Ин-контекстное обучение многослойных перцептронов (MLP): сравнительное исследование с трансформерами
В последние годы произошли значительные прорывы в области нейронных языковых моделей, в частности больших языковых моделей (LLM), возможность которых предоставлена архитектурой Transformer и увеличением масштабов. LLM обладают исключительными навыками в генерации грамотного текста, ответах на вопросы, кратком изложении содержания, создании оригинальных выводов и решении сложных головоломок. Ключевая способность — это возможность контекстного обучения (ICL), когда модель использует новые образцы задач, представленные во время вывода, для точного реагирования без обновления весов. ICL обычно причисляется к трансформерам и их механизмам на основе внимания.
Практические решения и ценность
Ин-контекстное обучение (ICL) признано для задач линейной регрессии с трансформерами, которые могут обобщаться на новые пары входных данных/меток в контексте. Трансформеры достигают этого, потенциально реализуя градиентный спуск или воспроизведение регрессии по методу наименьших квадратов. Трансформеры интерполируют между обучением весов внутри контекста и контекстным обучением, а разнообразные наборы данных улучшают возможности контекстного обучения. Пока большинство исследований сосредотачивается на трансформерах, некоторые из них исследуют рекуррентные нейронные сети (RNN) и LSTM, но смешанные результаты. Недавние находки подчеркивают, что различные причинные последовательностные модели и модели пространства состояний также достигают контекстного обучения. Тем не менее, потенциал многослойных перцептронов (MLP) для контекстного обучения остается недостаточно исследованным, несмотря на их возрождение в сложных задачах благодаря появлению модели MLP-Mixer.
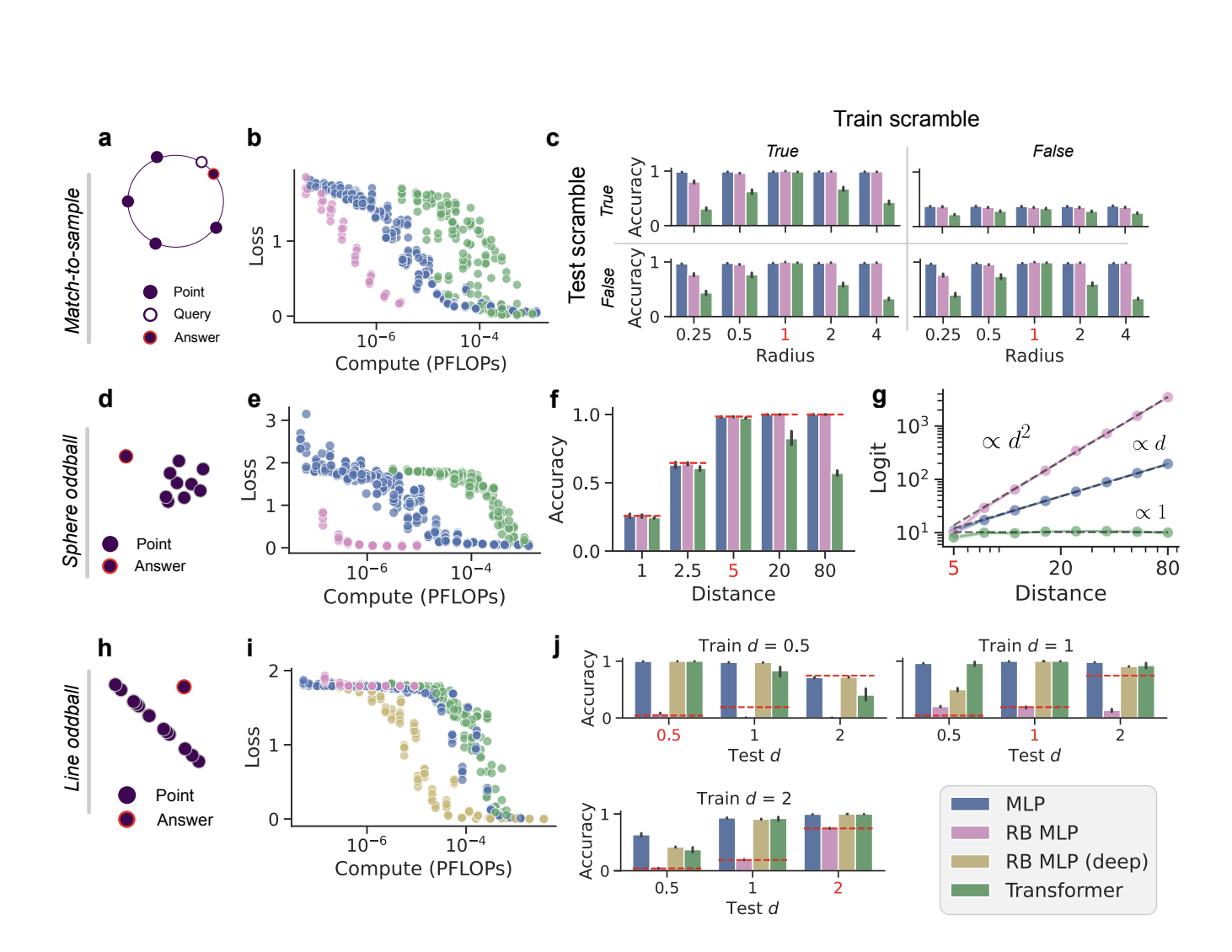
В данном исследовании ученые из Гарварда демонстрируют, что многослойные перцептроны (MLP) могут эффективно обучаться в контексте. MLP и модели MLP-Mixer по сравнению с трансформерами показывают конкурентоспособные результаты на задачах контекстного обучения в рамках одного и того же вычислительного бюджета. В частности, MLP превосходят трансформеры в задачах реляционного рассуждения в контексте, что вызывает сомнения в том, что контекстное обучение уникально для трансформеров. Этот успех предполагает, что стоит изучать не только архитектуры на основе внимания, и указывает на то, что трансформеры, ограниченные самовниманием и позиционным кодированием, могут быть предвзяты в отношении определенных структур задач по сравнению с MLP.
