Исследование адаптивных структур данных
Исследования в области машинного обучения достигли нового уровня, позволяя моделям самостоятельно разрабатывать структуры данных для конкретных вычислительных задач, таких как поиск ближайших соседей (NN). Это позволяет моделям не только изучать структуру данных, но и оптимизировать ответы на запросы, минимизируя потребности в хранении и времени вычислений.
Преимущества новых подходов
Современные методы машинного обучения выходят за рамки традиционной обработки данных, решая задачи структурной оптимизации. Это особенно важно в областях, где эффективный доступ к данным критически важен, особенно при ограниченных ресурсах.
Проблемы традиционных структур данных
Создание эффективных структур данных остается серьезной проблемой. Существующие структуры, такие как бинарные деревья поиска и k-d деревья, часто разрабатываются с учетом наихудших сценариев, что не позволяет им использовать потенциальные закономерности в данных для более эффективного запроса.
Инновационная методология
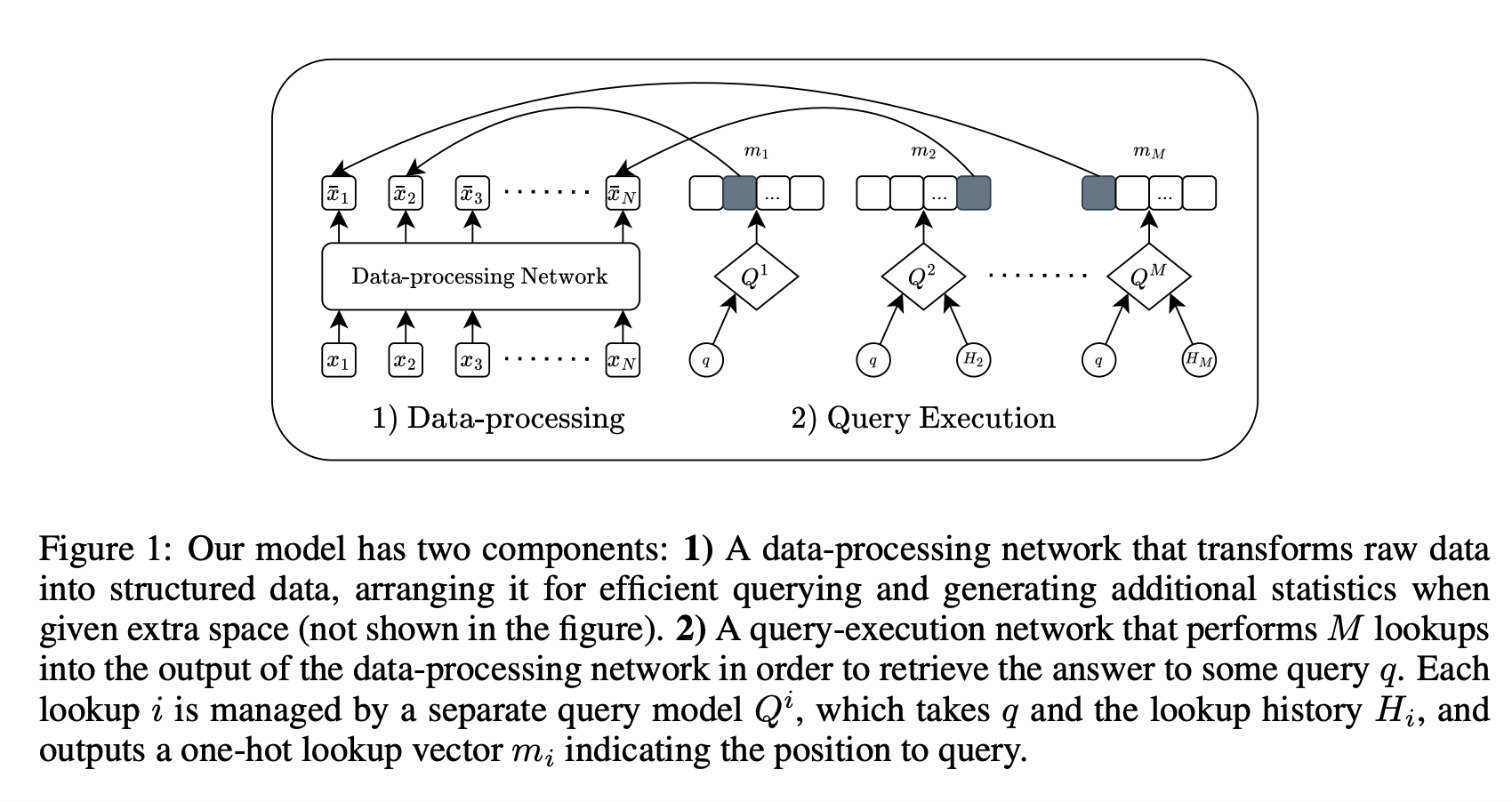
Исследователи из Университета Монреаля и других учреждений предложили инновационную структуру, которая использует машинное обучение для самостоятельного открытия структур данных, подходящих для конкретных задач. Эта структура включает два основных компонента:
- Сеть обработки данных, которая организует сырые данные в оптимизированные структуры.
- Сеть выполнения запросов, которая эффективно управляет структурированными данными для извлечения информации.
Эффективность и точность
Обе сети проходят совместное обучение, что позволяет им адаптироваться к различным распределениям данных. Это устраняет необходимость в заранее определенных структурах и позволяет создавать оптимизированные конфигурации, которые превосходят традиционные методы.
Ключевые выводы
- Автономное открытие структур: Модель самостоятельно изучает наиболее эффективные конфигурации структур данных.
- Высокая точность: Достигнута точность 99.5% в упорядочивании данных для 1D NN поиска.
- Эффективное использование памяти: Модель демонстрирует улучшение производительности при выделении дополнительной памяти.
- Широкая применимость: Гибкость модели была подтверждена в задачах оценки частоты, превосходя традиционные модели.
Заключение
Это исследование представляет собой многообещающий шаг к будущему, где машинное обучение будет использоваться для открытия структур данных. Используя адаптивное обучение, эта структура эффективно решает проблемы хранения и запросов, что открывает новые возможности для автоматического открытия в обработке данных.
Как ИИ может помочь вашей компании
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, проанализируйте, как он может изменить вашу работу. Определите, где возможно применение автоматизации, и выберите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
Подберите подходящее решение и внедряйте ИИ постепенно, начиная с небольших проектов. Если вам нужны советы по внедрению ИИ, пишите нам.









