«`html
Alibaba представила Qwen2-VL: новейшую модель языка и зрения в семействе моделей Qwen
Исследователи Alibaba объявили о выпуске Qwen2-VL, последней версии модели языка и зрения на основе Qwen2 в семействе моделей Qwen. Эта новая версия представляет собой значительный прорыв в мультимодальных возможностях искусственного интеллекта, основанный на фундаменте, заложенном предшественником Qwen-VL. Продвижения в Qwen2-VL открывают захватывающие возможности для широкого спектра применений в области визуального понимания и взаимодействия, после года интенсивных усилий по разработке.
Оценка возможностей Qwen2-VL
Исследователи оценили визуальные возможности Qwen2-VL в шести ключевых измерениях: решение сложных задач уровня колледжа, математические способности, понимание документов и таблиц, многоязычное понимание текста и изображений, ответы на общие сценарные вопросы, понимание видео и взаимодействие с агентами. 72-миллиардная модель продемонстрировала высокую производительность по большинству метрик, часто превосходя даже закрытые модели, такие как GPT-4V и Claude 3.5-Sonnet. Особенно Qwen2-VL проявила значительное преимущество в понимании документов, подчеркивая свою универсальность и продвинутые возможности обработки визуальной информации.
Модели Qwen2-VL
Модель масштаба 7 миллиардов Qwen2-VL поддерживает изображения, множественные изображения и видеовходы, обеспечивая конкурентоспособную производительность в более экономичном размере. Эта версия отличается в задачах понимания документов, как это показала ее производительность на бенчмарках, таких как DocVQA. Кроме того, модель проявляет впечатляющие способности в понимании многоязычного текста изображений, достигая передовой производительности на бенчмарке MTVQA. Эти достижения подчеркивают эффективность и универсальность модели в различных визуальных и языковых задачах.
Также была представлена новая компактная модель 2 миллиарда Qwen2-VL, оптимизированная для возможного мобильного развертывания. Несмотря на свой небольшой размер, эта версия демонстрирует высокую производительность в понимании изображений, видео и многоязычном понимании. Модель 2 миллиарда особенно успешна в задачах, связанных с видео, пониманием документов и ответами на общие сценарные вопросы по сравнению с другими моделями подобного масштаба. Это развитие показывает способность исследователей создавать эффективные высокопроизводительные модели, подходящие для ресурсоемких сред.
Улучшения в Qwen2-VL
Qwen2-VL внедряет значительные улучшения в распознавании объектов, включая сложные многокомпонентные отношения и улучшенное распознавание рукописного текста и многоязычное распознавание. Математические и программирования навыки модели были значительно улучшены, что позволяет ей решать сложные задачи через анализ диаграмм и интерпретацию искаженных изображений. Извлечение информации из реальных изображений и диаграмм было усилено, а также улучшены возможности следования инструкциям. Кроме того, Qwen2-VL теперь успешно выполняет анализ видео-контента, предлагая суммирование, ответы на вопросы и возможности реального времени. Эти усовершенствования позиционируют Qwen2-VL как универсального визуального агента, способного связать абстрактные концепции с практическими решениями в различных областях.
