Улучшение обучения агентов с помощью DIAMOND в сфере искусственного интеллекта
Обучение с подкреплением (RL) основано на том, что агенты учатся принимать решения, взаимодействуя с окружающей средой. RL достиг впечатляющих результатов в играх, робототехнике и автономных системах. Цель — разработать алгоритмы, позволяющие агентам эффективно выполнять задачи, максимизируя накопленные вознаграждения через пробно-ошибочные взаимодействия. Путем непрерывной адаптации к новым данным эти алгоритмы помогают улучшить производительность со временем, делая RL важным компонентом в разработке интеллектуальных систем.
Преодоление проблемы неэффективности выборки
Одной из значительных проблем RL является неэффективность выборки, когда агенты требуют обширного взаимодействия с окружающей средой для изучения эффективных стратегий. Это ограничение затрудняет практическое применение RL в реальных сценариях, особенно в средах, где получение образцов затратно или занимает много времени. Решение этой проблемы критично для внедрения RL в практические приложения, такие как автономное вождение и роботизированная автоматизация, где реальное тестирование может быть дорогим и затратным по времени.
Практические решения и ценность
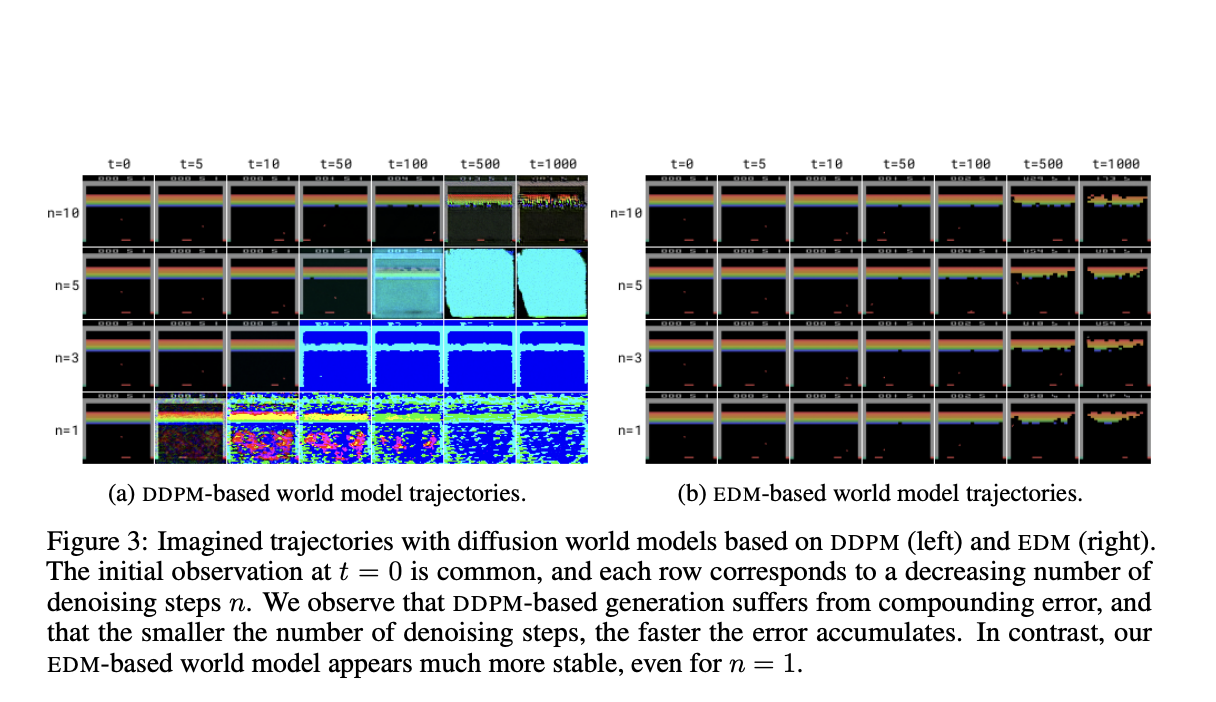
Исследования включают в себя различные модели мира, такие как SimPLe, Dreamer, TWM, STORM и IRIS, которые обучают агентов RL в симулированных средах. Однако исследователи из Университета Женевы, Университета Эдинбурга и Microsoft Research представили DIAMOND — нового агента RL, обученного с использованием модели мира на основе диффузии. DIAMOND использует преимущества моделей диффузии, которые являются важными в генерации изображений высокого разрешения. Интеграция этих моделей в моделирование мира направлена на сохранение визуальных деталей, часто теряющихся в традиционных методах, тем самым улучшая достоверность симулированных сред и общего процесса обучения.
Оценка производительности DIAMOND
Производительность DIAMOND оценивается на бенчмарке Atari 100k, где он достигает среднего человеко-нормализованного показателя в 1,46, устанавливая новый стандарт для агентов, обученных исключительно в модели мира. DIAMOND превосходит другие агенты, обученные на основе моделей мира, демонстрируя значительно лучшую способность к обучению и адаптации в сложных средах.
В заключение, DIAMOND представляет собой значительное достижение в области RL, решая проблему неэффективности выборки через улучшенное моделирование мира. Инновационный подход имеет потенциал революционизировать обучение агентов RL, делая их более эффективными и способными к работе в сложных реальных средах.

























