Продвижение этичного ИИ: Предпочтительное согласование обучения с подкреплением от обратной связи человека (RLHF) для согласования LLM с человеческими предпочтениями
Большие языковые модели (LLM), такие как ChatGPT-4 и Claude-3 Opus, отличаются в задачах, таких как генерация кода, анализ данных и рассуждения. Их растущее влияние на принятие решений в различных областях делает важным согласование их с человеческими предпочтениями для обеспечения справедливости и звучных экономических решений. Человеческие предпочтения сильно различаются из-за культурного контекста и личного опыта, и LLM часто проявляют предвзятость, выделяя доминирующие точки зрения и часто встречающиеся элементы. Если LLM не точно отражают эти разнообразные предпочтения, предвзятые выводы могут привести к несправедливым и экономически вредным результатам.
Практические решения и ценность
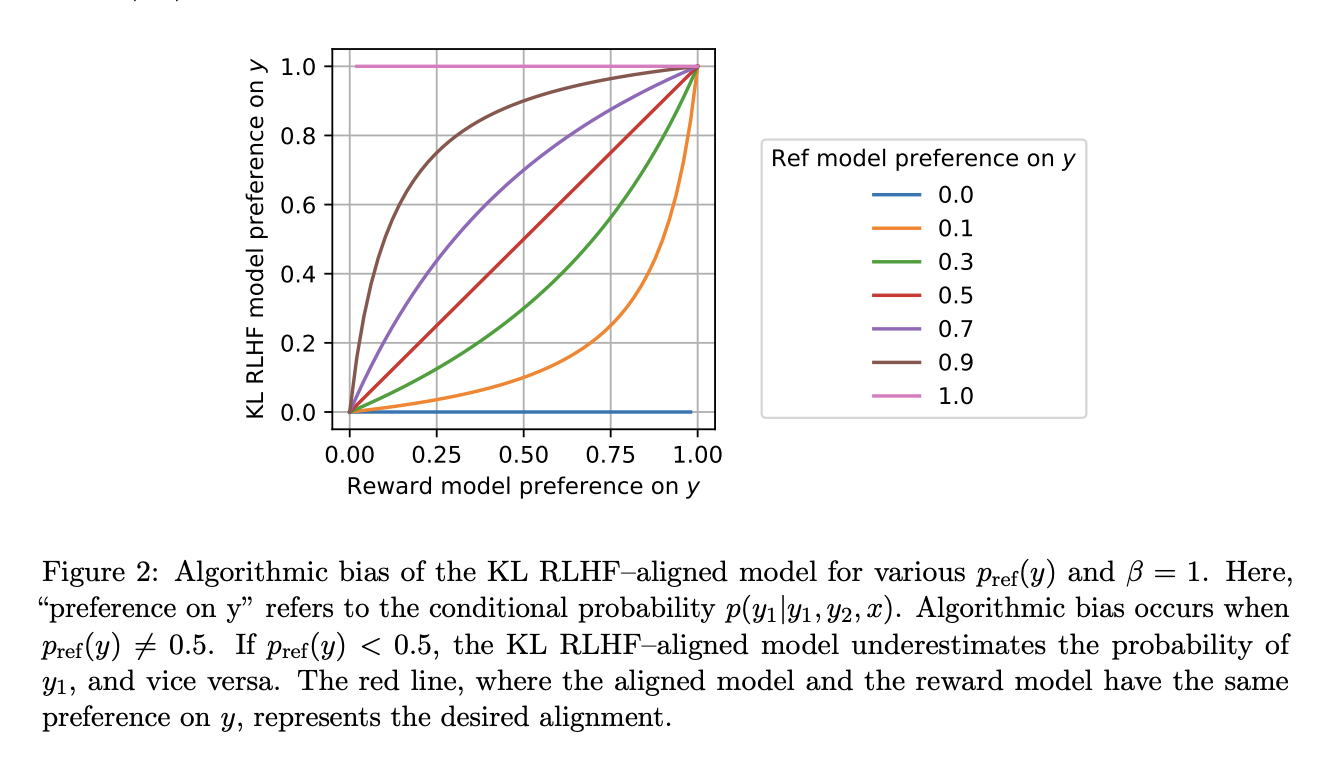
Существующие методы, особенно обучение с подкреплением от обратной связи человека (RLHF), страдают от алгоритмической предвзятости, приводя к игнорированию предпочтений меньшинства. Эта предвзятость сохраняется даже с моделью оракула вознаграждения, подчеркивая ограничения текущих подходов к точному учету разнообразных человеческих предпочтений.
Исследователи представили новаторский подход, Предпочтительное согласование RLHF, направленный на смягчение алгоритмической предвзятости и эффективное согласование LLM с человеческими предпочтениями. В основе этого инновационного метода лежит предпочтительный регуляризатор, полученный путем решения обыкновенного дифференциального уравнения. Этот регуляризатор обеспечивает баланс между диверсификацией ответов и максимизацией вознаграждения, улучшая способность модели точно учитывать и отражать человеческие предпочтения. Предпочтительное согласование RLHF обеспечивает надежные статистические гарантии и эффективно устраняет предвзятость, присущую традиционным подходам RLHF. В статье также описывается условный вариант, нацеленный на задачи генерации естественного языка, улучшая способность модели генерировать ответы, близкие к человеческим предпочтениям.
Экспериментальная проверка Предпочтительного согласования RLHF на моделях OPT-1.3B и Llama-2-7B привела к убедительным результатам, демонстрирующим значительные улучшения в согласовании LLM с человеческими предпочтениями. Метрики производительности показывают улучшение на 29% — 41% по сравнению со стандартными методами RLHF, подчеркивая способность подхода учитывать разнообразные человеческие предпочтения и смягчать алгоритмическую предвзятость. Эти результаты подчеркивают многообещающий потенциал Предпочтительного согласования RLHF в продвижении исследований в области ИИ к более этичным и эффективным процессам принятия решений.
В заключение, Предпочтительное согласование RLHF вносит значительный вклад в устранение алгоритмической предвзятости и улучшение согласования LLM с человеческими предпочтениями. Этот прогресс может улучшить процессы принятия решений, способствовать справедливости и устранить предвзятые выводы LLM, продвигая область исследований в области ИИ.

























