«`html
Решение проблемы многоязычного информационного поиска с помощью Jina-ColBERT-v2
В последнее время область информационного поиска (IR) стремительно развивается, особенно с интеграцией нейронных сетей. Однако, с увеличением спроса на многоязычные приложения становится все более сложной задача обеспечить производительность и эффективность в обработке различных языков. В этой связи разработка моделей, которые не только устойчивы и точны, но также эффективны в работе с масштабными и разнообразными наборами данных без необходимости обширных вычислительных ресурсов, становится важной.
Ограничения существующих моделей и ввод новой разработки
Традиционные одновекторные модели сталкиваются с проблемой обобщения на различные языки, что делает их менее эффективными в многоязычных средах. Мультивекторные модели, такие как ColBERT, предлагают решение, позволяя более детально взаимодействовать между токенами, что улучшает точность поиска. Однако такие модели требуют значительных ресурсов, что ограничивает их применимость. Для решения этих проблем исследователи из Университета Техаса в Остине и Jina AI GmbH создали Jina-ColBERT-v2, модель, обладающую значительными улучшениями в эффективной обработке многоязычных данных. Она сокращает потребности в хранении до 50% по сравнению с предыдущими моделями, сохраняя при этом высокую производительность при различных задачах на английском и многоязычных языках.
Технологические инновации и результаты тестирования
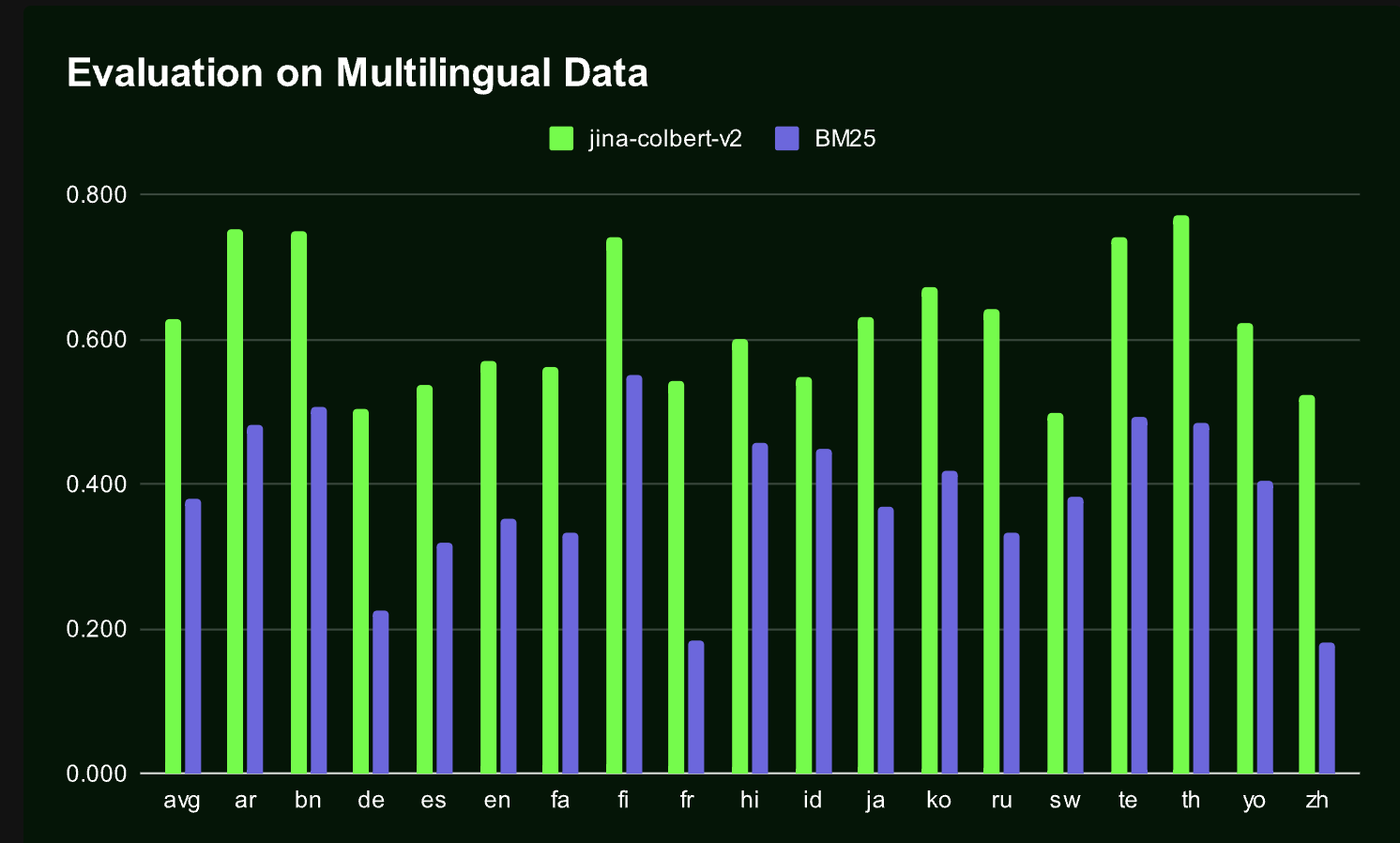
Jina-ColBERT-v2 представляет собой смесь нескольких передовых техник для улучшения эффективности и эффективности информационного поиска. Одним из ключевых достижений является использование нескольких линейных проекционных головок во время обучения, позволяющее модели выбирать различные размеры токенов во время вывода с минимальной потерей производительности. Это достигается благодаря Matryoshka Representation Loss, который позволяет модели поддерживать производительность даже при уменьшении размерности токенов. Благодаря технологическим инновациям модель Jina-ColBERT-v2 обладает большей эффективностью в обработке многоязычных данных и становится более эффективной в плане хранения и вычислений.
Результаты тестирования показывают, что Jina-ColBERT-v2 демонстрирует свою эффективность как в англоязычных, так и в многоязычных средах, превзойдя существующие модели в нескольких языках, включая арабский, китайский и испанский. Ее способность обеспечивать высокую точность поиска при снижении потребности в хранении на 50% делает эту модель значительным прорывом в информационном поиске.
Применение модели в бизнесе и образовании
Модель Jina-ColBERT-v2 представляет собой мощное и эффективное решение, которое обещает стать ключевым инструментом для мультиязычной обработки данных, обладая потенциалом для широкого применения в академических и промышленных средах. Она становится свидетельством постоянного развития в области информационного поиска и предлагает многообещающее решение для будущего мультиязычной обработки данных.
«`

























