Многоязычные приложения и задачи
Сегодня многоязычные приложения и кросс-языковые задачи играют ключевую роль в обработке естественного языка (NLP). Для этого необходимы надежные модели встраивания. Эти модели поддерживают системы, такие как генерация с дополнением поиска и другие решения на основе ИИ. Однако существующие модели часто сталкиваются с проблемами, связанными с шумными данными, ограниченной разнообразностью доменов и неэффективностью управления многоязычными наборами данных.
Решение: KaLM-Embedding
Исследователи из Харбинского технологического института (Шэньчжэнь) разработали KaLM-Embedding, модель, которая акцентирует внимание на качестве данных и инновационных методах обучения. Эта многоязычная модель встраивания основана на Qwen 2-0.5B и выпущена под лицензией MIT. Она компактна и эффективна, что делает ее особенно подходящей для реальных приложений с ограниченными вычислительными ресурсами.
Ключевые особенности и преимущества
KaLM-Embedding включает передовые методологии для создания мощных многоязычных текстовых встраиваний. Одной из заметных особенностей является обучение представлению «Матрешка», которое поддерживает гибкие размеры встраивания от 64 до 896 измерений. Это позволяет оптимизировать встраивания для различных приложений.
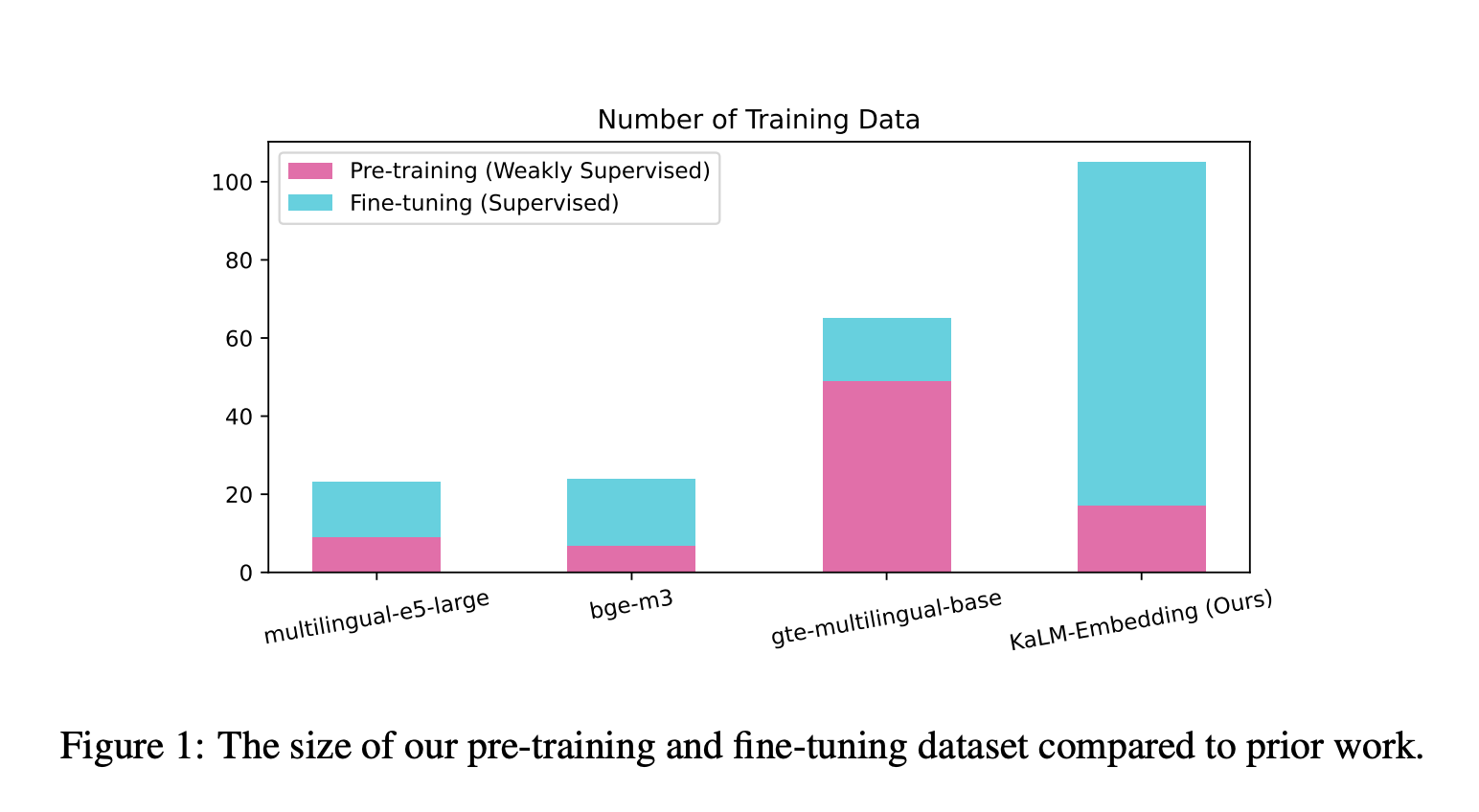
Стратегия обучения состоит из двух этапов: слабонаправленного предварительного обучения и направленной дообучения. В процессе дообучения использовалось более 70 разнообразных наборов данных, охватывающих различные языки и домены.
Производительность и результаты
Производительность KaLM-Embedding была оценена на Massive Text Embedding Benchmark (MTEB), где она достигла среднего балла 64.53. Это высокий стандарт для моделей с менее чем 1 миллиардом параметров. Модель продемонстрировала сильные способности к обобщению, несмотря на ограниченные данные для некоторых языков.
Заключение: Прогресс в многоязычных встраиваниях
KaLM-Embedding представляет собой значительный шаг вперед в области многоязычных моделей встраивания. Она решает проблемы, такие как шумные данные и негибкие архитектуры, достигая баланса между эффективностью и производительностью. Открытый исходный код под лицензией MIT приглашает исследователей и практиков изучать и развивать эту работу.
Как использовать ИИ для вашего бизнеса
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, следуйте этим шагам:
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите, где возможно применение автоматизации.
- Установите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Подберите подходящее решение, учитывая множество доступных вариантов ИИ.
- Внедряйте ИИ решения постепенно, начиная с малого проекта.
- На основе полученных данных и опыта расширяйте автоматизацию.
Получите советы по внедрению ИИ
Если вам нужны советы по внедрению ИИ, пишите нам.
Попробуйте ИИ ассистент в продажах
Этот ИИ ассистент помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы
Изучите решения от Flycode.ru и откройте новые возможности для вашего бизнеса.

























