Улучшение качества обучающих наборов данных для языковых моделей
Курирование данных является ключевым этапом в разработке высококачественных обучающих наборов для языковых моделей. Этот процесс включает в себя такие техники, как удаление дубликатов, фильтрация и смешивание данных, которые повышают эффективность и точность моделей. Цель — создать наборы данных, улучшающие производительность моделей в различных задачах, от понимания естественного языка до сложного рассуждения.
Проблемы и решения в области курирования данных
Одной из значительных проблем при обучении языковых моделей является необходимость в стандартизированных показателях для стратегий курирования данных. Это затрудняет определение, улучшения производительности модели обусловлены лишь лучшим курированием данных или другими факторами, такими как архитектура модели или гиперпараметры. Существующие методы курирования данных включают удаление дубликатов, фильтрацию и использование модельных подходов для создания обучающих наборов. Однако эффективность этих стратегий существенно различается, и необходимо достичь согласия относительно наиболее эффективного подхода для курирования обучающих данных для языковых моделей.
Новый подход к курированию данных: DataComp for Language Models (DCLM)
Команда исследователей из различных уважаемых институтов, включая Университет Вашингтона, Apple и Toyota Research Institute, представила новый рабочий процесс курирования данных под названием DataComp for Language Models (DCLM). Этот метод направлен на создание высококачественных обучающих наборов и установление показателя для оценки производительности набора данных. Этот междисциплинарный подход объединяет экспертизу из различных областей для решения сложной проблемы курирования данных для языковых моделей.
Ключевые шаги в рабочем процессе DCLM
Рабочий процесс DCLM включает несколько важных этапов. Вначале текст извлекается из исходного HTML с использованием Resiliparse, высокоэффективного инструмента для извлечения текста. Затем выполняется удаление дубликатов с использованием фильтра Блума для удаления избыточных данных, что помогает улучшить разнообразие данных и снизить запоминание в моделях. Затем применяется фильтрация на основе модели, которая использует классификатор fastText, обученный на высококачественных данных из источников, таких как OpenWebText2 и ELI5. Эти шаги критически важны для создания высококачественного обучающего набора данных, известного как DCLM-BASELINE. Тщательный процесс гарантирует, что в обучающем наборе содержатся только наиболее актуальные и высококачественные данные.
Результаты и перспективы
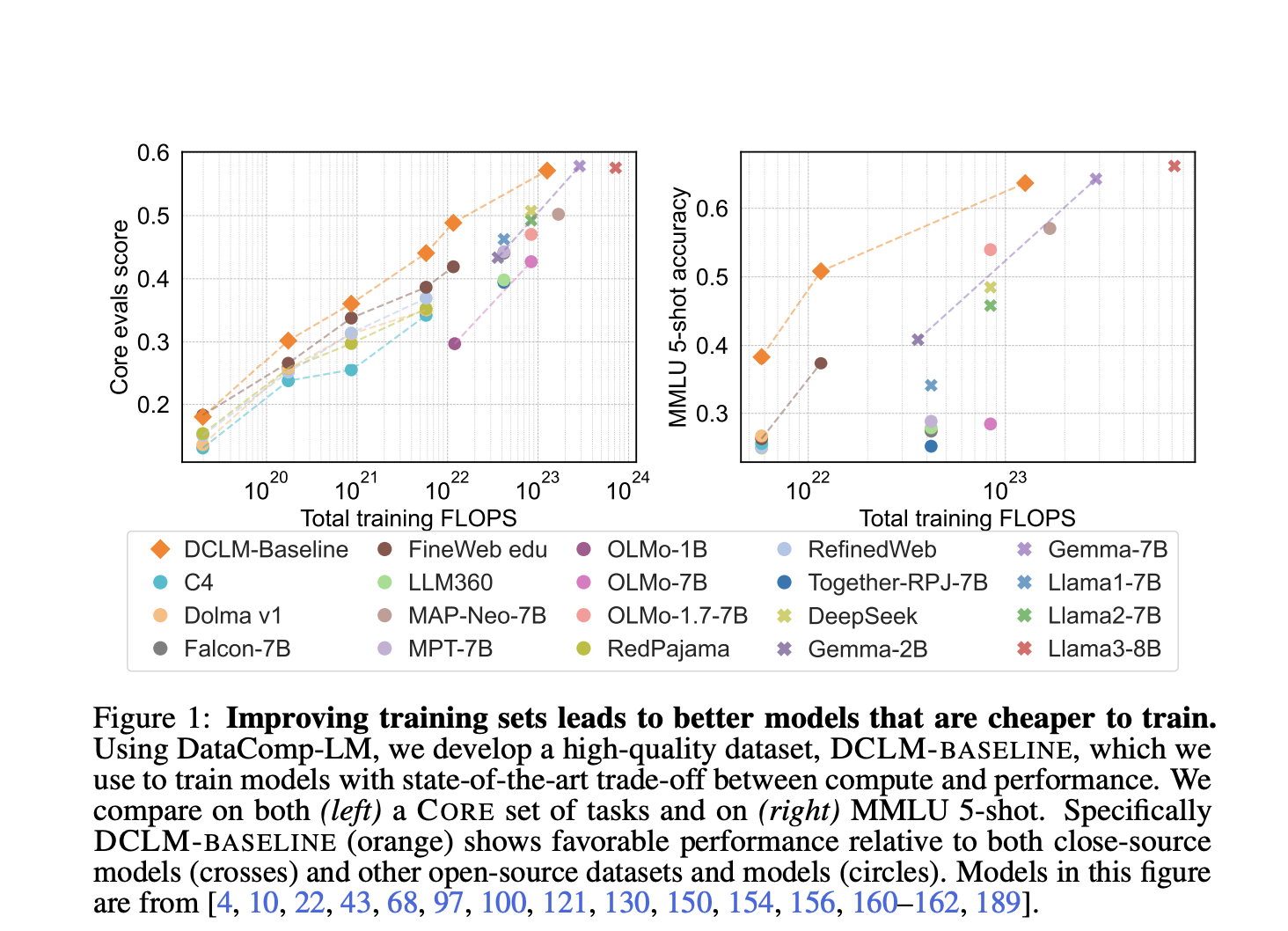
Обучающий набор данных DCLM-BASELINE продемонстрировал значительное улучшение производительности модели. При использовании для обучения языковой модели с 7 миллиардами параметров и 2,6 триллионами обучающих токенов, полученная модель достигла точности 5-shot на уровне 64% в MMLU. Это представляет собой существенное улучшение по сравнению с предыдущими моделями и подчеркивает эффективность метода DCLM в создании высококачественных обучающих наборов. Предложенный рабочий процесс DCLM устанавливает новый показатель для курирования данных в языковых моделях и предоставляет комплексную основу для оценки и улучшения обучающих наборов, что является важным для развития области языкового моделирования.
В заключение, рабочий процесс DCLM представляет собой мощное решение для улучшения качества наборов данных и производительности моделей. Этот подход устанавливает новый показатель для будущих исследований в области курирования данных и разработки языковых моделей. Коллективный характер этого исследования подчеркивает важность междисциплинарных подходов в решении сложных научных проблем. Этот инновационный рабочий процесс не только продвигает текущее состояние языкового моделирования, но также открывает путь для будущих улучшений в этой области.

























