«`html
Искусственный интеллект в медицинской диагностике: балансировка производительности и справедливости среди населения
По мере того, как модели искусственного интеллекта все более интегрируются в клиническую практику, оценка их производительности и потенциальных предубеждений в отношении различных демографических групп становится крайне важной. Глубокое обучение достигло значительных успехов в задачах медицинского изображения, однако исследования показывают, что эти модели часто наследуют предубеждения от данных, что приводит к неравенству в производительности среди различных подгрупп. Например, классификаторы рентгеновских снимков грудной клетки могут недооценивать состояния у чернокожих пациентов, что потенциально замедляет необходимый уход. Понимание и устранение этих предубеждений является ключевым для этичного использования этих моделей.
Недавние исследования выявляют неожиданную способность глубоких моделей точнее предсказывать демографическую информацию, такую как раса, пол и возраст, по медицинским изображениям, чем радиологи. Это вызывает опасения, что модели предсказания заболеваний могут использовать демографические особенности как вводные данные — корреляции в данных, которые не имеют клинического значения, но могут влиять на предсказания.
Исследование в журнале Nature Medicine
В недавней статье, опубликованной в известном журнале Nature Medicine, авторы исследования изучили, как демографические данные могут быть использованы в качестве вводных данных моделями классификации заболеваний в медицинском ИИ, что потенциально приводит к предвзятому результату. В этом исследовании авторы пытались ответить на несколько важных вопросов: оно исследует, приводит ли использование демографических особенностей в процессе предсказания этих алгоритмов к несправедливым результатам. Оно оценивает, насколько эффективно существующие техники могут избавиться от этих предубеждений и предоставить справедливые модели. Кроме того, исследование изучает поведение этих моделей в сценариях смещения реальных данных и определяет критерии и методы, которые могут гарантировать справедливость.
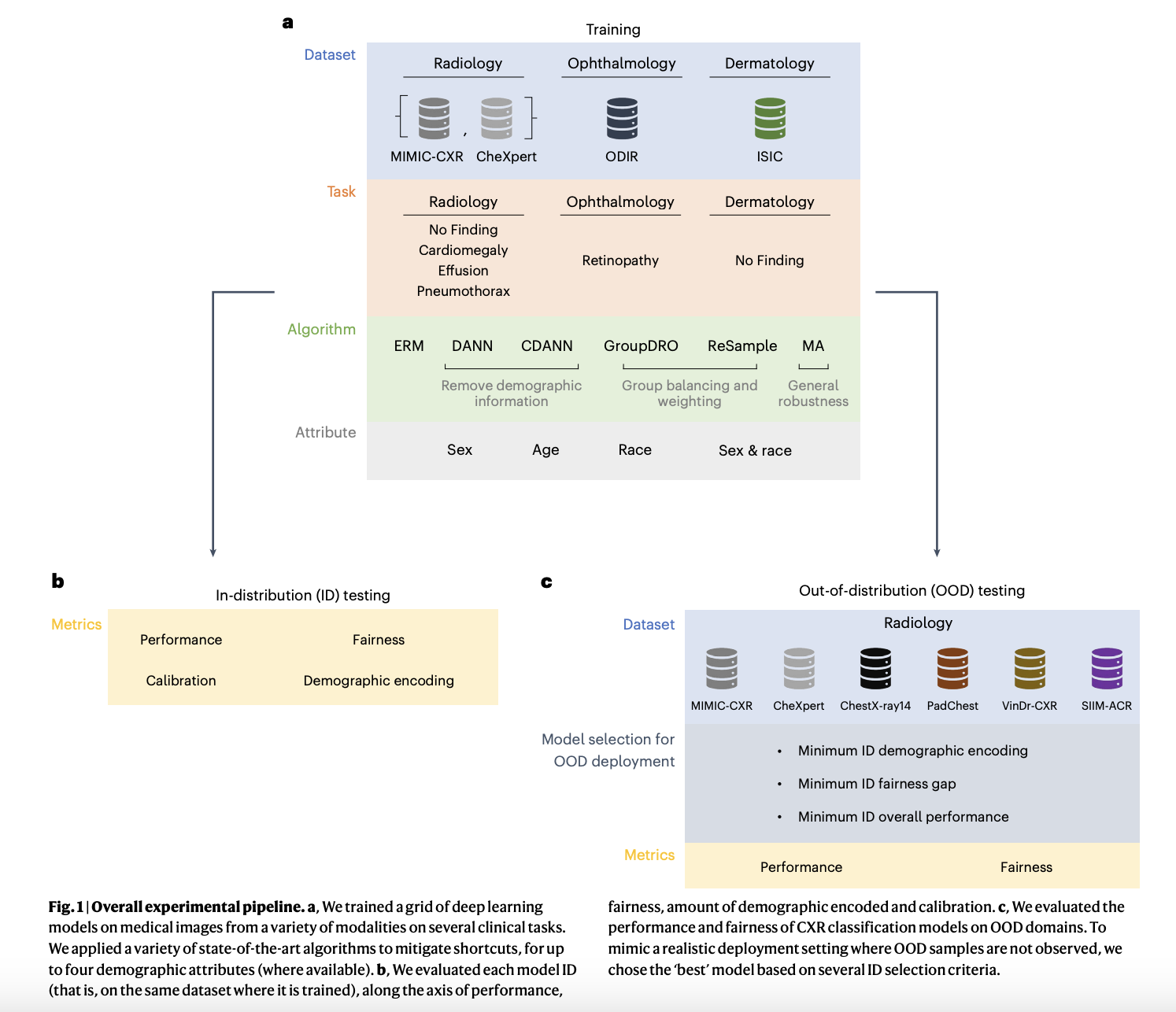
Исследовательская группа провела эксперименты для оценки производительности и справедливости медицинских ИИ моделей среди различных демографических групп и модальностей. Они сосредоточились на бинарных классификационных задачах, связанных с рентгеновскими снимками грудной клетки, включая категории, такие как «Нет патологии», «Эффузия», «Пневмоторакс» и «Кардиомегалия», используя наборы данных, такие как MIMIC-CXR и CheXpert. Задачи дерматологии использовали набор данных ISIC для классификации «Нет патологии», в то время как задачи офтальмологии были оценены с использованием набора данных ODIR, специально нацеленного на «Ретинопатию». Метриками для оценки справедливости были ложноположительные (FPR) и ложноотрицательные (FNR) рейты, акцентируя взвешенные шансы для измерения неравенства производительности среди демографических подгрупп. В исследовании также исследовалось, как кодирование демографических данных влияет на справедливость модели и анализировались сдвиги распределения между внутригрупповыми (ID) и внегрупповыми (OOD) настройками. Ключевые результаты показали, что неравенства в справедливости сохранялись в различных настройках, и улучшения в справедливости внутригрупповых настроек не всегда переводились в лучшую справедливость внегрупповых настроек. Исследование подчеркнуло критическую необходимость надежных техник устранения предубеждений и всесторонней оценки для обеспечения справедливого развертывания ИИ.
