“`html
Consistency Large Language Models (CLLMs): Новое семейство LLM, специализированное для метода декодирования Якоби для снижения задержки
Большие языковые модели (LLM), включая GPT-4, LLaMA и PaLM, выталкивают границы искусственного интеллекта. Задержка вывода LLM играет важную роль из-за интеграции LLM в различные приложения, обеспечивая положительный опыт пользователя и высокое качество обслуживания. Однако служба LLM работает в рамках AR-парадигмы, генерируя по одному токену за раз, потому что механизм внимания полагается на предыдущие состояния токенов для генерации следующего токена. Чтобы создать более длинный ответ, выполняется прямой проход, используя LLM, эквивалентный количеству сгенерированных токенов, что приводит к высокой задержке.
Эффективный метод вывода LLM
Эффективный метод вывода LLM разделен на два потока: метод, требующий дополнительной тренировки, и метод, не требующий ее. Исследователи изучили этот метод из-за высокой стоимости вывода AR для LLM, в основном сосредоточившись на увеличении процесса декодирования AR. Еще один существующий метод – это Дистилляция LLM, где используется техника дистилляции знаний (KD) для создания маленьких моделей и замены функциональности более крупных. Однако традиционные методы KD неэффективны для LLM. Поэтому KD используется для авторегрессивных LLM для минимизации обратного KL-расхождения между студенческими и учительскими моделями через декодирование, управляемое студентом.
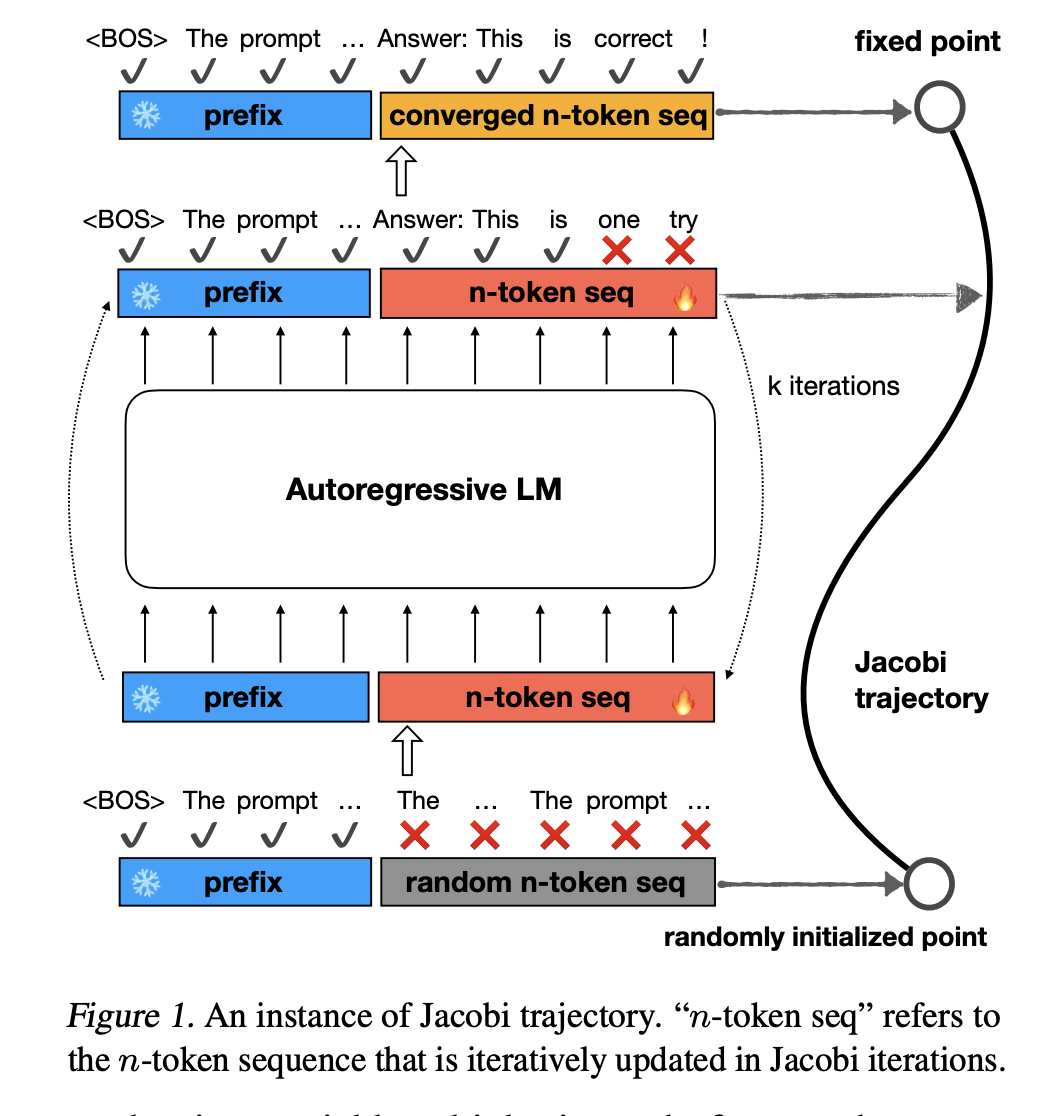
Consistency Large Language Models (CLLMs)
Исследователи из университета Шанхая Джиао и университета Калифорнии предложили CLLMs, новое семейство LLM, специализированное для метода декодирования Якоби для снижения задержки. CLLM был сравнен с традиционными методами, такими как спекулятивное декодирование и Медуза, для настройки вспомогательных компонентов модели и не использовал дополнительную память для этой задачи, в отличие от других. Когда CLLM обучается на ∼ 1M токенов для LLaMA-7B, он становится в 3,4 раза быстрее на наборе данных Spider, что показывает, что стоимость настройки для этого метода умеренная. Два основных фактора для ускорения – быстрое декодирование и стационарные токены.
