«`html
Глубокое обучение и его применение в науке
Глубокое обучение показало впечатляющие успехи в различных научных областях, демонстрируя свой потенциал во множестве приложений. Однако модели глубокого обучения часто имеют большое количество параметров, требующих значительных вычислительных мощностей для обучения и тестирования. Исследователи ищут методы оптимизации этих моделей с целью уменьшения их размера без ущерба для производительности. Одной из ключевых областей исследований является разреженность в нейронных сетях, поскольку она предлагает способ повысить эффективность и управляемость этих моделей. Фокусируясь на разреженности, исследователи стремятся создать нейронные сети, которые будут одновременно мощными и ресурсоэффективными.
Проблемы и оптимизация нейронных сетей
Одной из основных проблем нейронных сетей является высокая вычислительная мощность и использование памяти из-за большого количества параметров. Традиционные методы сжатия, такие как обрезка, помогают уменьшить размер модели путем удаления части весов на основе заранее определенных критериев. Однако эти методы часто не достигают оптимальной эффективности из-за сохранения нулевых весов в памяти, что ограничивает потенциальные преимущества разреженности. Эта неэффективность подчеркивает необходимость по-настоящему разреженных реализаций, которые могут полностью оптимизировать память и вычислительные ресурсы, тем самым решая ограничения традиционных методов сжатия.
Методы реализации разреженных нейронных сетей
Методы реализации разреженных нейронных сетей основаны на бинарных масках для обеспечения разреженности. Однако эти маски только частично используют преимущества разреженных вычислений, поскольку нулевые веса все равно сохраняются в памяти и передаются через вычисления. Техники, такие как Динамическое Разреженное Обучение, которое корректирует топологию сети во время обучения, все еще зависят от плотных матричных операций. Библиотеки, такие как PyTorch и Keras, поддерживают разреженные модели в определенной степени, однако их реализации не достигают реального снижения потребления памяти и времени вычислений из-за зависимости от бинарных масок. В результате полный потенциал разреженных нейронных сетей все еще нуждается в исследовании.
Библиотека Nerva и ее преимущества
Исследователи Технического университета Эйндховена представили Nerva — новую библиотеку нейронных сетей на C++, разработанную для обеспечения по-настоящему разреженной реализации. Nerva использует библиотеку математических функций Intel (MKL) для разреженных матричных операций, устраняя необходимость в бинарных масках и оптимизируя время обучения и использование памяти. Эта библиотека поддерживает интерфейс Python, что делает ее доступной для исследователей, знакомых с популярными фреймворками, такими как PyTorch и Keras. Дизайн Nerva фокусируется на эффективности времени выполнения, эффективности использования памяти, энергоэффективности и доступности, обеспечивая эффективное удовлетворение потребностей научного сообщества.
Преимущества библиотеки Nerva
Nerva использует разреженные матричные операции для значительного снижения вычислительной нагрузки, связанной с нейронными сетями. В отличие от традиционных методов, сохраняющих нулевые веса, Nerva хранит только ненулевые элементы, что приводит к существенной экономии памяти. Библиотека оптимизирована для производительности ЦП, с планами поддержки операций на ГПУ в будущем. Основные операции с разреженными матрицами реализованы эффективно, обеспечивая возможность Nerva обрабатывать модели большого масштаба при сохранении высокой производительности. Например, при умножении разреженных матриц вычисляются только значения для ненулевых элементов, что позволяет избежать сохранения полных плотных произведений в памяти.
