“`html
Make-An-Agent: Новый генератор параметров политики, использующий силу условных моделей диффузии для генерации поведения-политики
Традиционное обучение политике использует выборочные траектории из буфера воспроизведения или демонстрации поведения для обучения политик или моделей траекторий, отображающих состояние в действие. Однако существует вызов в направлении генерации высокоразмерного вывода с использованием низкоразмерных демонстраций. Модели диффузии показали высокую конкурентоспособность на задачах, таких как синтез текста в изображение. Этот успех поддерживает работу по генерации сети политики как условного процесса денойзинга диффузии. Улучивая шум в структурированные параметры последовательно, генератор на основе диффузии может обнаружить различные политики с превосходной производительностью и устойчивым пространством параметров политики.
Существующие методы в этой области включают генерацию параметров и обучение для обучения политике.
Генерация параметров была значительной фокусной точкой исследований с момента появления гиперсетей, что привело к различным исследованиям предсказания весов нейронной сети. Например, Hypertransformer использует трансформеры для генерации весов для каждого слоя сверточных нейронных сетей (CNN) на основе образцов задач, используя обучение с учителем и полу-обучение. С другой стороны, обучение для обучения политике включает мета-обучение, которое направлено на разработку политики, способной адаптироваться к любой новой задаче в пределах заданного распределения задач. В процессе мета-обучения или мета-тестирования предыдущие методы мета-усиления обучения (мета-RL) полагаются на вознаграждения для адаптации политики.
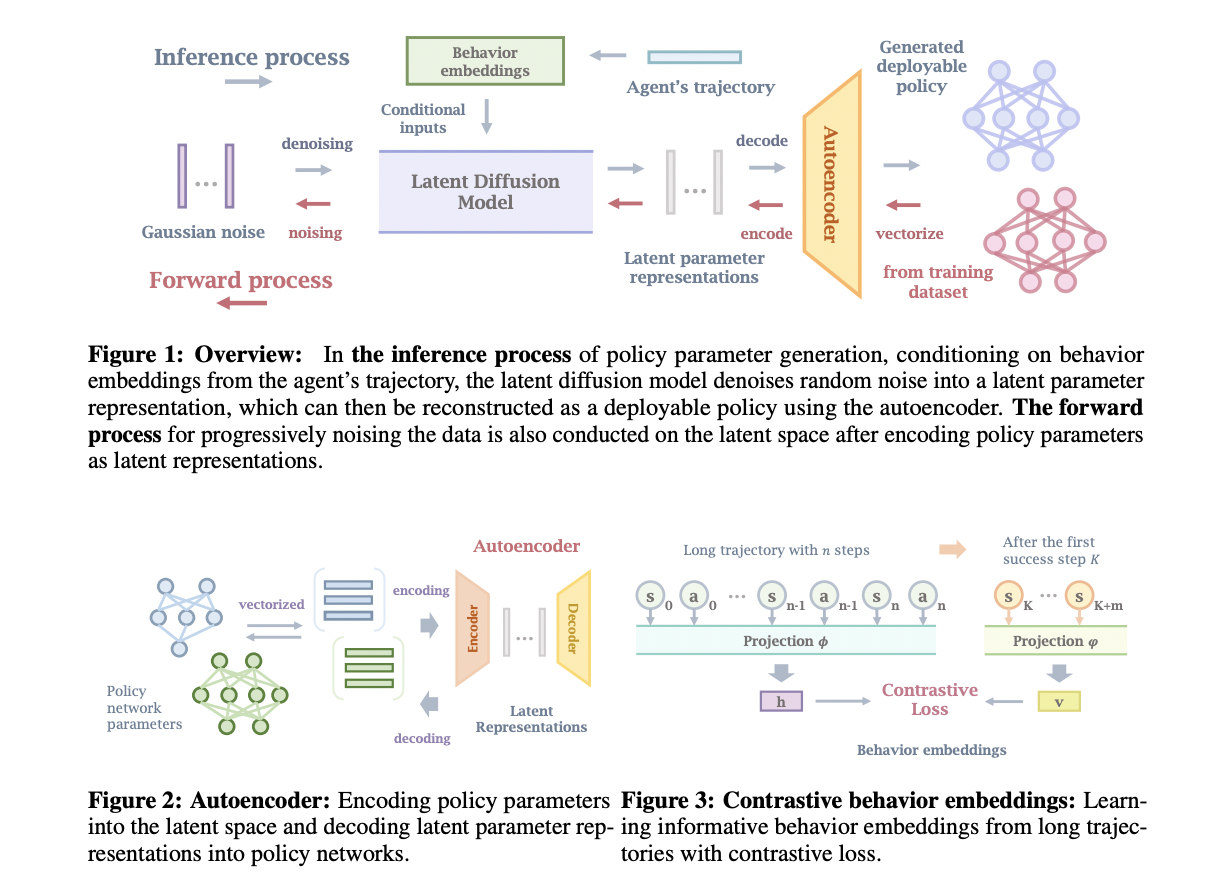
Исследователи из Университета Мэриленда, Университета Цинхуа, Университета Калифорнии, Шанхайского института Ци Чжи и Шанхайской лаборатории искусственного интеллекта предложили Make-An-Agent, новый метод генерации политик с использованием условных моделей диффузии. В этом процессе разрабатывается автоэнкодер для сжатия сетей политики в более маленькие латентные представления на основе их слоя. Исследователи использовали контрастное обучение для установления связи между долгосрочными траекториями и их результатами или будущими состояниями. Кроме того, эффективная модель диффузии используется на основе изученных встроенных поведенческих вложений для генерации параметров политики, которые затем декодируются в используемые политики с предварительно обученным декодером.