В быстром декодировании правильные предсказания делаются в один проход для нескольких последовательных токенов, тогда как стационарные токены показывают правильное предсказание без изменений через последующие итерации, несмотря на то, что они предшествуют неточным токенам. В LLM и CLLM, когда сравниваются количество быстрых и стационарных токенов на всех четырех наборах данных (в Таблице 3), улучшение количества токенов составляет от 2,0x до 6,8x. Также для обоих количеств токенов такое улучшение в наборах данных, специфичных для домена, лучше, чем в наборах данных общего профиля на MT-bench. Это помогает выделить коллокации и простые синтаксические структуры, такие как пробелы, токены новой строки и повторяющиеся специальные символы в специализированных областях, таких как программирование.
Исследователи провели эксперименты для оценки производительности и ускорения вывода CLLM на нескольких задачах, таких как сравнение базовых уровней (SOTA) на трех специфических для домена задачах и задачах общего профиля на MT-bench. CLLM показывает выдающуюся производительность на различных бенчмарках, например, он может достичь ускорения в 2,4× до 3,4× с использованием декодирования Якоби с практически никакой потерей точности на специфических для домена бенчмарках, таких как GSM8K, CodeSearchNet Python и Spider. CLLM может достичь ускорения в 2,4× на ShareGPT с производительностью SOTA, с оценкой 6,4 на общедоступном бенчмарке MT-bench.
Заключение
Исследователи представили CLLM, новое семейство LLM, которое отличается эффективным параллельным декодированием и разработано таким образом, что может улучшить эффективность декодирования Якоби. Дополнительные архитектурные решения или управление двумя различными моделями в одной системе сложны, и сложность снижается с помощью CLLM, потому что этот метод прямо адаптирован из целевой предварительно обученной LLM. Кроме того, количество быстрых и стационарных токенов сравниваются на четырех наборах данных, показывая улучшение от 2,0x до 6,8x в LLM и CLLM.
Посмотрите статью и проект. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу Telegram, каналу Discord и группе LinkedIn.
Если вам понравилась наша работа, вам понравится наш информационный бюллетень.
Не забудьте присоединиться к нашему 42k+ ML SubReddit
Оригинал статьи опубликован на сайте MarkTechPost.
“`









