«`html
FlashAttention-3: новый уровень скорости и точности в использовании современного оборудования и вычислений с низкой точностью
FlashAttention-3, последний релиз серии FlashAttention, разработан для устранения внутренних узких мест слоя внимания в архитектурах трансформаторов. Эти узкие места критичны для производительности больших языковых моделей (БЯМ) и приложений, требующих обработки длинного контекста.
Серия FlashAttention, включая предшественников FlashAttention и FlashAttention-2, революционизировала работу механизмов внимания на графических процессорах (GPU), минимизируя чтение и запись памяти. Большинство библиотек широко приняли это новшество для ускорения обучения и вывода трансформаторов, внося значительный вклад в драматическое увеличение длины контекста БЯМ в последние годы. Например, длина контекста выросла с 2-4 тыс. токенов в моделях, таких как GPT-3, до 128 тыс. токенов в GPT-4 и даже до 1 миллиона токенов в моделях, таких как Llama 3.
Выборочные оптимизации для улучшения скорости внимания на Hopper GPU
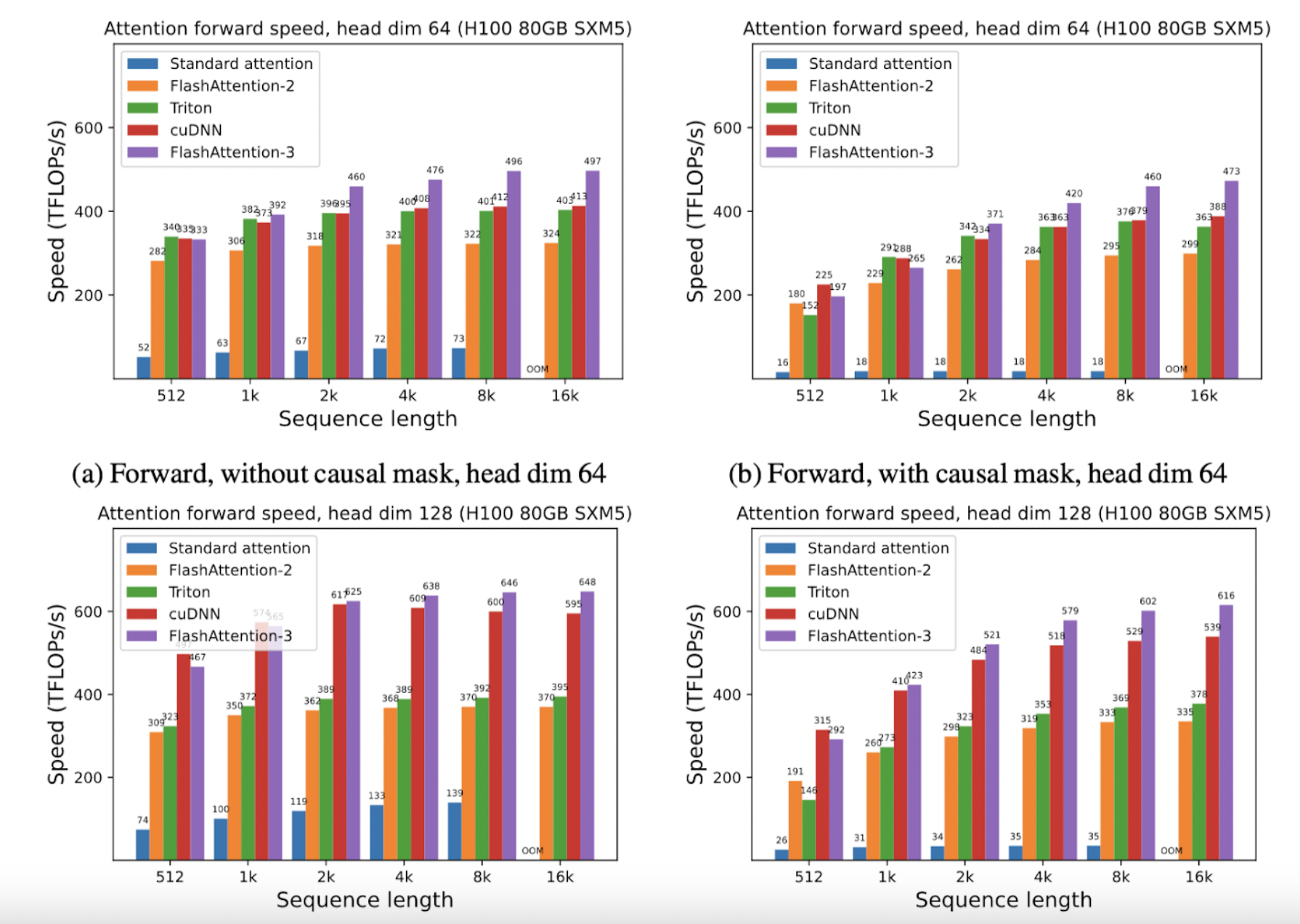
Одной из ключевых особенностей FlashAttention-3 является способность использовать асинхронность Tensor Cores и TMA для перекрытия вычислений и перемещения данных. Это позволяет FlashAttention-3 значительно увеличить скорость вычислений и точность за счет уменьшения ошибки квантования при помощи несогласованной обработки.
FlashAttention-3 1,5-2 раза быстрее, чем FlashAttention-2 с использованием FP16, достигая до 740 TFLOPS, что составляет 75% от теоретически максимальной производительности FLOP на H100 GPU. С использованием FP8 FlashAttention-3 достигает близко к 1,2 PFLOPS, что представляет собой значительный скачок в производительности с 2,6 раза меньшей ошибкой по сравнению с базовым вниманием FP8.
Использование библиотеки CUTLASS NVIDIA
Эти успехи основаны на использовании библиотеки CUTLASS NVIDIA, предоставляющей мощные абстракции, позволяющие FlashAttention-3 использовать возможности Hopper GPU. Путем переписывания FlashAttention для интеграции этих новых функций Dao AI Lab разблокировал значительные приросты эффективности, позволяя новым моделям расширить возможности, такие как увеличение длины контекста и улучшение скорости вывода.
Парадигмальный сдвиг в применении механизмов внимания в БЯМ
Релиз FlashAttention-3 представляет собой парадигмальный сдвиг в проектировании и реализации механизмов внимания в больших языковых моделях. Dao AI Lab продемонстрировала, как целенаправленные оптимизации могут привести к значительному улучшению производительности путем тесного соответствия алгоритмических инноваций с аппаратными достижениями.
«`

























