“`html
MARKLLM: Открытый набор инструментов для LLM-водяных знаков
LLM-водяные знаки внедряют тонкие, обнаружимые сигналы в сгенерированный ИИ-текст, чтобы идентифицировать его происхождение, решая проблемы злоупотреблений, такие как подделка, авторство текстов “под покровом”, и фейковые новости. Несмотря на обещания отличить тексты, созданные людьми, от текстов, созданных ИИ, и предотвратить распространение недостоверной информации, в этой области есть проблемы. Многочисленные и сложные алгоритмы водяных знаков, а также разнообразные методы оценки, затрудняют эксперименты и понимание этих технологий для исследователей и общественности. Согласие и поддержка являются ключевыми для развития LLM-водяных знаков, чтобы обеспечить надежную идентификацию содержимого, созданного ИИ, и сохранить целостность цифровой коммуникации.
Универсальный инструментарий MARKLLM
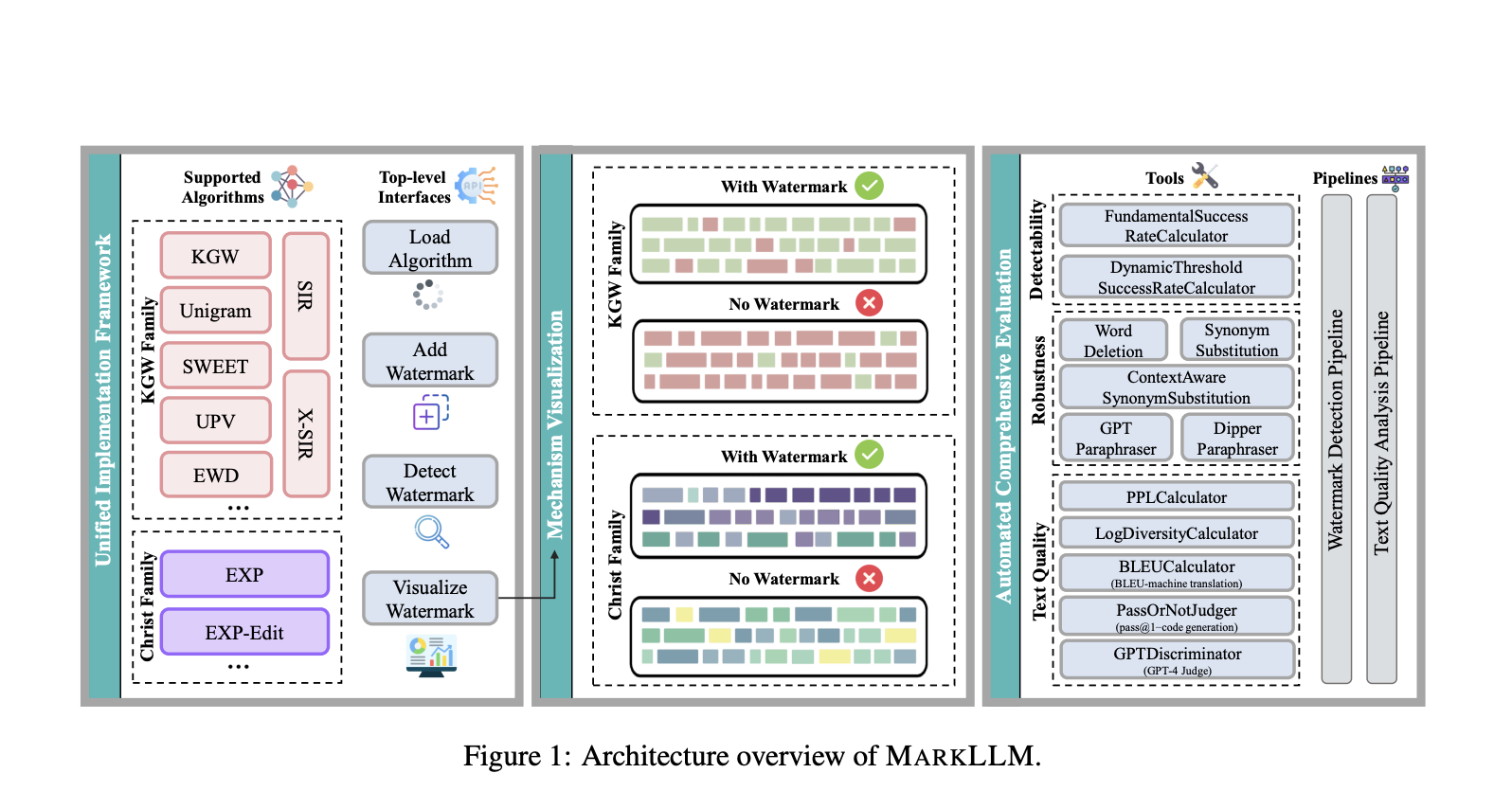
Исследователи из нескольких университетов создали MARKLLM – открытый набор инструментов для LLM-водяных знаков. Этот инструментарий предоставляет единый и расширяемый фреймворк для реализации алгоритмов водяных знаков, поддерживая девять конкретных методов из двух основных семейств алгоритмов. Он предлагает удобный интерфейс для загрузки алгоритмов, водяных знаков в текст, обнаружения и визуализации данных. Инструментарий включает 12 инструментов для оценки и два автоматизированных алгоритма для оценки обнаружимости водяных знаков, их устойчивости и влияния на качество текста. Модульное строение MARKLLM повышает масштабируемость и гибкость, что делает его ценным ресурсом для исследователей и общественности для продвижения технологии LLM-водяных знаков.
