Революция в области классификации текста с Political DEBATE Language Models
Классификация текста стала неотъемлемым инструментом в различных приложениях, включая анализ мнений и классификацию тематики. Ранее для этой задачи требовалась обширная ручная разметка и глубокое понимание методов машинного обучения, что создавало значительные преграды для вступления в эту область. Однако появление больших языковых моделей (LLM) типа ChatGPT революционизировало эту область, позволяя классификацию без дополнительного обучения. Этот прорыв привел к широкому использованию LLM в политических и социальных науках.
Преимущества Political DEBATE Language Models
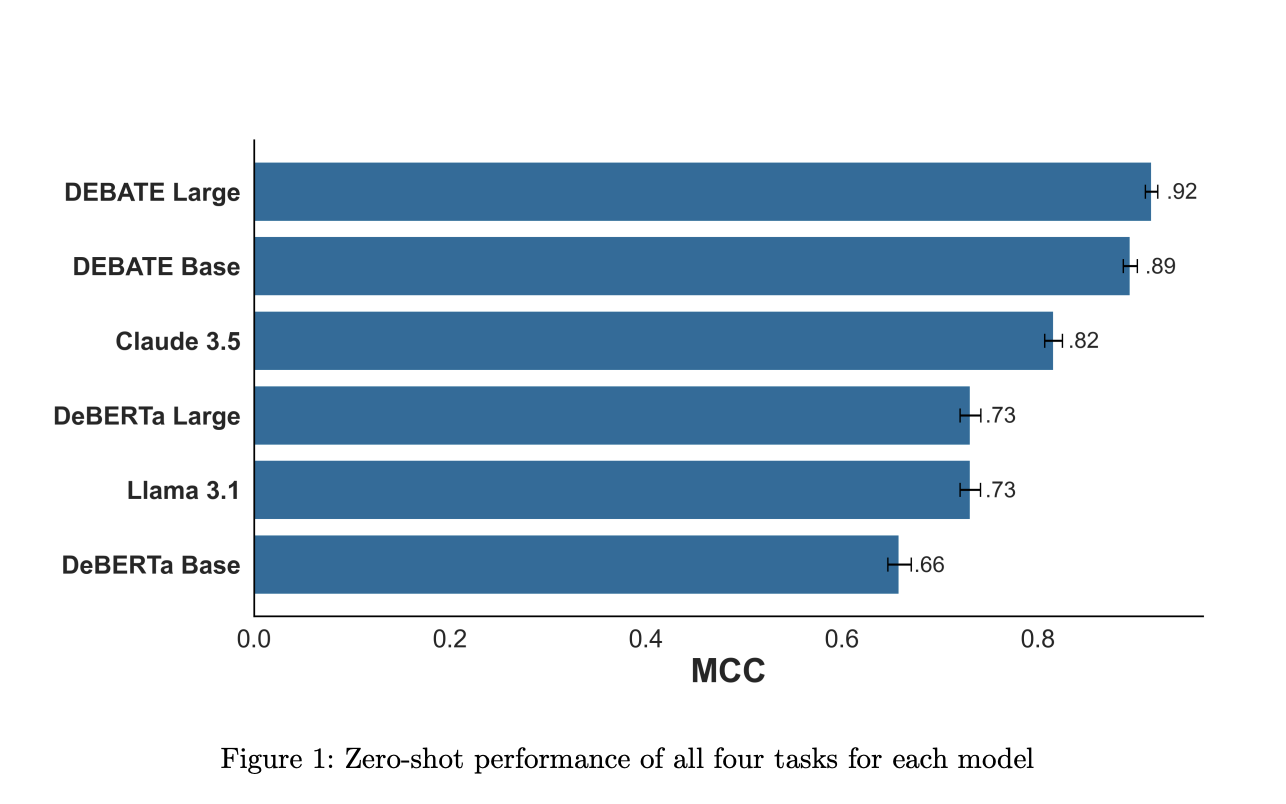
Модели Political DEBATE представляют собой значительное достижение в открытой классификации текста для политической науки. Они обеспечивают эффективную классификацию политического текста сравнимую с гораздо более крупными собственными моделями, при этом снижая вычислительные требования.
Эффективность Political DEBATE
Модели Political DEBATE показали впечатляющую эффективность в обучении новым задачам с использованием всего 10-25 случайно отобранных документов, превосходя или равняясь производительности специализированных моделей и крупных генеративных моделей.
Компановка моделей
Political DEBATE модели построены на базе моделей DeBERTa V3 base и large, что обеспечивает эффективное обучение на политических текстах. Они были протестированы и показали свою превосходную эффективность на различных аппаратных конфигурациях, демонстрируя значительное преимущество в скорости обработки по сравнению с другими моделями.
Анализ стоимости
Исследование показало, что Political DEBATE модели предлагают значительное преимущество в скорости обработки по сравнению с другими моделями на различных типах аппаратного обеспечения.
Заключение и перспективы
Political DEBATE модели представляют собой мощный инструмент для эффективного анализа текста в политической науке. Их использование поддерживает принципы открытой науки, предлагая воспроизводимую альтернативу собственным моделям. Будущие исследования должны сосредоточиться на расширении этих моделей на новые задачи и включении более разнообразных источников документов.

























