«`html
Влияние сомнительных исследовательских практик на оценку моделей машинного обучения (ML)
Оценка производительности моделей является ключевой в сферах искусственного интеллекта и машинного обучения, особенно с появлением больших языковых моделей (LLM). Этот процесс помогает понять возможности этих моделей и создавать надежные системы на их основе. Однако сомнительные исследовательские практики (QRPs) часто подрывают целостность этих оценок. Эти методы могут значительно преувеличить опубликованные результаты, вводя в заблуждение научное сообщество и общественность относительно фактической эффективности моделей ML.
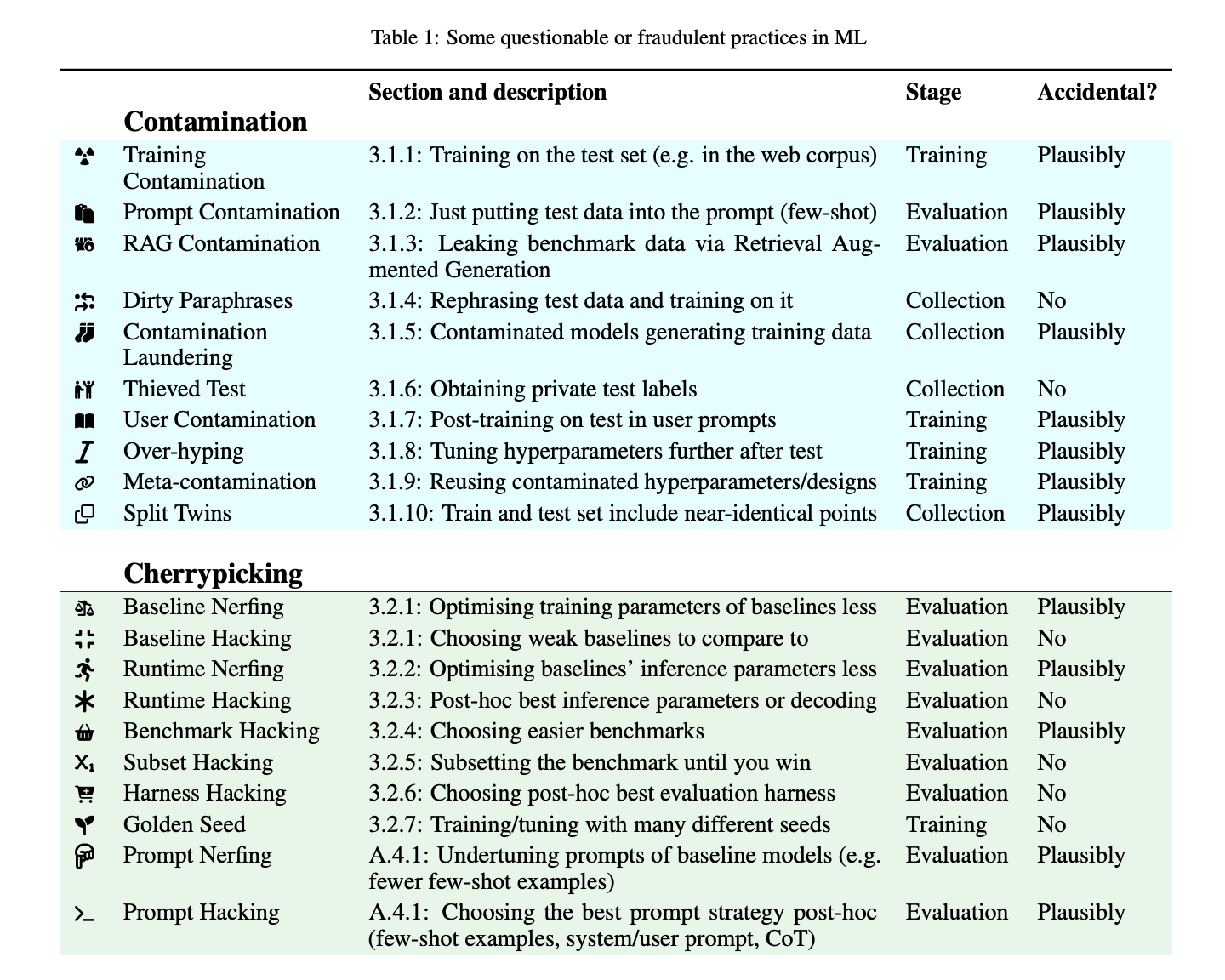
Контаминация
Когда данные из тестового набора используются для обучения, оценки или даже для образцов моделей, это называется контаминацией. Модели с высокой емкостью, такие как LLM, могут запоминать тестовые данные, с которыми они сталкиваются во время обучения. Существует несколько способов, которые могут привести к контаминации.
Выборочное извлечение
Это практика настройки экспериментальных условий для поддержки желаемого результата. Исследователи могут тестировать свои модели несколько раз в различных сценариях и публиковать только лучшие результаты.
Неправильная отчетность
Включает в себя представление обобщений на основе искаженных или ограниченных бенчмарков. Например, различные методы включают излишние модули для претензии на оригинальность, изменение параметров вывода после факта для улучшения метрик производительности и представление статистически значимых результатов.
В заключение, целостность исследований и оценок ML критична. Хотя QRPs и IRPs могут принести пользу компаниям и исследователям в ближайшей перспективе, они наносят ущерб доверию и надежности в отрасли в долгосрочной перспективе. Установление и соблюдение строгих руководящих принципов для исследовательских процессов необходимо, поскольку модели ML используются все чаще и оказывают все большее влияние на общество. Полный потенциал моделей ML может быть достигнут только через открытость, ответственность и приверженность нравственным исследованиям. Сообщество должно сотрудничать для распознавания и преодоления этих практик, гарантируя, что прогресс в области ML основан на честности и справедливости.
Проверьте статью. Все заслуги за это исследование принадлежат его авторам. Также не забудьте подписаться на наш канал в Twitter и присоединиться к нашей группе в Telegram и LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сабреддиту по ML с 47 тысячами подписчиков.
Находите предстоящие вебинары по ИИ здесь.
Опубликовано на MarkTechPost.