Категории алгоритмов LLM-водяных знаков
Алгоритмы LLM-водяных знаков делятся на две основные категории: семейство KGW и семейство Christ. Метод KGW изменяет LLM-логиты для предпочтения определенных токенов, создавая текст с водяным знаком, который определяется статистическим порогом. Вариации этого метода улучшают производительность, уменьшают влияние на качество текста, увеличивают вместимость водяного знака, устойчивы к атакам на удаление и позволяют общественное обнаружение. Семейство Christ использует псевдослучайные последовательности для направления выборки токенов, с методами, такими как EXP-sampling, коррелирующими текст с этими последовательностями для обнаружения. Оценка алгоритмов водяных знаков включает в себя оценку обнаружимости, устойчивости к подделке и влияния на качество текста с использованием метрик, таких как перплексия и разнообразие.
Устранение проблем с помощью MARKLLM
MARKLLM предоставляет единый фреймворк для решения проблем с алгоритмами LLM-водяных знаков, включая отсутствие стандартизации, унификации и качества кода. Он позволяет легко вызывать и переключаться между алгоритмами, предлагая хорошо спроектированную структуру классов. MARKLLM включает модуль визуализации алгоритмов семейств KGW и Christ, выделяя предпочтения токенов и корреляции. Инструментарий включает 12 инструментов оценки и два автоматизированных алгоритма для оценки обнаружимости водяных знаков, их устойчивости и влияния на качество текста. Инструментарий поддерживает гибкие конфигурации, упрощая тщательные и автоматизированные оценки алгоритмов водяных знаков с использованием различных метрик и сценариев атак.
Оценка результатов и перспективы
Используя MARKLLM, было проведено оценивание девяти алгоритмов водяных знаков на обнаружимость, устойчивость и влияние на качество текста. Для общего создания текста использовался набор данных C4, для машинного перевода – WMT16, для генерации кода – HumanEval. OPT-1.3b и Starcoder служили в качестве языковых моделей. Для оценки использовались динамическая корректировка порога и различные атаки на текст, среди метрик были PPL, лог-разнообразие, BLEU, pass@1 и GPT-4 Judge. Результаты показали высокую точность обнаружения, индивидуальные сильные стороны алгоритмов и различные результаты в зависимости от метрик и атак. Удобный дизайн MARKLLM облегчает всеобъемлющие оценки, предлагая ценные идеи для дальнейших исследований.
В заключение, MARKLLM – это открытый набор инструментов, созданный для LLM-водяных знаков, предлагающий гибкие конфигурации для различных алгоритмов, водяного знаков в тексте, обнаружения и визуализации. Он включает удобные инструменты оценки и настраиваемые алгоритмы для тщательной оценки с разных точек зрения. Хотя он поддерживает только часть методов, исключая недавние подходы к встраиванию водяных знаков в параметры модели, ожидается, что будущие вклады расширят его возможности. Предоставляемые инструменты визуализации полезны, но могли бы быть более разнообразными. Кроме того, хотя он охватывает ключевые аспекты оценки, некоторые сценарии, такие как атаки ретрансляции и CWRA, все еще требуют полного рассмотрения. Разработчиков и исследователей призывают вносить свой вклад в устойчивость и гибкость MARKLLM.
“`









