«`html
Применение LLMClean: подход ИИ для автоматического создания контекстных моделей с использованием больших языковых моделей для анализа и понимания различных наборов данных
Расширение области данных, подталкиваемое Интернетом вещей (IoT), представляет собой насущную проблему: обеспечение качества данных в условиях потока информации. С увеличением взаимосвязи устройств IoT и снижением затрат на сбор данных предприятия используют этот богатый источник данных для принятия стратегических решений.
Однако качество этих данных имеет первостепенное значение, особенно в свете нарастающей зависимости от машинного обучения (ML) в различных отраслях. Некачественные обучающие данные могут привести к искажениям и неточностям, подрывая эффективность применения ML. Реальные данные часто содержат неточности, такие как дубликаты, пустые записи, аномалии и несоответствия, представляя существенные препятствия для качества данных.
Усилия по устранению проблем качества данных привели к разработке автоматизированных инструментов очистки данных. Однако многие из этих инструментов нуждаются в большем контекстном понимании, которое является ключевым для эффективной очистки данных в рамках рабочих процессов ML. Контекстная информация разъясняет значение, актуальность и взаимосвязи данных, обеспечивая их соответствие реальным явлениям.
Инструменты очистки данных, осведомленные о контексте, предлагают перспективы, используя онтологические функциональные зависимости (OFD), извлеченные из контекстных моделей. OFD обеспечивают продвинутый механизм захвата семантических взаимосвязей между атрибутами, улучшая точность обнаружения и исправления ошибок.
Несмотря на эффективность инструментов очистки на основе OFD, ручное создание контекстных моделей представляет практические сложности, особенно для приложений в реальном времени. Трудоемкий характер ручных методов, в сочетании с потребностью в предметной экспертизе и проблемами масштабируемости, подчеркивает необходимость автоматизации.
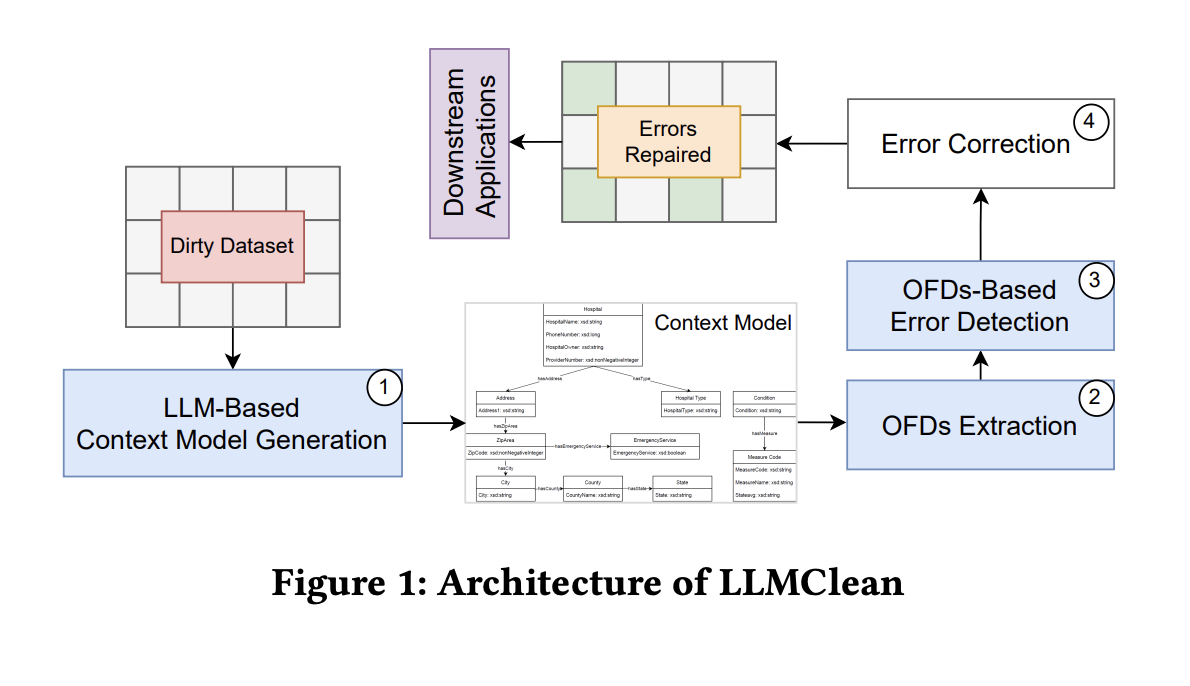
В ответ на это предлагаемое решение, LLMClean, использует большие языковые модели (LLM) для автоматического создания контекстных моделей из реальных данных, исключая необходимость в дополнительной мета-информации. Автоматизируя этот процесс, LLMClean решает проблемы масштабируемости, адаптируемости и последовательности, присущие ручным методам.
Архитектурная структура LLMClean включает три этапа: модели LLM, контекстные модели и инструменты очистки данных для эффективной идентификации ошибочных данных в табличных данных. Метод включает классификацию набора данных, извлечение или сопоставление модели и создание контекстной модели.
Используя автоматически сгенерированные OFD, LLMClean предоставляет надежную систему очистки данных и аналитики, адаптированную к изменяющейся природе реальных данных, включая наборы данных IoT. Кроме того, LLMClean вводит зависимости от возможностей сенсоров и зависимости от устройств, которые являются критическими для точного обнаружения ошибок.
Ознакомьтесь с документом. Вся благодарность за этот исследовательский проект принадлежит исследователям этого проекта.
Если вам нравится наша работа, вам понравится наш бюллетень.
Не забудьте присоединиться к нашему подразделению ML
Попробуйте ИИ ассистент в продажах здесь. Этот ИИ ассистент помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru
«`

























