Современные ИИ-системы: Запоминание против Обобщения
Современные ИИ-системы используют методы, такие как супервизированное дообучение (SFT) и обучение с подкреплением (RL), чтобы адаптировать базовые модели для конкретных задач. Важно понять, помогают ли эти методы моделям запоминать данные обучения или обобщать на новые сценарии.
Проблемы с SFT и RL
Исследования показывают, что SFT может привести к переобучению, что делает модели уязвимыми к новым вариантам задач. Например, модель, обученная на определенных значениях карт, может не справиться с изменением правил. RL, с другой стороны, может как поощрять гибкое решение задач, так и укреплять узкие стратегии.
Эксперименты и результаты
Недавнее исследование сравнивает, как SFT и RL влияют на способность модели адаптироваться к новым задачам. Исследователи разработали две задачи:
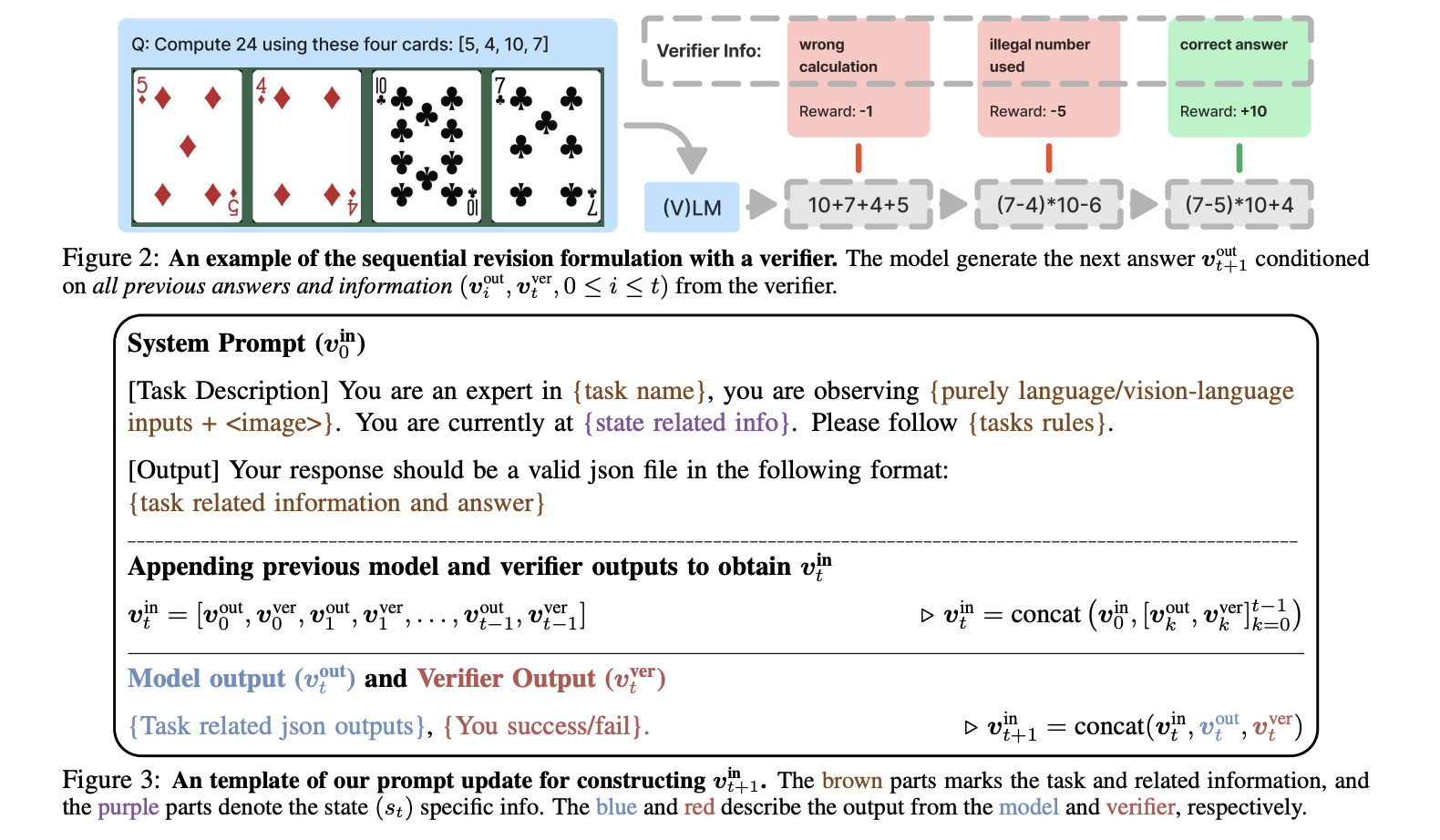
- Обобщение на основе правил (GeneralPoints): Создание уравнений, равных 24, используя четыре числа из игральных карт.
- Визуальное обобщение (V-IRL): Навигация к целевому месту с использованием визуальных ориентиров.
Ключевые выводы
1. SFT и запоминание: Модели, обученные с помощью SFT, могут запоминать конкретные правила, но не могут адаптироваться к изменениям.
2. RL и обобщение: Модели, обученные с помощью RL, лучше адаптируются к новым правилам и условиям, так как они понимают структуру задачи.
3. Итерации RL: Множественные попытки решения задачи в рамках одного этапа обучения улучшают производительность.
Рекомендации для практиков
Для успешного внедрения ИИ в вашу компанию:
- Анализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые вы хотите улучшить с помощью ИИ.
- Выбирайте подходящие решения и внедряйте их постепенно.
- Начинайте с небольших проектов, анализируйте результаты и расширяйте автоматизацию на основе полученных данных.
Заключение
Это исследование показывает, что SFT хорошо подходит для обучения на данных, но неэффективен при изменениях, в то время как RL обеспечивает адаптивные стратегии. Для практиков это означает, что RL должен следовать за SFT, но только до тех пор, пока модель не достигнет базовой компетенции.

