Из экспериментов авторы выяснили, что кодирование демографических особенностей может действовать как «вводные данные» и значительно влиять на справедливость, особенно при сдвигах распределения. Их анализ показал, что удаление этих «вводных данных» может улучшить справедливость внутригрупповых настроек, но не обязательно переводится в лучшую справедливость внегрупповых настроек. Исследование выявило компромисс между справедливостью и другими клинически значимыми метриками, и справедливость, достигнутая внутригрупповыми настройками, может не сохраняться в внегрупповых сценариях. Авторы предложили начальные стратегии для диагностики и объяснения изменений в справедливости модели при сдвигах распределения и предложили, что надежные критерии выбора моделей являются важными для обеспечения справедливости в внегрупповых настройках. Они подчеркнули необходимость непрерывного мониторинга ИИ моделей в клинических средах для решения проблем снижения справедливости и вызова предположения о единой справедливой модели во всех настройках. Кроме того, авторы обсудили сложность включения демографических особенностей, подчеркнув, что в то время как некоторые из них могут быть причинными факторами для определенных заболеваний, другие могут быть косвенными заместителями, требующими тщательного рассмотрения при развертывании модели. Они также отметили ограничения текущих определений справедливости и побудили практиков выбирать метрики справедливости, соответствующие их конкретным случаям использования, учитывая как компромиссы между справедливостью и производительностью.
В заключение, крайне важно столкнуться и понять предубеждения, которые могут приобрести модели ИИ из обучающих данных по мере их все более интегрируются в клиническую практику. Исследование подчеркивает, насколько сложно сохранить производительность, обеспечивая при этом справедливость, особенно при обработке вариаций распределения между обучением и реальными настройками. Для обеспечения доверия и справедливости ИИ систем крайне важно использовать эффективные стратегии устранения предубеждений, непрерывный мониторинг и тщательный выбор моделей. Кроме того, сложность демографических характеристик в предсказании заболеваний подчеркивает необходимость сложного подхода к справедливости, где разрабатываются модели, которые не только технически хороши, но и морально правильны и настраиваются для реальных клинических сред.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram каналу и группе LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 48 тыс. ML SubReddit
Найдите предстоящие вебинары по ИИ здесь
Arcee AI выпустила DistillKit: открытый и простой в использовании инструмент для трансформации модельного сжатия для создания эффективных малых языковых моделей
Подробнее оригинальную статью можно найти на MarkTechPost.
«`

























