Мониторинг измененного ИИ-контента в масштабе: влияние ChatGPT на рецензии на конференциях по искусственному интеллекту
Большие языковые модели (LLM) широко обсуждались в различных областях, таких как мировые СМИ, наука и образование. Однако измерить точное количество использования LLM или оценить влияние созданного текста на информационные экосистемы все еще сложно. Одной из основных проблем является растущая сложность различения текстов, созданных LLM, от текстов, написанных людьми. Существует вероятность того, что неподдерживаемый ИИ-сгенерированный язык может быть воспринят как надежное, основанное на фактах письмо, поскольку исследования показали, что способность людей отличить ИИ-сгенерированный контент от человеческих текстов едва лучше случайного угадывания.
Практические решения и ценность:
Для преодоления этих проблем необходимы эффективные методики оценки вывода LLM в более широком масштабе. Одним из предложенных методов является подход «квантификация распределения GPT», который рассчитывает процент ИИ-сгенерированного контента в корпусе без анализа отдельных примеров. Этот метод значительно снижает ошибки оценки по сравнению с существующими техниками обнаружения ИИ-текстов и является более вычислительно эффективным.
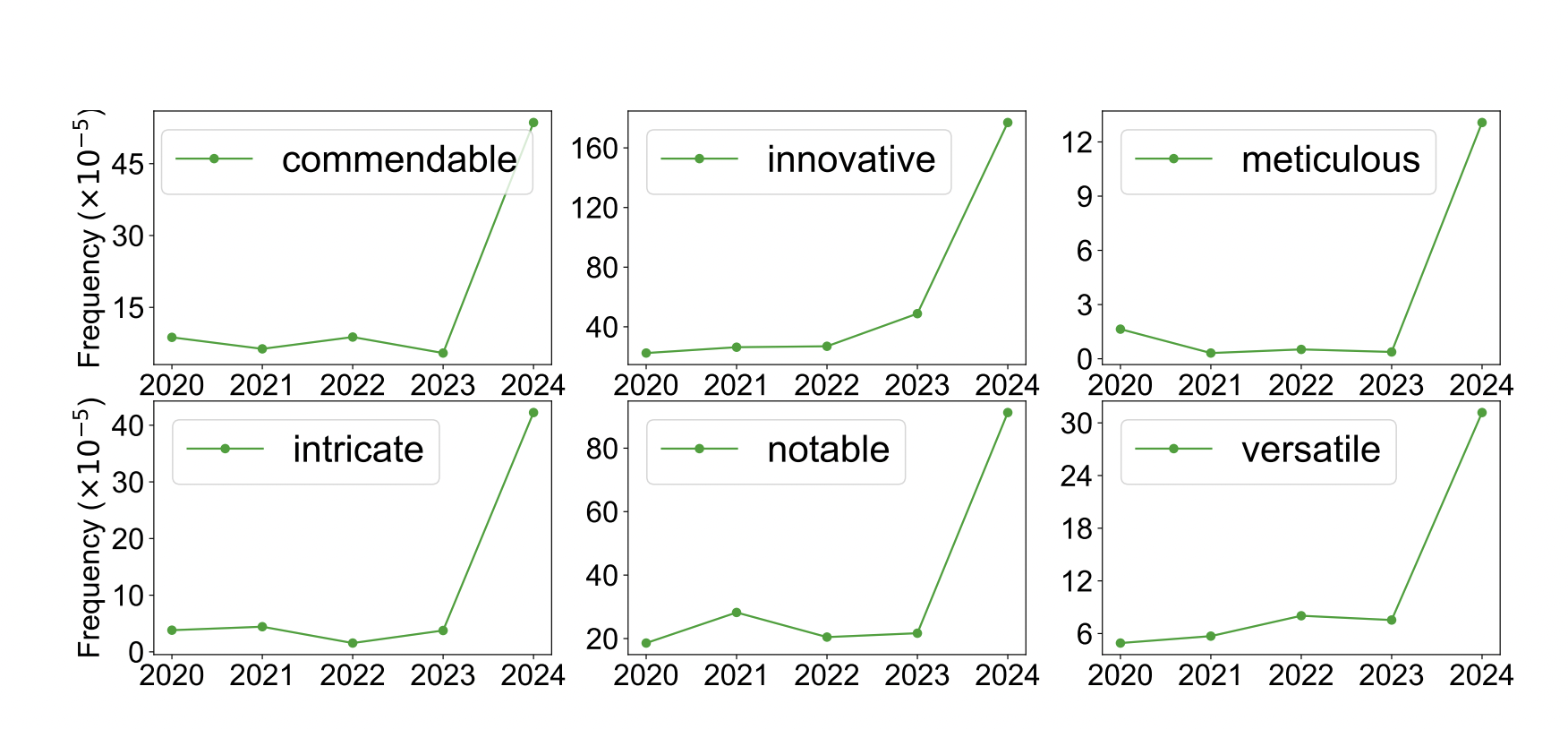
Эмпирические исследования показывают, что в ИИ-сгенерированных текстах некоторые прилагательные используются чаще, чем в текстах, созданных людьми, что позволяет исследователям производить последовательные и заметные результаты, параметризуя свою модель для распределения вероятностей.
Команда исследователей из Стэнфорда предложила простой и эффективный способ рассчитать процент текста в большом наборе данных, который был значительно изменен или создан с помощью ИИ. Этот подход использует исторические данные, созданные ИИ или написанные специалистами, и использует метод максимального правдоподобия для оценки процента ИИ-сгенерированного текста в целевом корпусе, используя эти данные.
В заключение, исследование предлагает новую парадигму для эффективного отслеживания материалов, измененных ИИ, в информационных экосистемах, подчеркивая важность оценки и анализа вывода LLM в целом для выявления незначительных, но длительных эффектов ИИ-сгенерированного языка.

























