«`html
Улучшение эффективности обучения с подкреплением с использованием стохастических методов
Обучение с подкреплением (RL) представляет собой специализированную область машинного обучения, в которой агенты обучаются принимать решения взаимодействуя с окружающей средой. Это включает в себя выполнение действий и получение обратной связи через вознаграждения или штрафы. RL сыграло важную роль в разработке передовых робототехники, автономных транспортных средств, технологий для стратегических игр и решении сложных проблем в различных научных и промышленных областях.
Основные проблемы в RL
Одной из значительных проблем RL является управление сложностью окружающей среды с большими дискретными пространствами действий. Традиционные методы RL, такие как Q-обучение, включают вычислительно затратный процесс оценки стоимости всех возможных действий на каждом этапе принятия решения. Этот исчерпывающий процесс поиска становится все более непрактичным по мере увеличения числа действий, что приводит к существенным неэффективностям и ограничениям в реальных приложениях, где быстрое и эффективное принятие решений критически важно.
Инновационные стохастические методы RL
Исследователи из KAUST и Purdue University представили инновационные стохастические методы RL, такие как Стохастическое Q-обучение, StochDQN и StochDDQN, которые используют стохастические методы максимизации. Эти методы значительно снижают вычислительную нагрузку, рассматривая только подмножество возможных действий на каждой итерации. Такой подход позволяет создавать масштабируемые решения, которые более эффективно обрабатывают большие дискретные пространства действий.
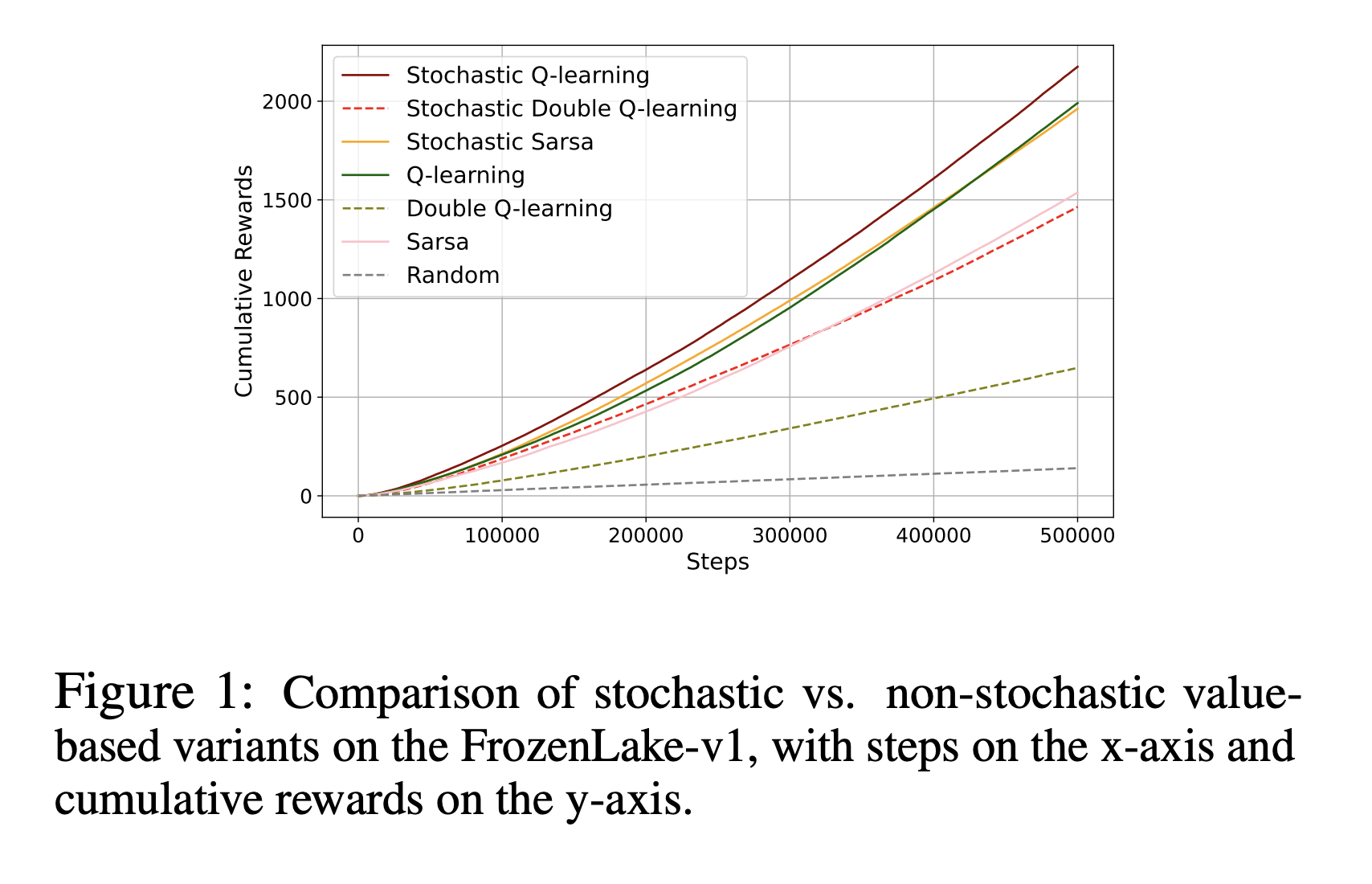
Эффективность стохастических методов
Результаты исследований показывают, что стохастические методы значительно улучшают производительность и эффективность. В проверочных средах, таких как FrozenLake-v1 и задачах управления MuJoCo, таких как InvertedPendulum-v4 и HalfCheetah-v4, стохастические методы достигли более быстрой сходимости и высокой эффективности по сравнению с традиционными методами.
Заключение
Исследование представляет стохастические методы для улучшения эффективности RL в больших дискретных пространствах действий. Путем внедрения стохастической максимизации методы значительно снижают вычислительную сложность, сохраняя при этом высокую производительность. Эти методы показали свою эффективность в различных средах, достигая более быстрой сходимости и высокой эффективности по сравнению с традиционными подходами.
«`

























