedIn.
Если вам интересна наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему 43k+ ML SubReddit | Также, ознакомьтесь с нашей платформой AI Events.
«`

























