SciPhi Open Sourced Triplex: A SOTA LLM for Knowledge Graph Construction Provides Data Structuring with Cost-Effective and Efficient Solutions
SciPhi недавно объявила о выпуске Triplex, передовой языковой модели (LLM), специально разработанной для построения графов знаний. Этот инновационный проект с открытым исходным кодом готовит революцию в преобразовании больших объемов неструктурированных данных в структурированные форматы, существенно снижая затраты и сложность, традиционно связанные с этим процессом.
Triplex разработан для эффективного построения графов знаний, превосходящего передовые модели, такие как GPT-4o. Графы знаний необходимы для ответа на сложные запросы о взаимосвязях, например, для идентификации сотрудников компании, посещавших определенные образовательные учреждения. Однако традиционные методы построения этих графов были чрезмерно дорогими и ресурсоемкими, что ограничивало их широкое использование.
Преимущества Triplex
Triplex нацелен на изменение этой парадигмы, предлагая десятикратное снижение затрат на создание графов знаний. Это достигается за счет преобразования неструктурированного текста в «семантические тройки», основные элементы графов знаний.
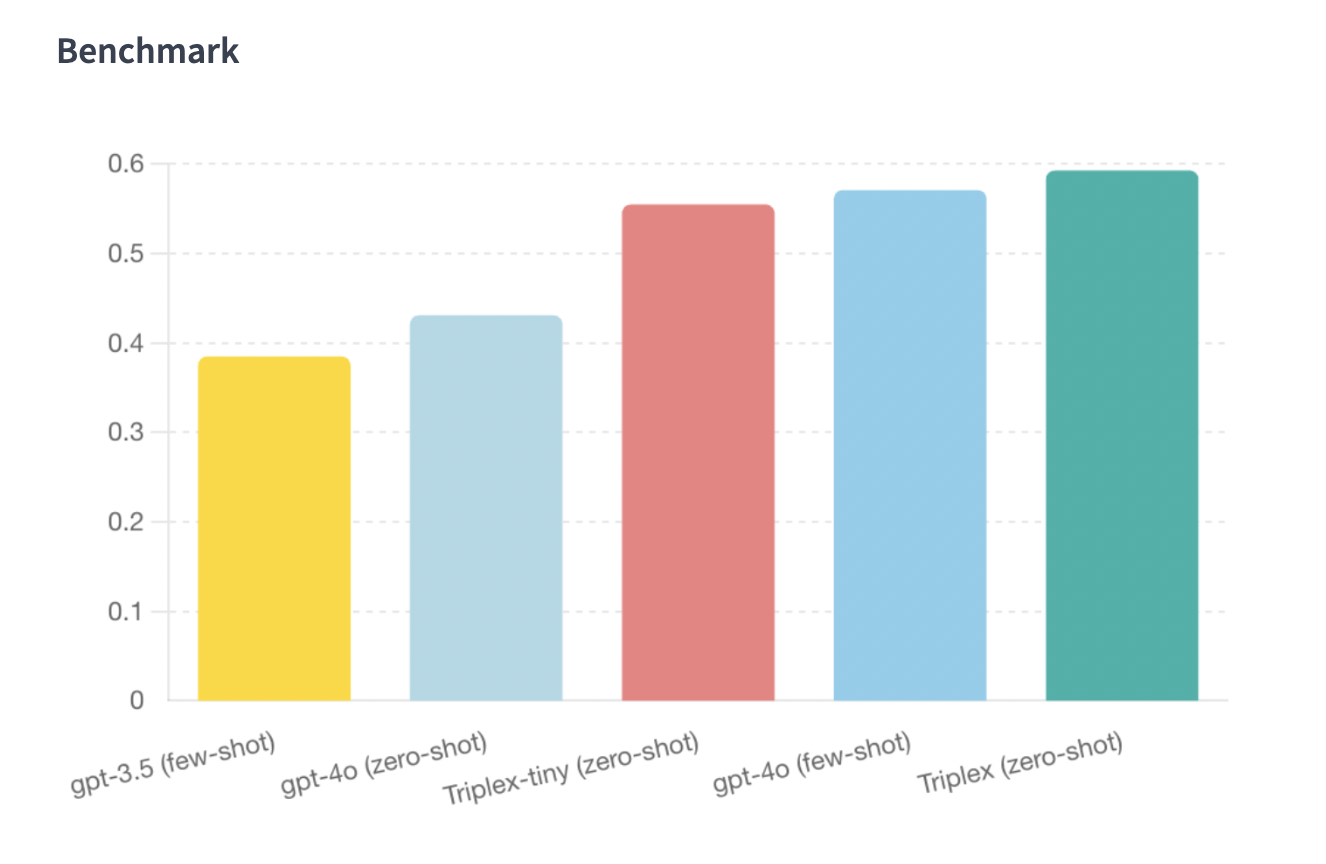
Triplex был тщательно оценен по сравнению с GPT-4o, продемонстрировав превосходную производительность как по затратам, так и по точности. Его модель извлечения троек достигает результатов, сравнимых с GPT-4o, но при доле затрат. Это замечательное снижение затрат обусловлено более компактным размером модели Triplex и способностью функционировать без обширного контекста.
Для дальнейшего повышения производительности Triplex прошел дополнительное обучение с использованием DPO (динамической оптимизации программирования) и KTO (оптимизации троек знаний). Эти шаги включали создание наборов данных на основе предпочтений путем голосования большинства и топологической сортировки. Улучшенная модель затем была оценена с использованием оценки Sonnet Claude-3.5, сравнивая Triplex с другими моделями, такими как triplex-base и triplex-kto. Результаты показали заметное преимущество Triplex, с победными показателями более 50% в прямых сравнениях с GPT-4o.
Исключительная производительность Triplex обеспечивается его обширным обучением на разнообразном и всестороннем наборе данных, включая авторитетные источники, такие как DBPedia и Wikidata, тексты веб-сайтов и синтетически сгенерированные наборы данных. Это разнообразное обучение обеспечивает универсальность и надежность Triplex в различных приложениях.
Одним из немедленных применений Triplex является локальное построение графов знаний с использованием движка R2R RAG в сочетании с Neo4J. Это применение, которое ранее было менее жизнеспособным из-за затрат и сложности, теперь становится более доступным благодаря внедрению Triplex.
В заключение, выпуск Triplex от SciPhi значительно снижает затраты и сложность преобразования неструктурированных данных в структурированные форматы; Triplex открывает новые возможности для анализа данных и генерации идей. Эта инновация обещает улучшить эффективность существующих процессов и сделать передовые техники представления данных доступными для различных приложений и отраслей.

























