“`html
Выпуск Tulu 2.5 Suite от Allen Institute for AI: преимущества и практические решения
Выпуск пакета Tulu 2.5 от Allen Institute for AI представляет собой значительный прорыв в области обучения моделей с использованием методов прямой оптимизации предпочтений (DPO) и оптимизации ближайшей политики (PPO). Tulu 2.5 включает разнообразные модели, обученные на различных наборах данных для улучшения их моделей вознаграждения и ценности. Этот пакет значительно улучшает производительность языковых моделей в различных областях, включая генерацию текста, следование инструкциям и логические рассуждения.
Обзор пакета Tulu 2.5
Пакет Tulu 2.5 включает коллекцию моделей, тщательно обученных с использованием методов DPO и PPO. Эти модели используют наборы данных предпочтений, которые критически важны для улучшения производительности языковых моделей путем включения предпочтений, сходных с человеческими, в их процесс обучения. Пакет направлен на улучшение различных возможностей языковых моделей, таких как правдивость, безопасность, кодирование и рассуждения, делая их более надежными и устойчивыми для различных приложений.
Ключевые компоненты и методики обучения
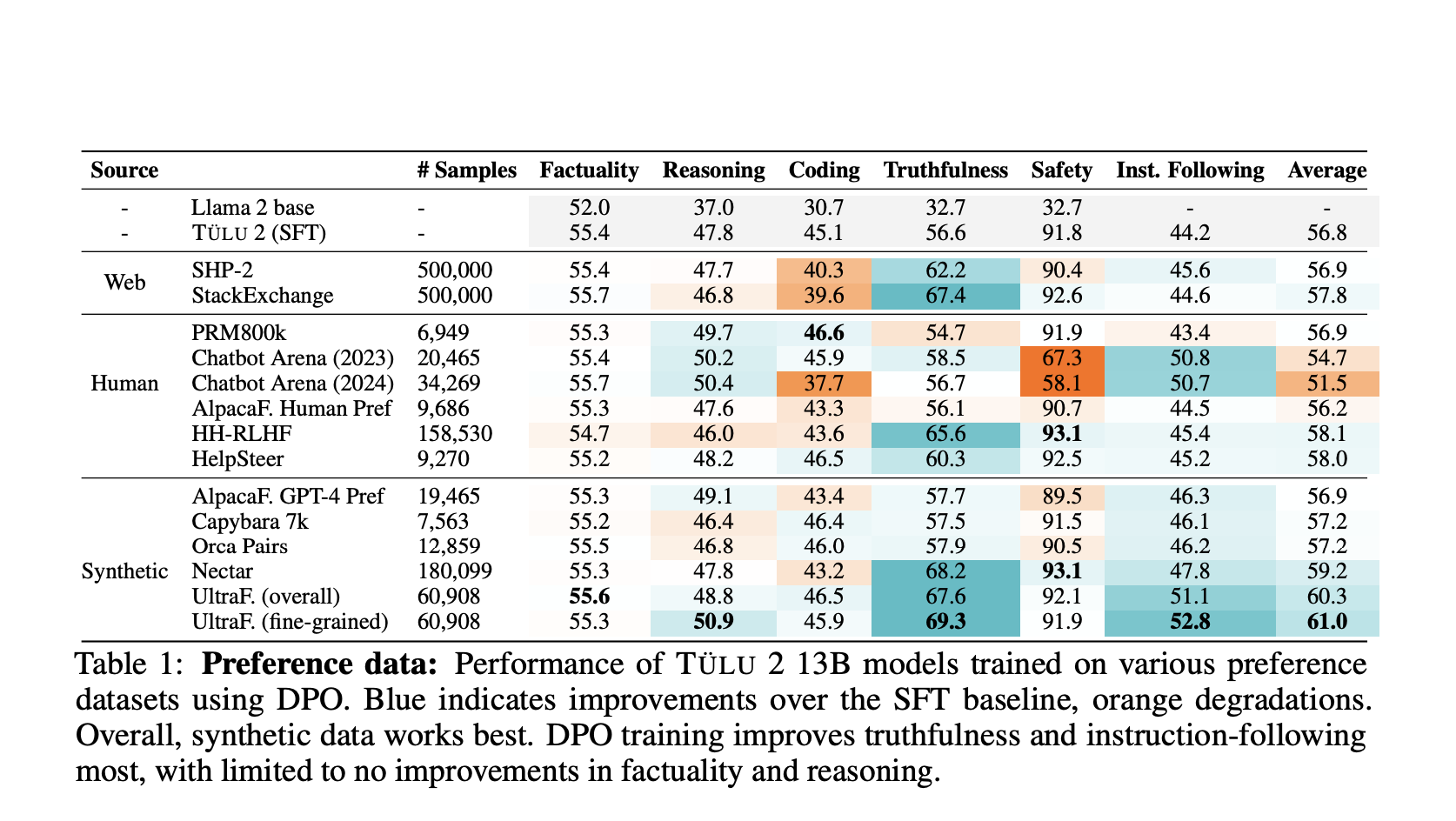
Данные предпочтений: Основу пакета Tulu 2.5 составляют высококачественные наборы данных предпочтений, включающие подсказки, ответы и рейтинги, которые помогают обучать модели отдавать предпочтение ответам, наиболее соответствующим человеческим предпочтениям. Пакет включает наборы данных из различных источников, включая аннотации людей, парсинг веб-сайтов и синтетические данные, обеспечивая комплексную систему обучения.
Предпочтения DPO против PPO: Пакет использует методики обучения DPO и PPO. DPO, подход обучения с подкреплением в офлайн-режиме, оптимизирует политику напрямую на основе данных предпочтений, не требуя генерации ответов в реальном времени. С другой стороны, PPO включает начальный этап обучения модели вознаграждения, за которым следует оптимизация политики с использованием генерации ответов в реальном времени. Этот двойной подход позволяет пакету использовать преимущества обеих методик, что приводит к превосходной производительности в различных областях.
Производительность и оценка
Модели Tulu 2.5 прошли строгую оценку по различным критериям, таким как правдивость, рассуждения, кодирование, следование инструкциям и безопасность. Результаты показывают, что модели, обученные с использованием метода PPO, в целом превосходят те, которые были обучены с использованием DPO, особенно в областях рассуждений, кодирования и безопасности.
Значительные улучшения
Следование инструкциям и правдивость: Пакет Tulu 2.5 значительно улучшает следование инструкциям и правдивость, превосходя базовые модели на значительное расстояние. Это улучшение особенно заметно в области чат-ботов, где модели лучше следуют инструкциям пользователя и предоставляют правдивые ответы.
Масштабируемость: Пакет включает модели различных размеров, с вознаграждениями, масштабированными до 70 миллиардов параметров. Это масштабируемость позволяет пакету работать с различными вычислительными мощностями, сохраняя высокую производительность. При использовании обучения PPO, более крупные модели вознаграждения приводят к заметному улучшению в определенных областях, таких как математика.
Синтетические данные: Синтетические наборы данных предпочтений, такие как UltraFeedback, доказали свою эффективность в улучшении производительности моделей. Эти наборы данных, аннотированные с учетом предпочтений по каждому аспекту, предлагают детальный и нюансированный подход к обучению на основе предпочтений, что приводит к моделям, лучше понимающим и отделяющим предпочтения пользователей.
Заключение
Выпуск пакета Tulu 2.5 от Allen Institute for AI представляет собой значительный прорыв в обучении языковых моделей на основе предпочтений. Этот пакет устанавливает новые стандарты производительности и надежности моделей ИИ, интегрируя передовые методики обучения и используя высококачественные наборы данных.
“`
























