WaveletGPT: Применение волнового преобразования для ускорения обучения LLM в различных областях
Большие языковые модели (LLM) революционизировали искусственный интеллект, оказывая влияние на различные научные и инженерные дисциплины. Архитектура Transformer, изначально созданная для машинного перевода, стала основой для моделей GPT, значительно продвигая эту область. Однако текущие LLM сталкиваются с вызовами в подходе к обучению, который в основном сосредоточен на предсказании следующего токена на основе предыдущего контекста при сохранении причинности. Этот простой метод был применен в различных областях, включая робототехнику, последовательности белков, аудиообработку и анализ видео.
Практические решения и ценность:
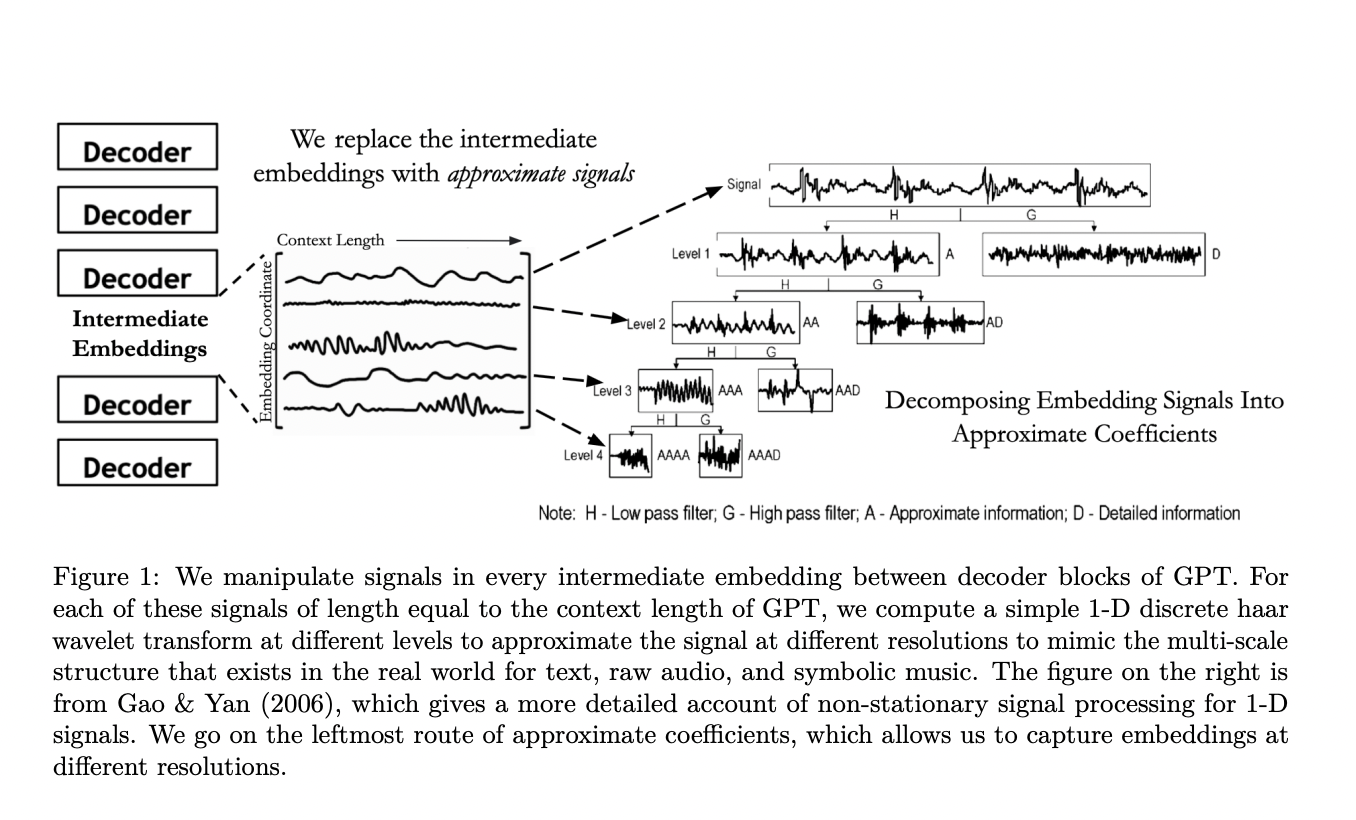
Исследователи из Стэнфорда предлагают первый пример внедрения волновых преобразований в LLM, WaveletGPT, для улучшения LLM путем внедрения волновых преобразований в их архитектуру. Эта техника добавляет многошкальные фильтры к промежуточным вложениям слоев декодера трансформера с использованием вейвлетов Хаара. Инновация позволяет каждому предсказанию следующего токена получать доступ к многошкальным представлениям на каждом уровне, вместо использования представлений с фиксированным разрешением.
Этот метод ускоряет предварительное обучение LLM на основе трансформера на 40-60% без добавления дополнительных параметров, что является значительным прорывом, учитывая широкое использование архитектур на основе декодера трансформера в различных модальностях. Подход также демонстрирует существенное улучшение производительности при том же количестве шагов обучения, сравнимое с добавлением нескольких слоев или параметров.
Операция на основе вейвлетов показывает увеличение производительности в трех различных модальностях: язык (текст-8), сырой звук (YoutubeMix) и символьная музыка (MAESTRO), подчеркивая ее универсальность для структурированных наборов данных.
Предложенный метод внедряет вейвлеты в LLM на основе трансформера, сохраняя предположение о причинности. Этот подход может быть применен к различным архитектурам, включая не трансформерные настройки. Техника сосредотачивается на манипулировании промежуточными вложениями из каждого слоя декодера.

