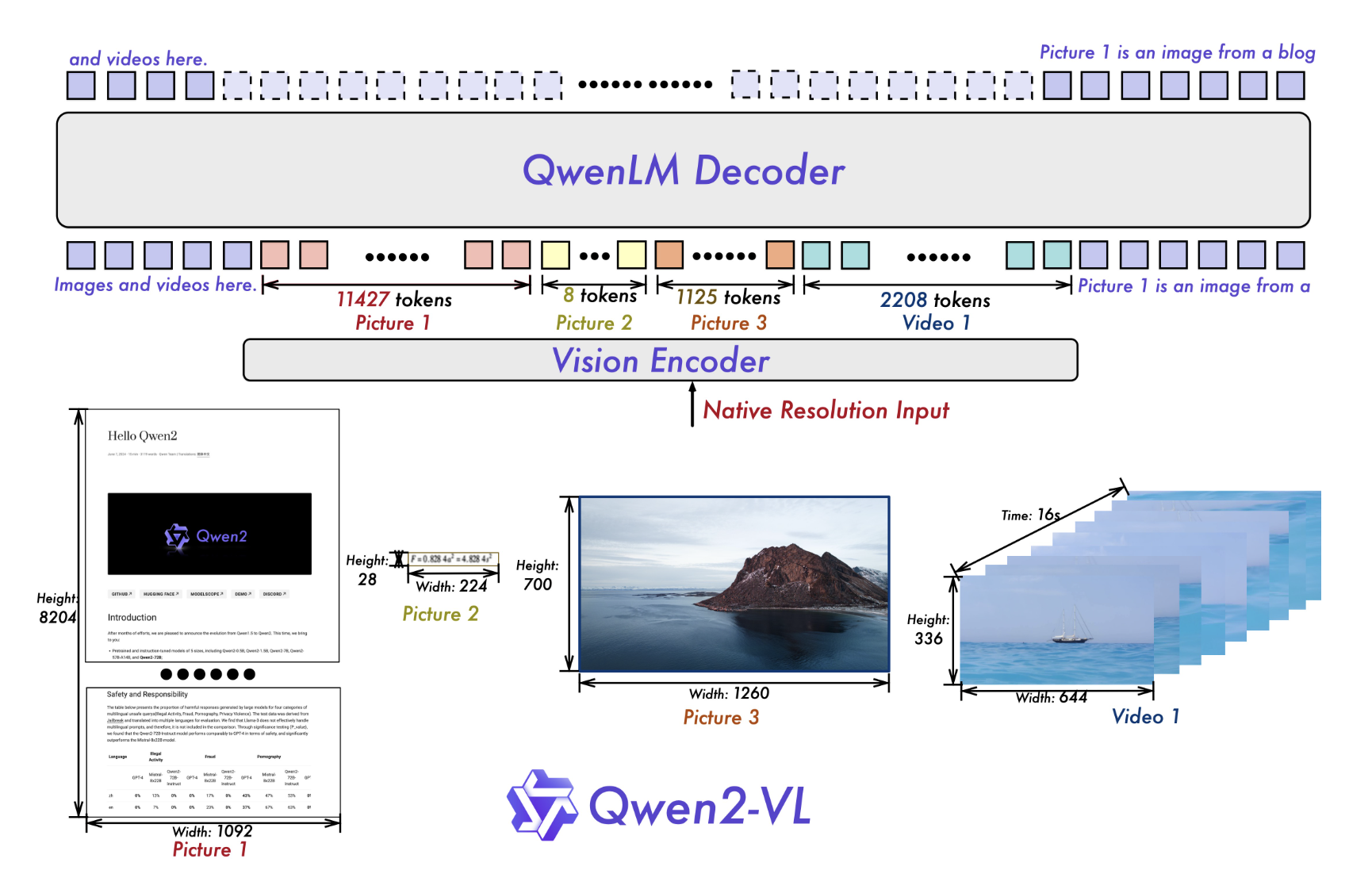
Архитектура Qwen2-VL
Исследователи сохраняют архитектуру Qwen-VL для Qwen2-VL, которая объединяет модель Vision Transformer (ViT) с языковыми моделями Qwen2. Все варианты используют Vision Transformer с примерно 600 миллионами параметров, способными обрабатывать как изображения, так и видеовходы. Основные улучшения включают в себя реализацию поддержки Naive Dynamic Resolution, позволяющей модели обрабатывать произвольные разрешения изображений путем отображения их в динамическое количество визуальных токенов. Этот подход более точно имитирует визуальное восприятие человека. Также инновация Multimodal Rotary Position Embedding (M-ROPE) позволяет модели одновременно захватывать и интегрировать 1D текстовую, 2D визуальную и 3D видео-позиционную информацию.
Alibaba представила Qwen2-VL, последнюю модель языка и зрения в семействе моделей Qwen, улучшающую мультимодальные возможности искусственного интеллекта. Доступные в 72 миллиардах, 7 миллиардах и 2 миллиардах версиях, Qwen2-VL превосходит в сложном решении задач, понимании документов, многоязычном понимании текста и изображений и анализе видео, часто опережая модели, такие как GPT-4V. Основные инновации включают улучшенное распознавание объектов, улучшенные математические и программные навыки и способность обрабатывать сложные визуальные задачи. Модель объединяет Vision Transformer с поддержкой Naive Dynamic Resolution и Multimodal Rotary Position Embedding, что делает ее универсальным и эффективным инструментом для различных приложений.
«`

























