Применение масштабируемого многоагентного обучения с подкреплением для эффективного принятия решений в крупномасштабных системах
Основная задача в масштабировании крупномасштабных систем искусственного интеллекта заключается в достижении эффективного принятия решений при сохранении производительности. Распределенный искусственный интеллект, в частности, многоподходное обучение с подкреплением (MARL), предлагает потенциал путем декомпозиции сложных задач и распределения их между совместными узлами. Однако реальные приложения сталкиваются с ограничениями из-за высоких требований к коммуникации и данным. Традиционные методы, такие как модельное предсказывающее управление (MPC), требуют точной динамики системы и часто упрощают нелинейные сложности. В то время как MARL обещает в областях автономного управления и энергетических системах, он по-прежнему сталкивается с проблемами эффективного обмена информацией и масштабируемости в сложных реальных средах из-за ограничений коммуникации и непрактичных предположений.
Практические решения и ценность
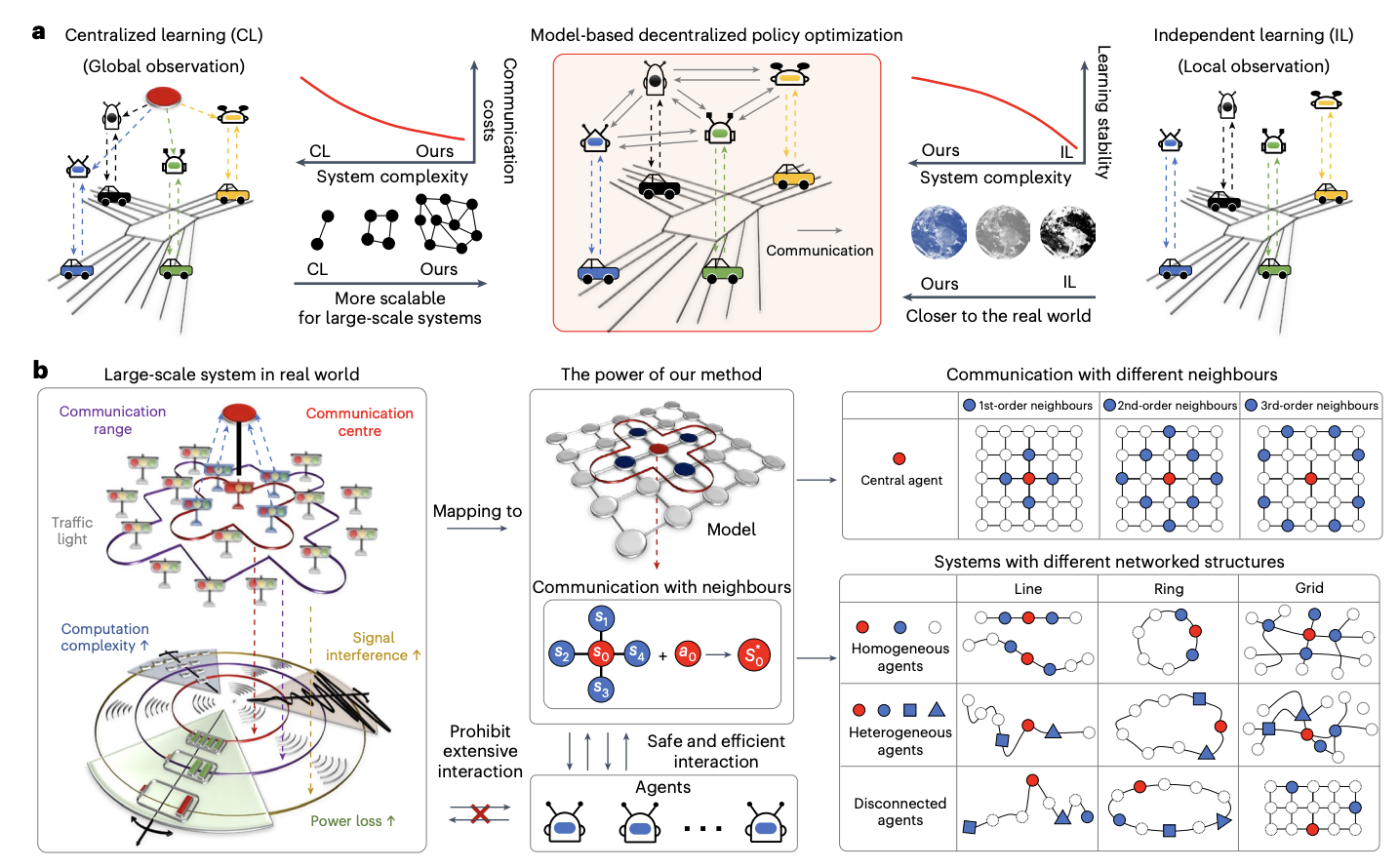
Исследователи Пекинского университета и Королевского колледжа Лондона разработали децентрализованную оптимизацию политики для фреймворка мультиагентных систем. Путем использования локальных наблюдений через топологическое отделение глобальной динамики они обеспечивают точные оценки международной информации. Их подход интегрирует обучение модели для улучшения оптимизации политики с ограниченными данными. В отличие от предыдущих методов, этот фреймворк улучшает масштабируемость путем снижения коммуникации и сложности системы. Эмпирические результаты на различных сценариях, включая транспорт и энергетические системы, демонстрируют его эффективность в управлении крупномасштабными системами с сотнями агентов. Он обеспечивает превосходную производительность в реальных приложениях при ограниченной коммуникации и гетерогенных агентах.
