«`html
Развитие надежной системы вопросов и ответов с помощью бенчмарка CRAG
Большие языковые модели (LLM) революционизировали обработку естественного языка (NLP), особенно в области вопросно-ответных систем (QA). Однако галлюцинации остаются значительным препятствием, так как LLM могут генерировать фактически неверные или необоснованные ответы. Исследования показывают, что даже передовые модели, такие как GPT-4, испытывают трудности с точным ответом на вопросы, касающиеся изменяющихся фактов или менее популярных сущностей. Преодоление галлюцинаций критически важно для развития надежных систем QA. Retrieval-Augmented Generation (RAG) появился как многообещающий подход к устранению недостатков знаний у LLM, но он сталкивается с проблемами, такими как выбор соответствующей информации, снижение задержки и синтез информации для сложных запросов.
Оценка CRAG
Исследователи из Meta Reality Labs, FAIR, Meta, HKUST и HKUST (GZ) предложили бенчмарк под названием CRAG (Comprehensive benchmark for RAG), который направлен на включение пяти критических характеристик: реализм, насыщенность, информативность, надежность и долговечность. Он содержит 4 409 разнообразных пар вопрос-ответ из пяти областей, включая простые фактологические и семь типов сложных вопросов. CRAG охватывает различную популярность сущностей и временные промежутки для получения информации. Вопросы проверены вручную и перефразированы для достижения реализма и надежности. Кроме того, CRAG предоставляет мокрые API, имитирующие извлечение информации с веб-страниц (через Brave Search API) и мокрые графы знаний с 2,6 миллионами сущностей, отражающие реалистичный шум. Бенчмарк предлагает три задачи для оценки возможностей RAG в области извлечения информации из веба, структурированных запросов и суммирования.
Задачи RAG QA системы
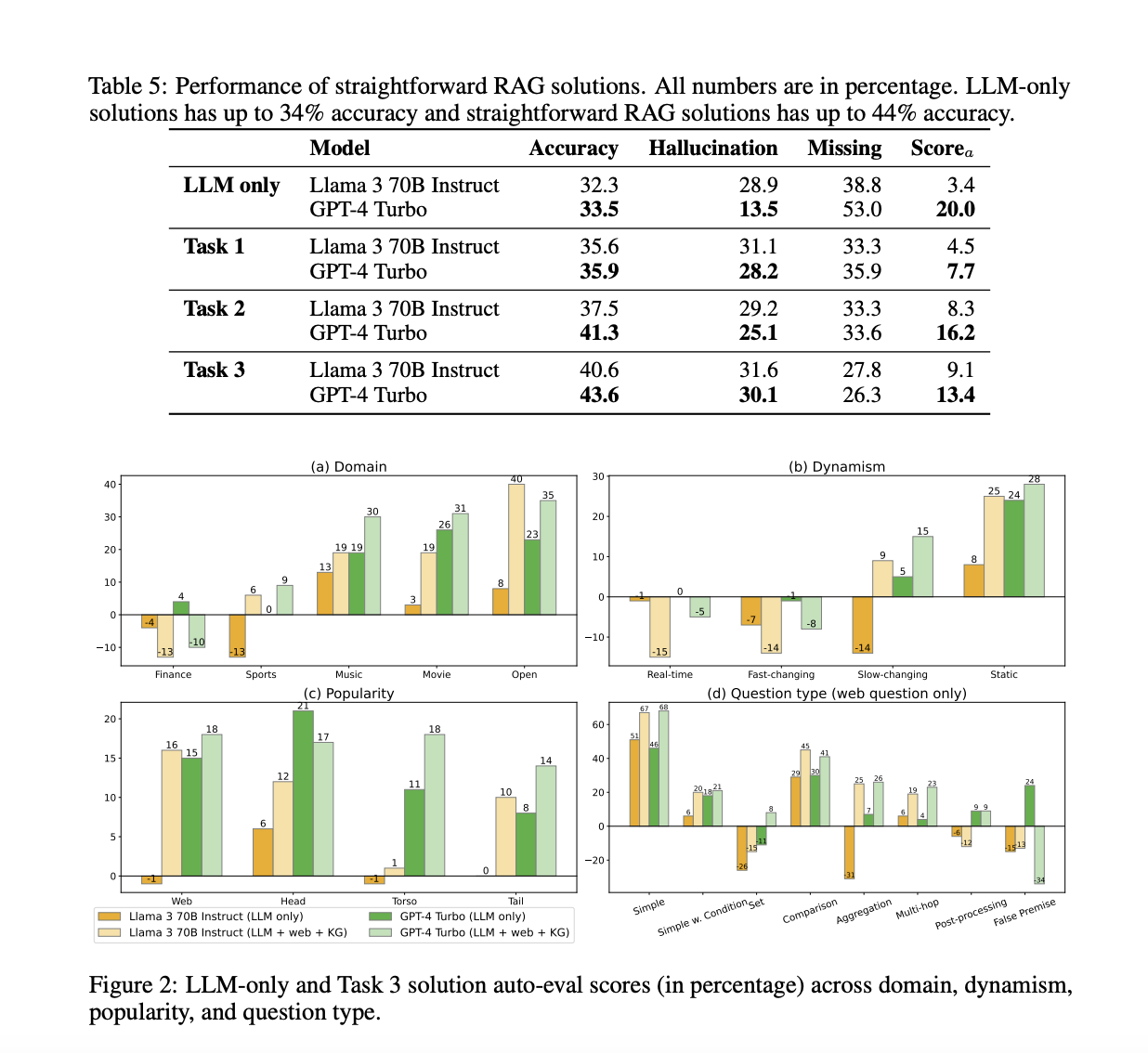