Исследование рассматривает поведение MLP в контексте двух задач: контекстной регрессии и контекстной классификации. Для контекстной регрессии входом является последовательность линейно связанных пар значений (xi, yi), с различными весами β и добавленным шумом, плюс запрос xq. Модель предсказывает соответствующий yq, выведя β из контекстных образцов. Для контекстной классификации входом является последовательность образцов (xi, yi), за которыми следует запрос xq, выбранный из смеси гауссовых моделей. Модель предсказывает правильную метку для xq, опираясь на контекстные образцы и учитывая разнообразие данных и всплески (количество повторов в кластере в контексте).
MLP и трансформеры были сравнены по контекстной регрессии и классификации. Обе архитектуры, включая MLP-Mixer, достигли практически оптимальной среднеквадратичной ошибки (MSE) при достаточных вычислениях, хотя трансформеры незначительно превзошли MLP при более ограниченных вычислительных бюджетах. При увеличении длины контекста ванильные MLP показали худшие результаты, в то время как MLP-Mixer поддержали оптимальную MSE. При увеличении разнообразия данных все модели переключились с обучения весам внутри контекста на контекстное обучение, и трансформеры сделали это быстрее. В контекстной классификации MLP проявили себя сопоставимо с трансформерами, поддерживая относительно прямую потерю с увеличением длины контекста и переходя от обучения весам внутри контекста к контекстному обучению при увеличении разнообразия данных.
В данной работе ученые Гарварда сравнили MLP и трансформеры на контекстных задачах регрессии и классификации. Все архитектуры, включая MLP-Mixer, достигли практически оптимальной среднеквадратичной ошибки при достаточных ресурсах, хотя трансформеры незначительно превзошли MLP при меньших ресурсах. Ванильные MLP показали худшие результаты с увеличением длины контекста, в то время как MLP-Mixer поддержали оптимальную MSE. При увеличении разнообразия данных все модели переходили от обучения весам внутри контекста к контекстному обучению, при этом трансформеры делали это быстрее. В контекстной классификации MLP показали сопоставимую производительность с трансформерами, поддерживая плоскую потерю с увеличением длины контекста и переходя на контекстное обучение с увеличением разнообразия данных.