Введение в Гибридную Систему Наград в ИИ
Недавнее исследование от ByteDance представляет значительное достижение в области искусственного интеллекта через гибридную систему наград. Эта система объединяет Проверяющие Задачи Размышления (RTV) и Генеративную Модель Наград (GenRM) для решения критической проблемы взлома наград в Обучении с Подкреплением от Человеческой Обратной Связи (RLHF).
Понимание RLHF и его Важность
Обучение с Подкреплением от Человеческой Обратной Связи критично для согласования больших языковых моделей с человеческими ценностями и предпочтениями. Несмотря на наличие альтернатив, ведущие модели ИИ, такие как ChatGPT и Claude, по-прежнему зависят от алгоритмов RL для достижения оптимальной производительности.
Проблемы Качества Модели Наград
Эффективность RLHF сильно зависит от качества модели наград, которая сталкивается с тремя основными проблемами:
- Некорректные Модели Наград: Трудности в точном захвате предпочтений человека.
- Неясность в Обучающих Данных: Неточные или нечеткие предпочтения в обучающих наборах данных.
- Плохая Способность К Генерализации: Неспособность модели хорошо работать с новыми вводами.
Гибридная Система Наград
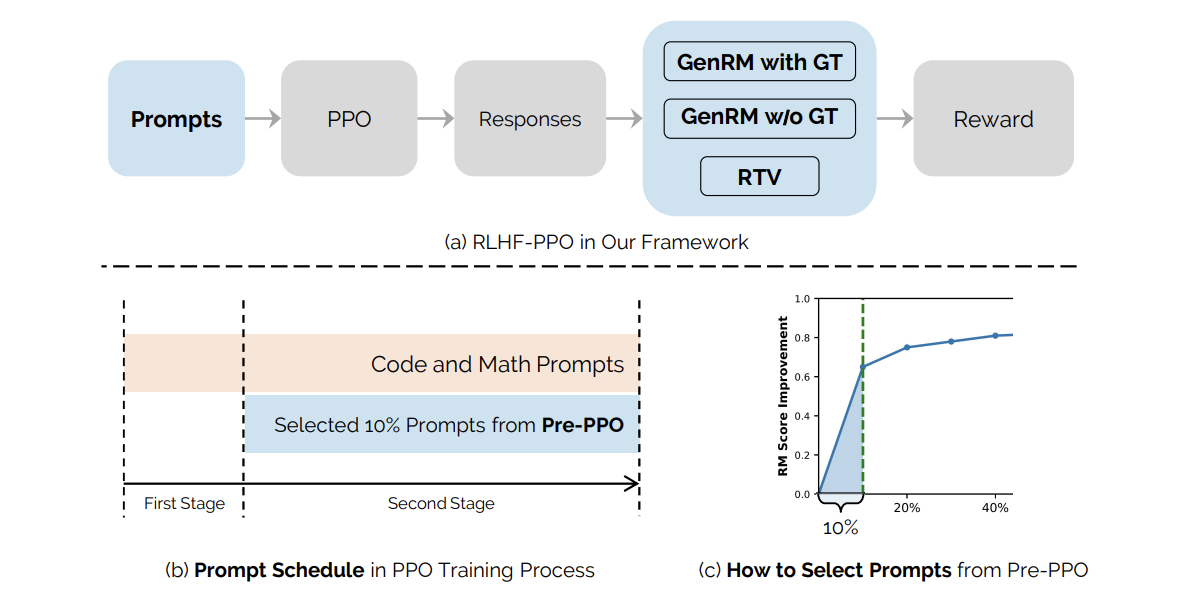
Для смягчения этих проблем исследователи предлагают гибридную систему наград, которая интегрирует RTV и GenRM. Эта система демонстрирует более высокую устойчивость к взлому наград, что позволяет более точно оценивать ответы модели по сравнению с установленными истинными решениями.
Инновационный Метод Выбора Запросов
Разработан инновационный метод выбора запросов, называемый Pre-PPO, который помогает определить сложные обучающие запросы, менее подверженные взлому наград. Этот стратегический процесс выбора улучшает качество обучающих данных и, в конечном итоге, производительность модели.
Экспериментальная Установка и Результаты
В исследовании использовались две предварительно обученные языковые модели с различными масштабами — одна с 25 миллиардами параметров и другая с 150 миллиардами параметров. Обучающий набор данных состоял из одного миллиона запросов по нескольким направлениям, включая математику и программирование. Была установлена комплексная оценочная система, оценивающая множество навыков и задач.
Результаты экспериментов показали, что комбинация Pre-PPO и приоритезированных задач последовательно превосходила базовые методы, с заметными улучшениями в задачах математики и программирования.
Заключение
В заключение, это исследование подчеркивает значительные узкие места в масштабировании данных RLHF, сосредотачиваясь на проблемах взлома наград и уменьшенной разнообразии ответов. Предложенный гибридный подход, использующий RTV и GenRM, в сочетании со стратегическим выбором запросов, прокладывает путь к оптимизации построения данных RLHF. Это основополагающая работа обещает обеспечить более надежные методы согласования моделей ИИ с человеческими ценностями.
Шаги для Реализации
- Изучить, какие процессы можно автоматизировать и где ИИ может добавить наибольшую ценность в взаимодействиях с клиентами.
- Определить важные ключевые показатели (KPI), чтобы гарантировать, что инвестиции в ИИ положительно влияют на бизнес.
- Выбрать инструменты, соответствующие вашим потребностям, и настроить их в соответствии с вашими целями.
- Начать с небольшого проекта, собрать данные о его эффективности и постепенно расширять использование ИИ в вашей работе.
Если вам нужна помощь в управлении ИИ в бизнесе, свяжитесь с нами по адресу info@flycode.ru. Чтобы быть в курсе последних новостей ИИ, подписывайтесь на наш Telegram здесь.