Система RAG QA включает три задачи, разработанные для оценки различных возможностей систем. Все задачи разделяют одинаковый набор пар (вопрос, ответ), но отличаются в доступных внешних данных для извлечения информации для генерации ответа. Задача 1 (Извлечение суммирования) предоставляет до пяти потенциально соответствующих веб-страниц для каждого вопроса, чтобы проверить возможность генерации ответа. Задача 2 (KG и извлечение информации из веба) дополнительно предоставляет мокрые API для доступа к структурированным данным из графов знаний (KG), проверяя способность системы к запросу структурированных источников и синтезу информации. Задача 3 похожа на Задачу 2, но предоставляет 50 веб-страниц вместо 5 в качестве кандидатов для извлечения, проверяя способность системы ранжировать и использовать более обширный, но потенциально шумный набор информации.
Результаты и сравнения
Результаты и сравнения демонстрируют эффективность предложенного бенчмарка CRAG. В то время как передовые языковые модели, такие как GPT-4, достигают лишь около 34% точности на CRAG, внедрение простого RAG повышает точность до 44%. Однако даже передовые отраслевые решения RAG отвечают только на 63% вопросов без галлюцинаций, испытывая трудности с фактами более динамичными, менее популярными или более сложными. Эти оценки подчеркивают, что CRAG имеет подходящий уровень сложности и позволяет получать понимание из его разнообразных данных. Оценки также указывают на научные пробелы в развитии полностью надежных систем вопросов и ответов, делая CRAG ценным бенчмарком для дальнейшего прогресса в этой области.
Заключение
В данном исследовании исследователи представляют CRAG, обширный бенчмарк, который направлен на продвижение исследований в области RAG для систем вопросов и ответов. Через тщательные эмпирические оценки CRAG выявляет недостатки существующих решений RAG и предлагает ценные идеи для будущих улучшений. Создатели бенчмарка планируют непрерывно улучшать и расширять CRAG, чтобы включить многоязычные вопросы, мульти-модальные входы, многоходовые разговоры и многое другое. Это непрерывное развитие обеспечивает, что CRAG остается на передовой в развитии исследований в области RAG, адаптируясь к новым вызовам и эволюционируя для решения новых научных потребностей в этой быстро развивающейся области. Бенчмарк предоставляет прочную основу для развития надежных, обоснованных возможностей генерации языка.
«`

