В децентрализованной модельной оптимизации политики каждый агент поддерживает локализованные модели, предсказывающие будущие состояния и вознаграждения путем наблюдения за своими действиями и состояниями своих соседей. Политики оптимизируются с использованием двух буферов опыта: один для данных реальной среды и другой для созданных моделью данных. Используется ветвистая техника прокатки, чтобы предотвратить накопление ошибок, начиная прокатки модели из случайных состояний в предыдущих траекториях для улучшения точности. Обновления политики включают локализованные функции ценности и используют агентов PPO, гарантируя улучшение политики путем постепенного минимизирования приближения и зависимостей во время обучения.
Методы описывают сетевой марковский процесс принятия решений (MDP) с несколькими агентами, представленными как узлы в графе. Каждый агент общается с соседями для оптимизации децентрализованной политики обучения с подкреплением для улучшения локальных вознаграждений и общей производительности системы. Обсуждаются два типа систем: независимые сетевые системы (INS), где взаимодействие агентов минимально, и системы, зависящие от ξ, которые учитывают уменьшающееся влияние с расстоянием. Подход обучения на основе модели приближает динамику системы, обеспечивая монотонное улучшение политики. Этот метод тестировался в крупномасштабных сценариях, таких как управление трафиком и энергетические сети, с акцентом на децентрализованное управление агентов для оптимальной производительности.
Исследование демонстрирует превосходную производительность децентрализованного фреймворка MARL, протестированного как в симуляторах, так и в реальных системах. По сравнению с централизованными базовыми линиями, такими как MAG и CPPO, подход значительно снижает затраты на коммуникацию (5-35%), улучшая сходимость и эффективность выборки. Метод продемонстрировал хорошие результаты на контрольных задачах, таких как управление автомобилями и светофорами, управление сетями во время пандемии и операции в энергетических сетях, последовательно превосходя базовые линии. Улучшенные длины прокатки и оптимизированный выбор соседей улучшили прогнозы моделей и результаты обучения. Эти результаты подчеркивают масштабируемость фреймворка и его эффективность в управлении крупномасштабными сложными системами.
В заключение, исследование представляет собой масштабируемый фреймворк MARL, эффективный для управления крупными системами с сотнями агентов, превосходящий возможности предыдущих децентрализованных методов. Подход использует минимальный обмен информацией для оценки глобальных условий, подобно теории шести степеней разделения. Он интегрирует модельную децентрализованную оптимизацию политики, что улучшает эффективность принятия решений и масштабируемость путем снижения потребностей в коммуникации и данных. Фокусируясь на локальные наблюдения и совершенствование политик через обучение модели, фреймворк поддерживает высокую производительность даже при увеличении размера системы. Результаты подчеркивают его потенциал для продвинутых приложений в управлении трафиком, энергией и пандемическим управлением.
Проверить статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и LinkedIn. Присоединяйтесь к нашему каналу Telegram.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 50k+ ML SubReddit
Пост Scalable Multi-Agent Reinforcement Learning Framework for Efficient Decision-Making in Large-Scale Systems был опубликован на MarkTechPost.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Scalable Multi-Agent Reinforcement Learning Framework for Efficient Decision-Making in Large-Scale Systems.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизацию: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram.
Попробуйте ИИ ассистент в продажах здесь. Этот ИИ ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru

























