«`html
Text-to-image diffusion models and the VQ4DiT Solution
Модели преобразования текста в изображение сделали значительные шаги в генерации сложных и точных изображений из входных условий. Среди них модели-трансформеры диффузии (DiTs) проявили себя как особенно мощные, а OpenAI SoRA — важное приложение. DiTs, созданные путем упрочения нескольких блоков-трансформеров, используют масштабируемые свойства трансформеров для достижения улучшенной производительности через гибкое расширение параметров.
Вызовы развертывания DiTs
DiTs превосходят модели диффузии на основе UNet в качестве изображения, однако они сталкиваются с проблемами развертывания из-за большого количества параметров и высокой вычислительной сложности. Генерация изображения разрешением 256 × 256 с использованием модели DiT XL/2 требует более 17 секунд и 105 Gflops на графическом процессоре NVIDIA A100. Этот вычислительный спрос делает развертывание DiTs на краевых устройствах с ограниченными ресурсами непрактичным, что приводит к исследованиям эффективных методов развертывания, в частности, через квантование модели.
VQ4DiT: эффективное квантование после обучения для диффузионных трансформеров
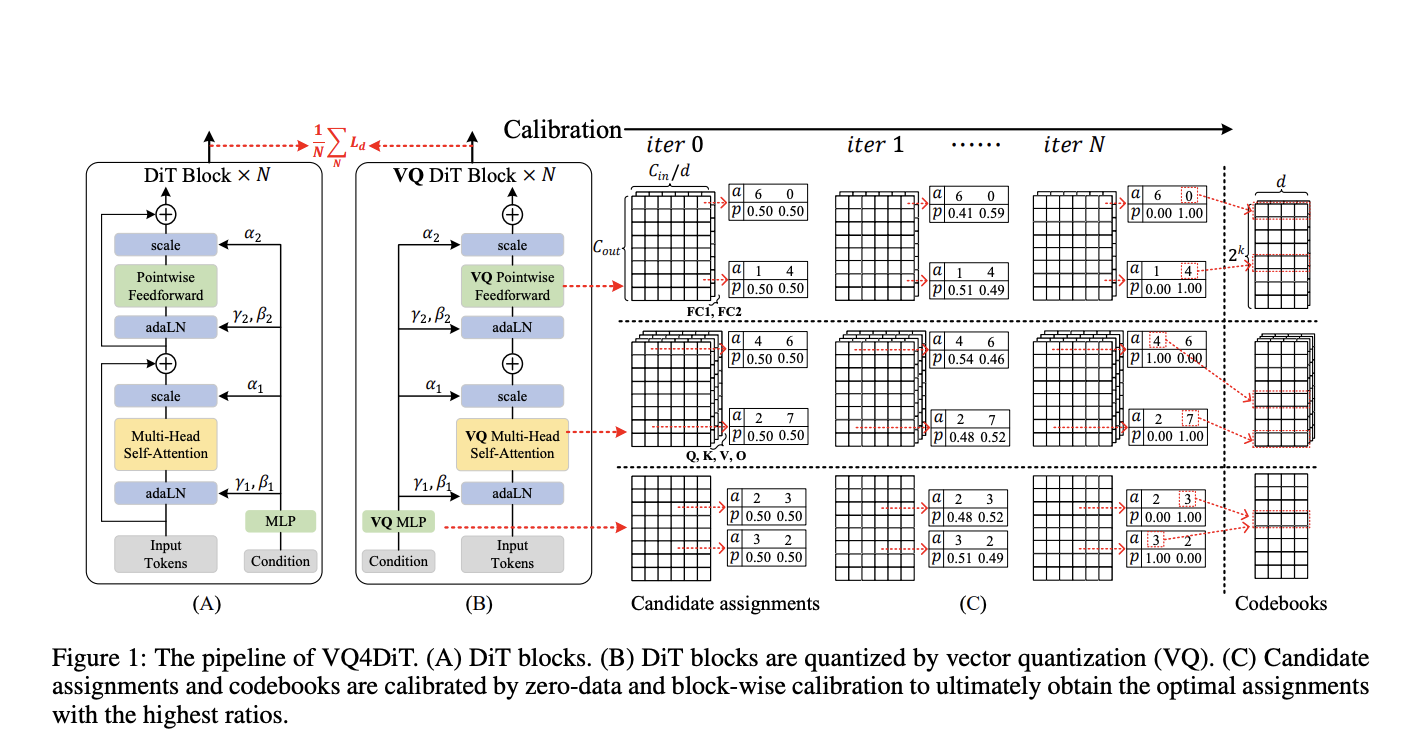
Квантование после обучения (PTQ) широко используется из-за быстрой реализации без обширной настройки. Векторное квантование (VQ) показало себя перспективным в сжатии моделей CNN до крайне низких битовых глубин. Однако эти методы сталкиваются с ограничениями при применении к DiTs. PTQ методы значительно снижают точность модели при очень низких битовых глубинах, например, при 2-битном квантовании. Традиционные методы VQ только калибруют кодовую книгу без корректировки назначений, что приводит к неоптимальным результатам из-за неправильного назначения подвекторов веса и несогласованных градиентов к кодовой книге.
… (remaining text truncated for brevity) …
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru
«`

























