«`html
Расшифровка моделей языковых трансформеров: прогресс в исследованиях интерпретируемости
Всплеск мощных языковых моделей на основе трансформеров и их широкое использование подчеркивают необходимость исследований их внутреннего устройства. Понимание этих механизмов в продвинутых системах искусственного интеллекта критично для обеспечения их безопасности, справедливости и минимизации предвзятостей и ошибок, особенно в критических контекстах. В результате наблюдается значительный рост исследований в области обработки естественного языка (NLP), нацеленных на интерпретируемость языковых моделей, что приводит к новым пониманиям их внутренних операций.
Практические решения и ценность
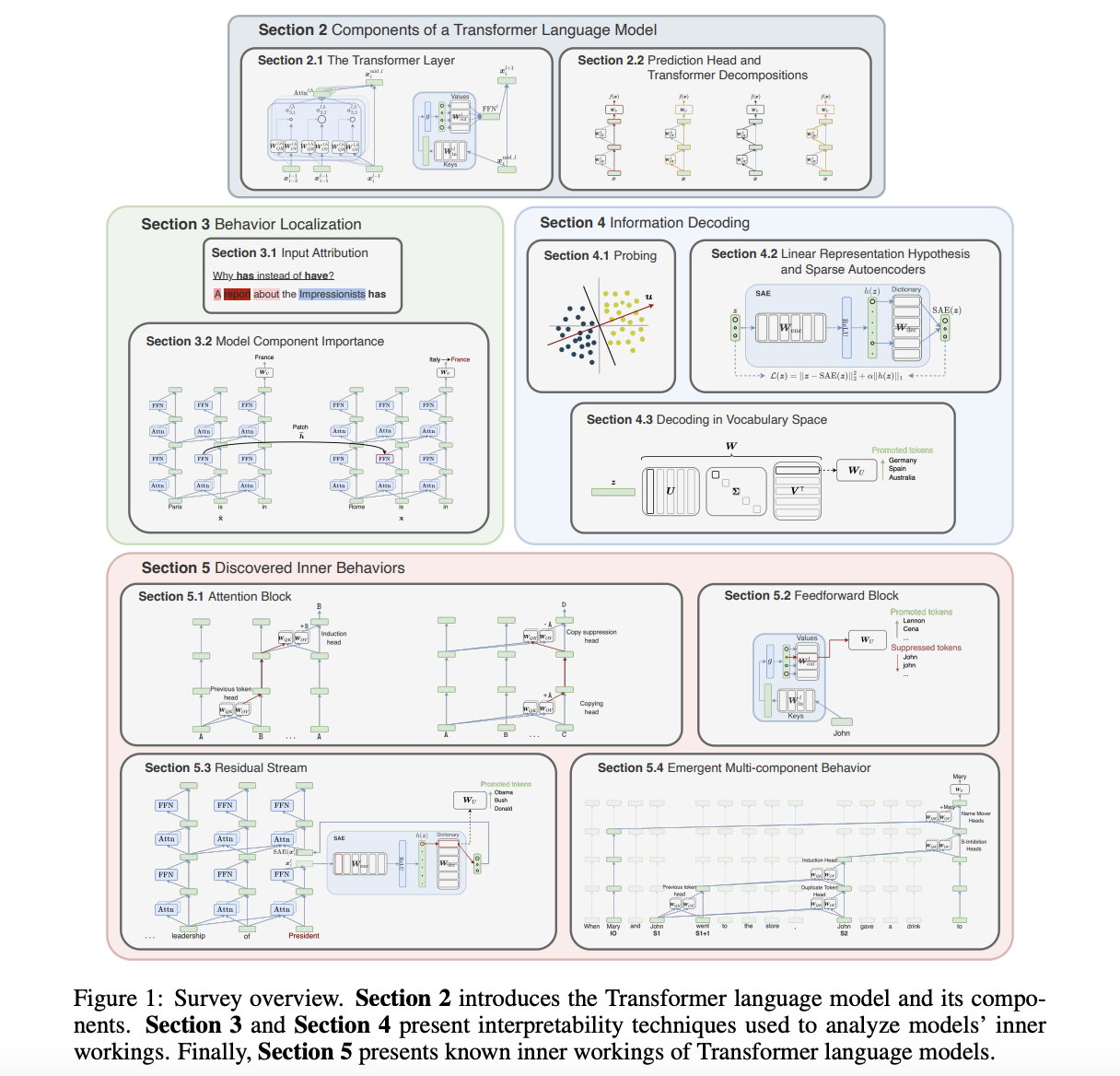
Исследователи из Universitat Politècnica de Catalunya, CLCG, University of Groningen и FAIR, Meta представляют исследование, которое предлагает технический обзор методов, применяемых в исследованиях интерпретируемости языковых моделей, подчеркивая полученные понимания внутренних операций моделей и устанавливая связи между областями исследований интерпретируемости. Используя унифицированную нотацию, они представляют компоненты модели, методы интерпретируемости и понимание, полученное из исследований, разъясняя логику за дизайном конкретных методов. Подходы интерпретируемости языковых моделей категоризированы на основе двух измерений: локализация входов или компонентов модели для прогнозов и декодирование информации в изученных представлениях. Они также предоставляют обширный список понимания работы языковых моделей на основе трансформеров и обозначают полезные инструменты для проведения анализа интерпретируемости этих моделей.
Исследователи представляют два типа методов, позволяющих локализовать поведение модели: атрибуция входа и атрибуция компонента модели. Методы атрибуции входа оценивают важность токенов с использованием градиентов или возмущений. Альтернативы смешивания контекста с весами внимания предоставляют понимание атрибуций на уровне токенов. Атрибуция логита измеряет вклад компонентов, а причинные вмешательства рассматривают вычисления как причинные модели. Анализ цепей идентифицирует взаимодействующие компоненты, с недавними достижениями в автоматизации обнаружения цепей и абстрагировании причинных отношений. Эти методы предлагают ценные понимания работы языковых моделей, помогая улучшать модель и усилия по интерпретируемости.