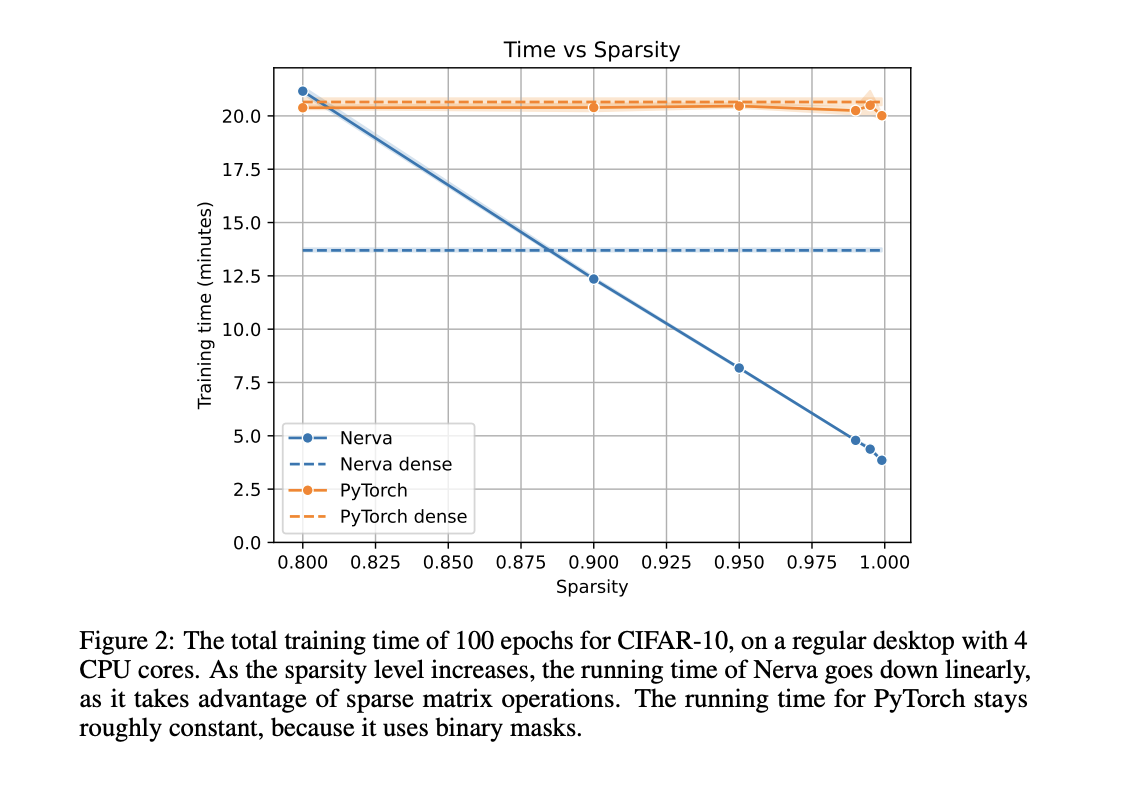
Эффективность Nerva и сравнение с PyTorch
Эффективность Nerva была оценена на примере использования набора данных CIFAR-10 в сравнении с PyTorch. Nerva продемонстрировала линейное снижение времени выполнения с увеличением уровня разреженности, превзойдя PyTorch в режимах высокой разреженности. Например, при уровне разреженности 99% Nerva сократила время выполнения в четыре раза по сравнению с моделью PyTorch, использующей маски. Nerva достигла сопоставимой точности с PyTorch, существенно сокращая время обучения и вывода. Использование памяти также было оптимизировано, и наблюдалось сокращение в 49 раз для моделей с разреженностью 99% по сравнению с полностью плотными моделями. Эти результаты подчеркивают способность Nerva обеспечивать эффективное обучение разреженных нейронных сетей без ущерба для производительности.
Заключение
Введение Nerva предоставляет по-настоящему разреженную реализацию, решает неэффективности традиционных методов и предлагает существенные улучшения во времени выполнения и использовании памяти. Исследование показало, что Nerva может достичь сопоставимой точности с фреймворками, такими как PyTorch, обеспечивая более эффективную работу, особенно в условиях высокой разреженности. С продолжающимся развитием и планами поддержки динамического разреженного обучения и операций на ГПУ, Nerva готова стать ценным инструментом для исследователей, стремящихся оптимизировать модели нейронных сетей.
«`

























