«`html
Решения для эффективного развертывания крупных языковых моделей
Крупные языковые модели (LLM) такие, как GPT-3 и Llama-2, значительно продвинулись в понимании и генерации человеческого языка. Однако их развертывание сталкивается с проблемой огромных вычислительных ресурсов. Для решения этой проблемы и сделать технологии ИИ более доступными и применимыми, исследователи из NVIDIA и Университета Техаса в Остине представили новую архитектуру FLEXTRON.
Архитектура FLEXTRON
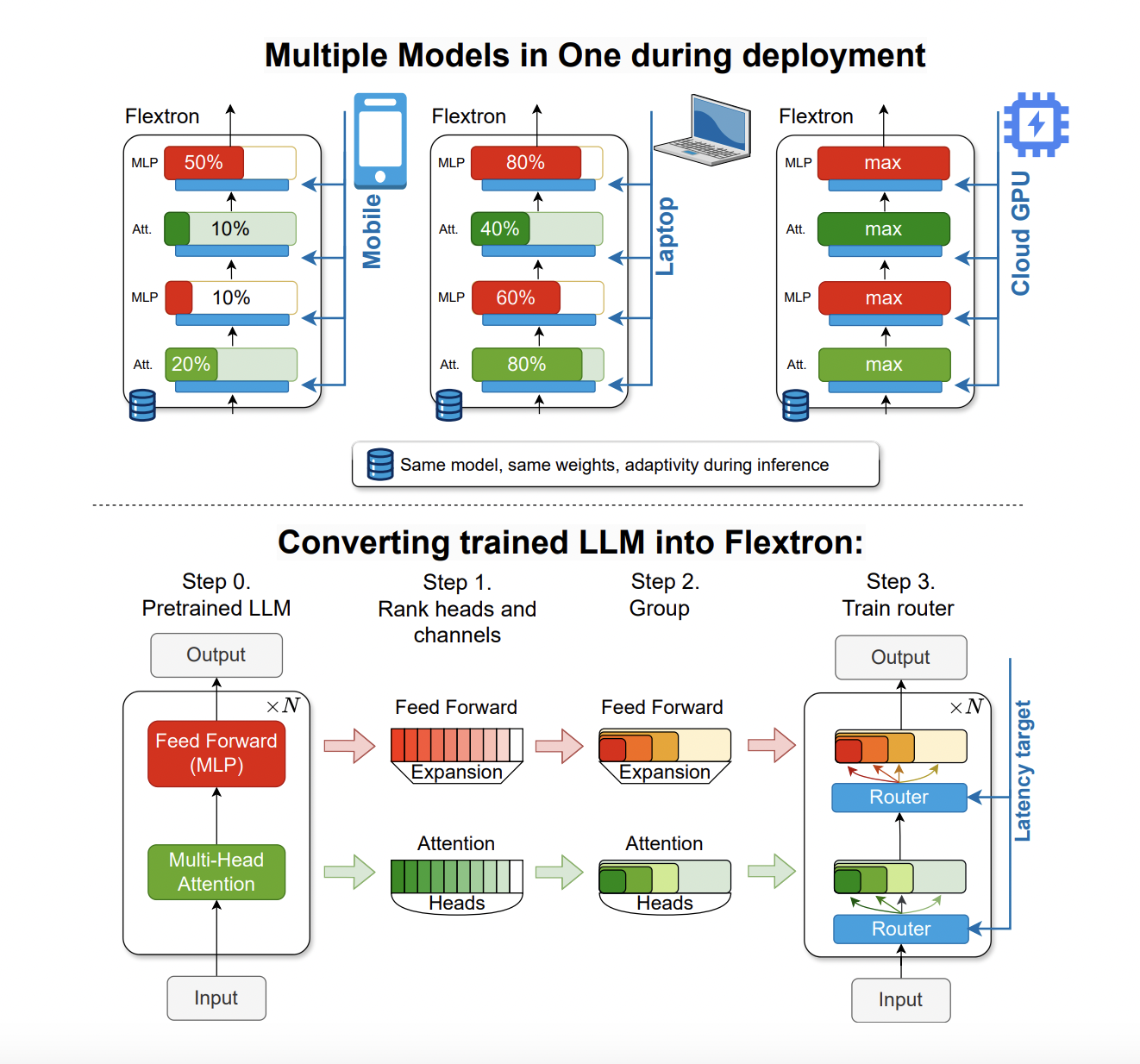
FLEXTRON позволяет создавать адаптивные модели без дополнительной настройки, что решает проблемы традиционных методов. Она использует упругую структуру, позволяющую динамически настраиваться под конкретные цели скорости и точности в процессе вывода. Это позволяет использовать одну предварительно обученную модель в различных сценариях развертывания, существенно сокращая необходимость в множестве вариантов моделей.
Преимущества FLEXTRON
Эффективные оценки производительности FLEXTRON показали ее превосходство по сравнению с другими моделями. Например, FLEXTRON продемонстрировала высокую эффективность на моделях GPT-3 и Llama-2, требуя всего 7,63% обучающих токенов, используемых в исходном предварительном обучении. Это приводит к значительной экономии вычислительных ресурсов и времени.
Кроме того, FLEXTRON включает упругие слои многослойного перцептрона (MLP) и упругие слои многоголового внимания (MHA), улучшая свою адаптивность. Упругие слои MHA улучшают общую эффективность, выбирая подмножество внимательных головок в зависимости от входных данных. Эта функция особенно полезна в сценариях с ограниченными вычислительными ресурсами, так как позволяет более эффективно использовать доступную память и процессорную мощность.
Заключение
Архитектура FLEXTRON предлагает гибкую и адаптивную структуру, оптимизирующую использование ресурсов и производительность, что решает критическую потребность в эффективном развертывании моделей в различных вычислительных средах. Представление этой архитектуры исследователями из NVIDIA и Университета Техаса в Остине подчеркивает потенциал инновационных решений в преодолении вызовов, связанных с крупными языковыми моделями.
«`

























