Применение Self-Route: эффективный метод ИИ для маршрутизации запросов к RAG или LC на основе самоотражения модели
Large Language Models (LLMs) революционизировали область обработки естественного языка, позволяя машинам понимать и генерировать человеческий язык. Модели, такие как GPT-4 и Gemini-1.5, являются ключевыми для обширных приложений обработки текста, включая суммирование и ответы на вопросы. Однако управление длинными контекстами остается сложной задачей из-за вычислительных ограничений и увеличенных затрат. Исследователи, поэтому, ищут инновационные подходы для балансировки производительности и эффективности.
Вызовы при работе с длинными контекстами и их решение
Значительным вызовом в обработке длинных текстов является вычислительная нагрузка и связанные с ней затраты. Традиционные методы часто нуждаются в улучшениях при работе с длинными контекстами, что требует новых стратегий для эффективного решения этой проблемы. Этот вопрос требует методологий, которые балансируют высокую производительность с экономичностью. Один из перспективных подходов – Retrieval Augmented Generation (RAG), который извлекает соответствующую информацию на основе запроса и подталкивает LLMs к генерации ответов в этом контексте. RAG значительно расширяет способность модели экономично получать доступ к информации.
Исследователи из Google DeepMind и Университета Мичигана представили новый метод под названием SELF-ROUTE. Этот метод объединяет преимущества RAG и LLMs с длинными контекстами для эффективной маршрутизации запросов, используя саморефлексию модели для принятия решения о том, использовать ли RAG или LLM в зависимости от характера запроса. Метод SELF-ROUTE работает в два этапа. Сначала запрос и извлеченные фрагменты предоставляются LLM для определения, является ли запрос ответным. Если запрос считается ответным, используется сгенерированный RAG-ответ. В противном случае LLM получает полный контекст для более полного ответа. Такой подход значительно снижает вычислительные затраты, сохраняя при этом высокую производительность и эффективно используя преимущества как RAG, так и LLM.
Оценка SELF-ROUTE и результаты исследования
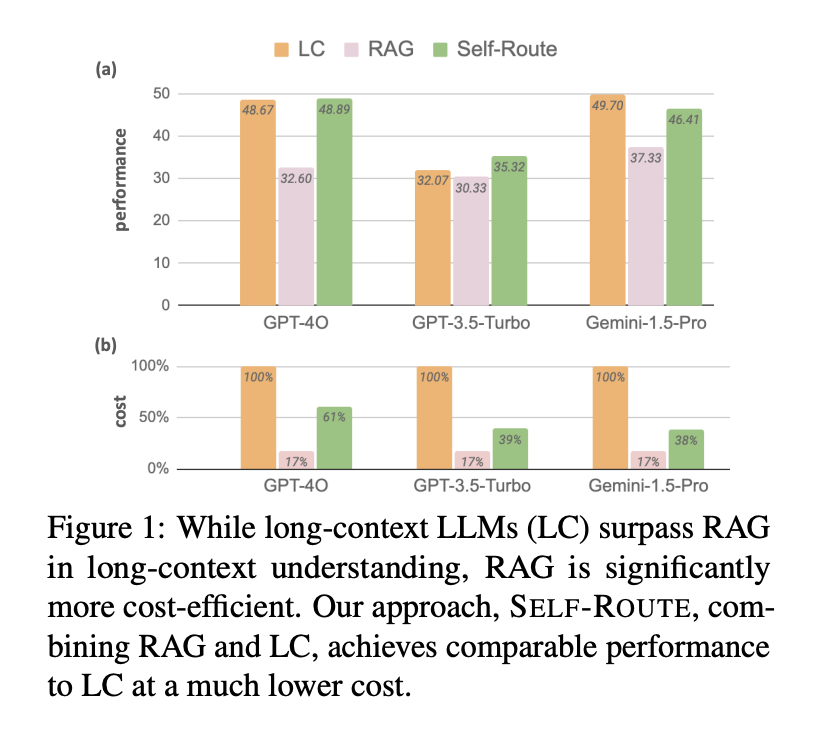
Оценка SELF-ROUTE включала три недавние LLMs: Gemini-1.5-Pro, GPT-4 и GPT-3.5-Turbo. Исследование сравнивало эти модели, используя наборы данных LongBench и u221eBench, сосредотачиваясь на задачах на основе запросов на английском языке. Результаты показали, что LLM-модели последовательно превосходили RAG в понимании длинных контекстов. Например, LLM превзошел RAG на 7,6% для Gemini-1.5-Pro, 13,1% для GPT-4 и 3,6% для GPT-3.5-Turbo. Однако экономичность RAG остается значительным преимуществом, особенно когда входной текст значительно превышает размер окна контекста модели.
SELF-ROUTE добился значительного снижения затрат, сохраняя сопоставимую производительность по сравнению с LLM-моделями. Например, затраты были снижены на 65% для Gemini-1.5-Pro и на 39% для GPT-4. Метод также показал высокую степень совпадения прогнозов между RAG и LLM, причем 63% запросов имели идентичные прогнозы, а 70% показали разницу в баллах менее 10. Это совпадение показывает, что RAG и LLM часто делают аналогичные прогнозы, как правильные, так и неправильные, позволяя SELF-ROUTE использовать RAG для большинства запросов и оставлять LLM для более сложных случаев.
Подробный анализ производительности показал, что в среднем LLM-модели превосходили RAG на значительные величины: 7,6% для Gemini-1.5-Pro, 13,1% для GPT-4 и 3,6% для GPT-3.5-Turbo. Интересно, что для наборов данных с крайне длинными контекстами, таких как в u221eBench, RAG иногда показывал более высокую производительность, чем LLM, особенно для GPT-3.5-Turbo. Это обнаружение подчеркивает эффективность RAG в конкретных случаях использования, когда входной текст превышает размер окна контекста модели.
Исследование также изучило различные наборы данных, чтобы понять ограничения RAG. Общие причины неудач включали требования к многошаговому рассуждению, общие или неявные запросы и длинные, сложные запросы, которые представляют вызов для извлекателя. Анализируя эти шаблоны неудач, исследовательская группа выявила потенциальные области для улучшения в RAG, такие как включение процессов цепочки мыслей и улучшение техник понимания запросов.
Выводы
В заключение, комплексное сравнение моделей RAG и LLM подчеркивает компромиссы между производительностью и вычислительной стоимостью в LLM с длинными контекстами. В то время как LLM-модели демонстрируют превосходную производительность, RAG остается целесообразным из-за своих более низких затрат и специфических преимуществ в обработке обширных входных текстов. Метод SELF-ROUTE эффективно объединяет преимущества как RAG, так и LLM, достигая производительности, сопоставимой с LLM, при значительно сниженных затратах.
Для развития вашего бизнеса с применением искусственного интеллекта обращайтесь к нам. Мы поможем вам определить потенциальные области внедрения автоматизации, подобрать подходящее решение и постепенно внедрять ИИ для улучшения процессов и результатов.
Кроме того, мы предлагаем использовать ИИ ассистента в продажах, который поможет вам в общении с клиентами, генерации контента и снижении нагрузки на ваш персонал.
Присоединяйтесь к нам на Telegram, чтобы получать советы по внедрению ИИ и быть в курсе всех наших обновлений и мероприятий.
Мы в компании Flycode.ru рады помочь вам использовать потенциал искусственного интеллекта для развития вашего бизнеса.