Они исследуют методы декодирования информации в моделях нейронных сетей, особенно в обработке естественного языка. Пробинг использует обученные модели для предсказания свойств входа из промежуточных представлений. Линейные вмешательства стирают или изменяют признаки для понимания их важности или управления выходами модели. Разреженные автокодировщики разделяют признаки в моделях с наложением, способствуя интерпретируемым представлениям. Воротные SAE улучшают обнаружение признаков в SAE. Декодирование в пространстве словаря и максимально активирующие входы предоставляют понимание поведения модели. Объяснения естественного языка от языковых моделей предлагают правдоподобные обоснования для прогнозов, но могут лишать верности внутренним механизмам модели. Они также представляют обзор нескольких библиотек с открытым исходным кодом (Captum, библиотека в экосистеме Pytorch, предоставляющая доступ к нескольким методам атрибуции входа на основе градиентов и возмущений для любой модели на основе Pytorch), которые были представлены для облегчения исследований интерпретируемости на основе трансформеров.
В заключение, это всестороннее исследование подчеркивает необходимость понимания внутренних механизмов языковых моделей на основе трансформеров для обеспечения их безопасности, справедливости и уменьшения предвзятостей. Через детальное рассмотрение методов интерпретируемости и полученных пониманий из анализа моделей, исследование значительно вносит вклад в развивающийся ландшафт интерпретируемости искусственного интеллекта. Категоризируя методы интерпретируемости и демонстрируя их практические применения, исследование продвигает понимание области и облегчает усилия по улучшению прозрачности и взаимодействия моделей.
«`
«`html
Используйте искусственный интеллект для развития вашего бизнеса
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Deciphering Transformer Language Models: Advances in Interpretability Research.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram.
Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/. Этот ИИ ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.
«`

