Производительность Make-An-Agent оценивается путем тестирования в трех областях непрерывного управления, включая различные задачи на столешнице и задачи реальной локомоции. Политики были сгенерированы во время тестирования с использованием траекторий из буфера воспроизведения частично обученных агентов RL. Сгенерированные политики превзошли те, которые были созданы с помощью многозадачного или мета-обучения и других методов на основе гиперсетей. Этот подход имеет потенциал для производства разнообразных параметров политики и показывает сильную производительность, несмотря на окружающую случайность как в симуляторах, так и в реальных ситуациях. Более того, Make-An-Agent может производить высокопроизводительные политики даже при наличии шумных траекторий, демонстрируя устойчивость модели.
Политики, сгенерированные Make-An-Agent в реальных сценариях, тестируются с использованием техники walk-these-ways и обучаются на IsaacGym. Сети актеров генерируются с использованием предложенного метода на основе траекторий из симуляций IsaacGym и предварительно обученных модулей адаптации. Эти сгенерированные политики затем развертываются на реальных роботах в средах, отличных от симуляций. Каждая политика для движения в реальном мире включает 50 956 параметров, и для каждой задачи в MetaWorld и Robosuite собирается 1 500 сетей политики. Эти сети происходят из точек контроля политики во время обучения SAC и сохраняются каждые 5 000 шагов обучения после того, как коэффициент успешности теста достигает 1.
В этой статье исследователи представляют новый метод генерации политики под названием Make-An-Agent, основанный на условных моделях диффузии. Этот метод направлен на генерацию политик в пространствах с большим количеством параметров с использованием автоэнкодера для кодирования и восстановления этих параметров. Результаты, протестированные в различных областях, показывают, что их подход хорошо работает в многозадачных средах, способен обрабатывать новые задачи и устойчив к окружающей случайности. Однако из-за большого количества параметров не исследуются более разнообразные сети политик, и возможности генератора диффузии параметров ограничены автоэнкодером параметров, поэтому будущие исследования могут рассмотреть более гибкие способы генерации параметров.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу Telegram и группе LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 46k+ ML SubReddit.
Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/. Этот ИИ ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.
“`
























