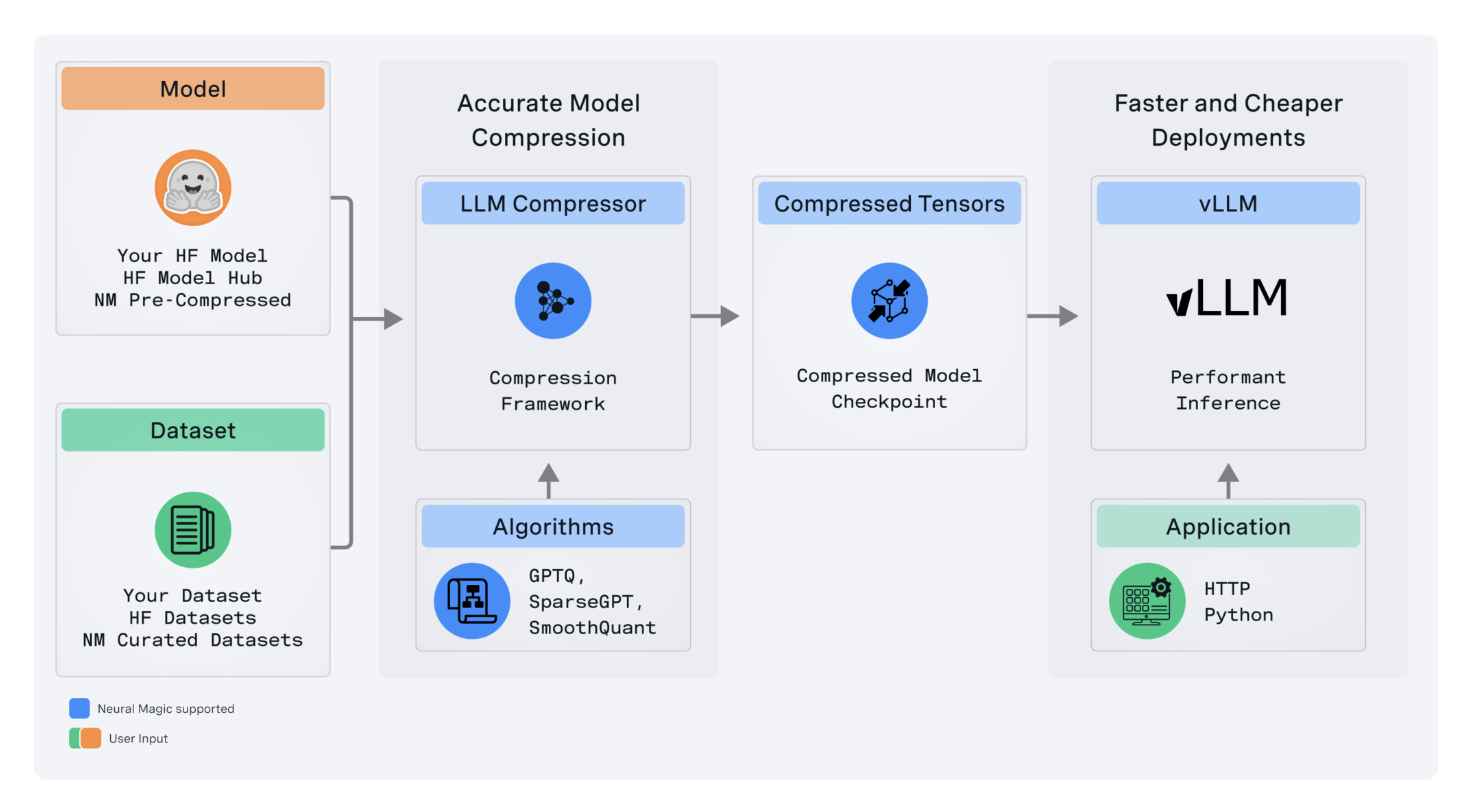
Neural Magic Releases LLM Compressor: A Novel Library to Compress LLMs for Faster Inference with vLLM
Neural Magic выпустила LLM Compressor, передовой инструмент для оптимизации больших языковых моделей, который обеспечивает значительно более быструю выводимость благодаря более продвинутой компрессии моделей. Это важный элемент стратегии Neural Magic, направленной на предоставление высокопроизводительных решений с открытым исходным кодом сообществу глубокого обучения, особенно в рамках vLLM-фреймворка.
Оптимизация моделей
LLM Compressor устраняет сложности, возникающие из фрагментированного набора инструментов для компрессии моделей, объединяя разрозненные инструменты в одну библиотеку. Это позволяет легко применять передовые алгоритмы компрессии, такие как GPTQ, SmoothQuant и SparseGPT, для создания сжатых моделей с уменьшенной задержкой вывода и высокой точностью, что является критически важным для развертывания модели в производственных средах.
Компрессия и квантизация
LLM Compressor поддерживает квантизацию активации и весов, что позволяет увеличить производительность вывода на 2 раза при высоких нагрузках сервера. Кроме того, инструмент поддерживает передовую структурированную редкость и обрезку весов с использованием SparseGPT, что минимизирует потребление памяти и позволяет развертывать модели на ресурсоемком оборудовании.
Интеграция и будущие возможности
LLM Compressor легко интегрируется в любую экосистему с открытым исходным кодом, особенно в модельный хаб Hugging Face, и обладает гибкостью в выборе стратегии квантизации. Также запланировано расширение поддержки для других моделей и аппаратных платформ, включая архитектуры MoE, визуально-языковые модели, а также не-NVIDIA платформы.
В заключение, LLM Compressor становится важным инструментом оптимизации LLM для развертывания в производство, предлагая передовые возможности компрессии моделей без ущерба для их целостности. Этот инструмент, аналогичные ему, будут играть важную роль в эффективном развертывании больших моделей на различных аппаратных платформах в области искусственного интеллекта.

























