Технологии постобучения и их значение
Техники постобучения, такие как настройка инструкций и обучение с подкреплением на основе человеческой обратной связи, стали важными для улучшения языковых моделей. Однако открытые подходы часто отстают от проприетарных моделей из-за недостатка прозрачности в данных, методах обучения и оптимизации.
Проблемы открытых моделей
Несмотря на наличие базовых моделей, отсутствие надежных открытых рецептов постобучения создает разрыв в производительности между открытыми и закрытыми моделями, ограничивая развитие открытых исследований в области ИИ.
Прогресс в открытых моделях
Предыдущие усилия, такие как Tülu 2 и Zephyr-β, пытались улучшить методы постобучения, но оставались ограниченными более простыми и экономичными процессами. В отличие от них, проприетарные модели, такие как GPT-4o и Claude 3.5-Haiku, имеют доступ к большим наборам данных и более сложным методам оптимизации.
Введение Tülu 3
В сотрудничестве с Университетом Вашингтона команда Allen Institute for AI (AI2) представила Tülu 3, прорыв в области открытых моделей постобучения. Tülu 3 основан на модели Llama 3.1 и включает множество улучшений для эффективного масштабирования при сохранении высокой производительности.
Новые достижения Tülu 3 405B
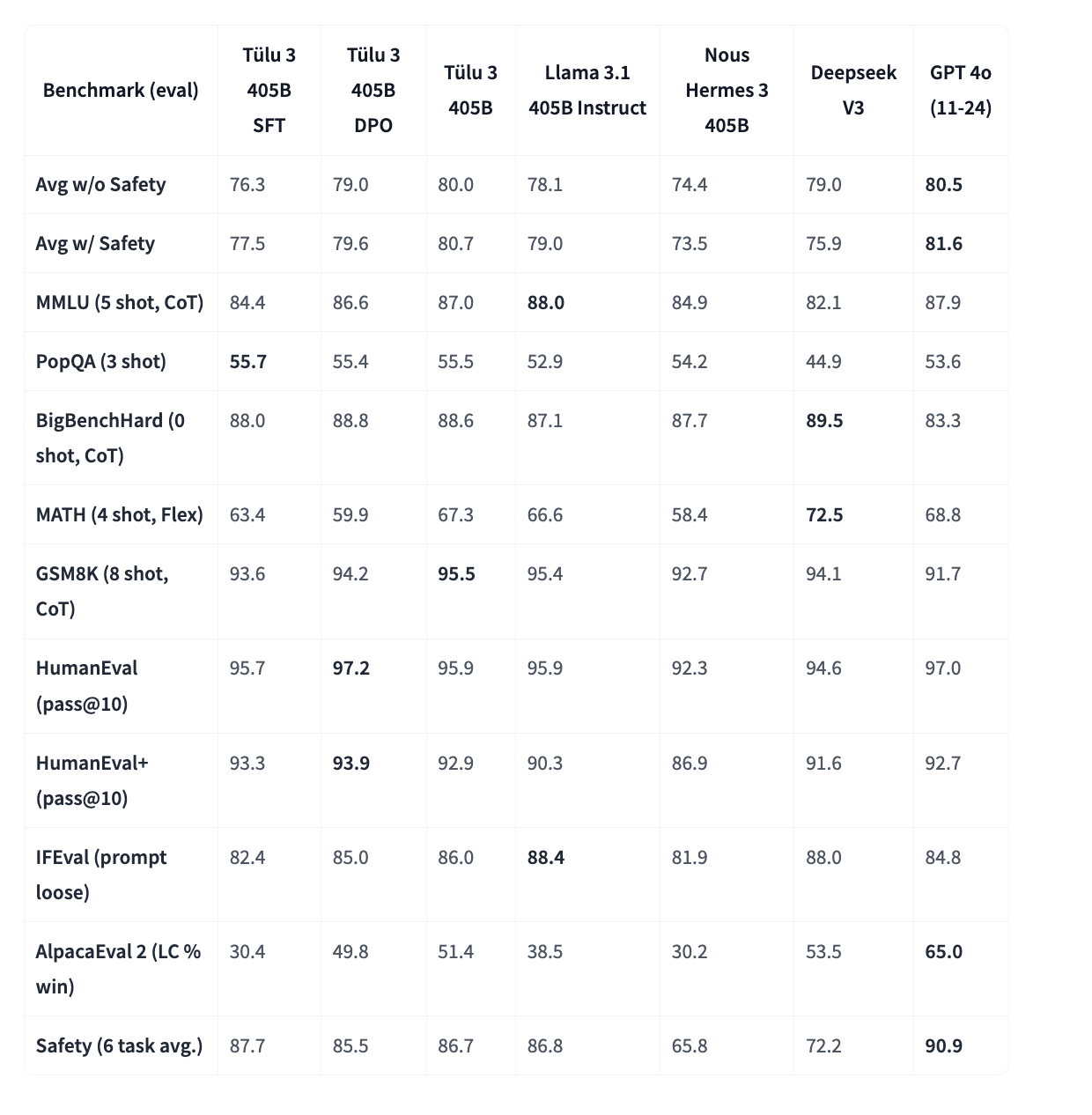
Tülu 3 405B стал первой открытой моделью, успешно применившей полностью открытый рецепт постобучения на уровне 405 миллиардов параметров. Модель использует новый подход к обучению с подкреплением, известный как Обучение с Подкреплением с Проверяемыми Наградами (RLVR), что значительно улучшает производительность в специализированных задачах.
Этапы постобучения Tülu 3
Рецепт постобучения Tülu 3 включает четыре этапа:
- Курация и синтез данных: Обеспечение представления ключевых навыков, таких как логика, математика, программирование и безопасность.
- Супервизированное тонкое обучение: Обучение модели с использованием тщательно отобранных подсказок.
- Оптимизация предпочтений: Использование данных предпочтений для улучшения ответов.
- Введение RLVR: Улучшение специализированных навыков, особенно в задачах с проверяемыми результатами.
Преимущества Tülu 3 405B
Tülu 3 405B показал конкурентоспособную или даже превосходную производительность по сравнению с DeepSeek V3 и GPT-4o, особенно в области безопасности.
Ключевые выводы
- Tülu 3 выпущен в нескольких конфигурациях параметров: 8B, 70B и 405B.
- Для обучения Tülu 3 405B использовалось 256 GPU.
- Модель превзошла DeepSeek V3 и GPT-4o в различных тестах безопасности и логики.
- Более крупные модели лучше обучаются на специализированных наборах данных.
- Новый подход RLVR улучшает производительность в математике и структурированном мышлении.
Заключение
Эволюция техник постобучения подчеркивает разрыв в производительности между открытыми и проприетарными моделями. Введение Tülu 3 405B стало важным шагом в масштабировании открытых техник постобучения, демонстрируя конкурентоспособную производительность по сравнению с передовыми моделями.
Как ИИ может помочь вашей компании?
Если вы хотите развивать свою компанию с помощью ИИ, проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации и какие ключевые показатели эффективности (KPI) вы хотите улучшить с помощью ИИ.
Подберите подходящее решение и внедряйте ИИ постепенно. Начните с малого проекта, анализируйте результаты и расширяйте автоматизацию на основе полученных данных.
Если вам нужны советы по внедрению ИИ, пишите нам.

























