EM-LLM: Новая и гибкая архитектура, интегрирующая ключевые аспекты человеческой эпизодической памяти и когнитивных событий в языковые модели на основе трансформера
Большие языковые модели (LLM) сталкиваются с ограничениями в обработке обширных контекстов из-за архитектур на основе трансформера, которые испытывают трудности в экстраполяции за пределы размера окна обучения. Однако исследователи из Huawei Noah’s Ark Lab и University College London предлагают уникальную архитектуру EM-LLM, которая интегрирует эпизодическую память в LLM на основе трансформера, позволяя им обрабатывать значительно более длинные контексты.
Практические решения и ценность
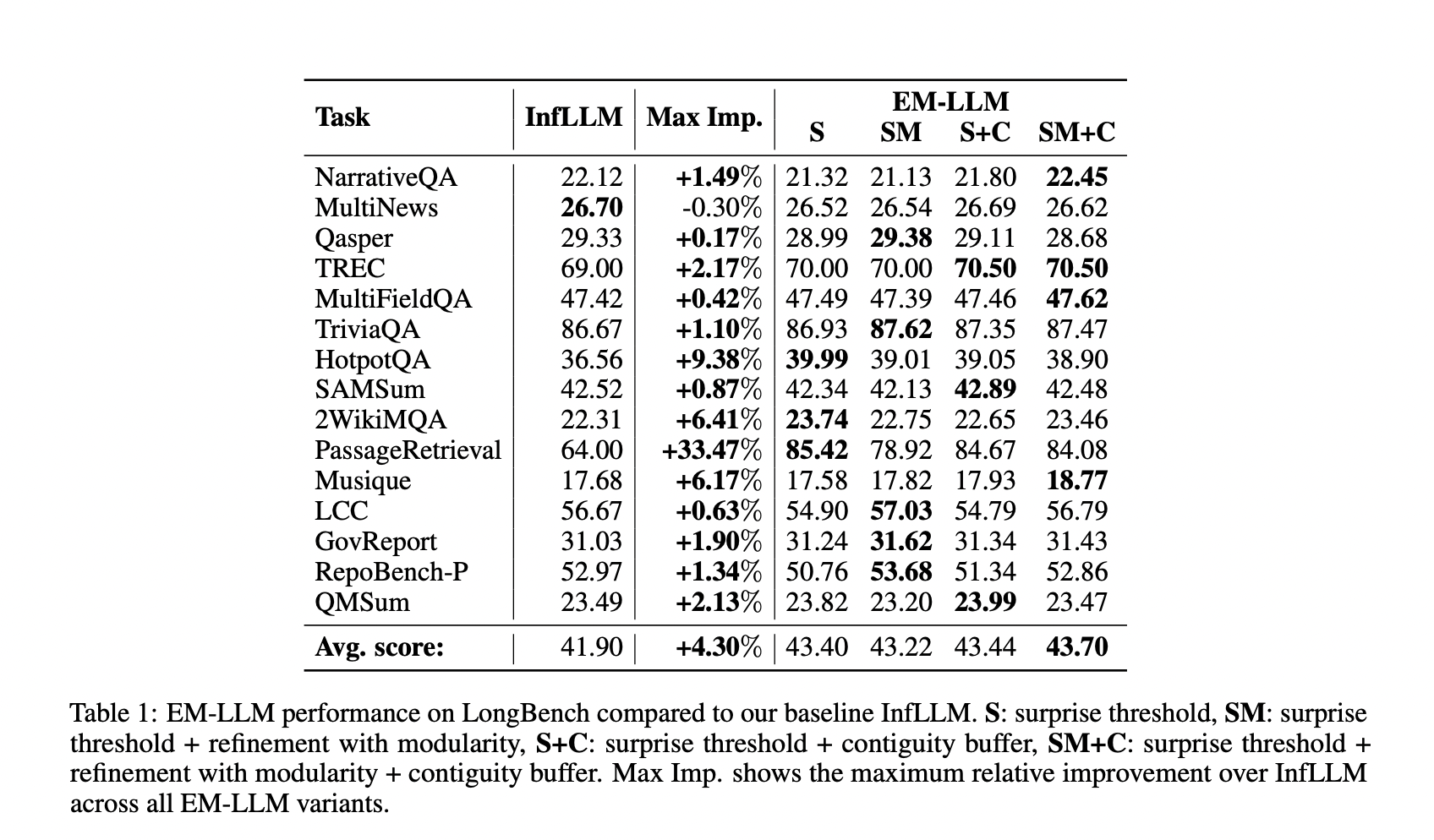
EM-LLM расширяет возможности предварительно обученных LLM для обработки более длинных контекстов, что позволяет модели обрабатывать информацию за пределами предварительно обученного окна контекста, сохраняя при этом характеристики производительности. Архитектура EM-LLM демонстрирует улучшенную производительность на задачах с длинным контекстом по сравнению с базовой моделью InfLLM. На датасете LongBench EM-LLM превзошел InfLLM во всех, кроме одной задачи, достигнув общего увеличения на 1,8 процентных пункта (4,3% относительного улучшения).
EM-LLM представляет значительное развитие в языковых моделях с расширенными возможностями обработки контекста. Интеграция человеческой эпизодической памяти и когнитивных событий в LLM на основе трансформера позволяет эффективно обрабатывать информацию из значительно расширенных контекстов без предварительного обучения. Архитектура EM-LLM предлагает путь к практически бесконечным окнам контекста, потенциально революционизируя взаимодействие LLM с непрерывными персонализированными обменами.

























