Исследование Массачусетского технологического института (MIT) рассматривает сложности обучения языковых моделей забывать: исследование метода случайного дообучения
Языковые модели (LMs) привлекли значительное внимание в последние годы благодаря своим выдающимся возможностям. В процессе обучения этих моделей сначала происходит предварительное обучение нейронных последовательностных моделей на большом, минимально обработанном тексте из Интернета, а затем они дообучаются, используя конкретные примеры и обратную связь людей.
Существующие попытки решения проблемы машинного «забывания» выросли из предыдущих методов, сосредоточенных на удалении нежелательных данных из обучающих наборов, к более продвинутым техникам. Однако большинство этих подходов имеют ограничения в выполнимости, обобщении или применимости к сложным моделям, таким как LLMs.
Исследователи из MIT предложили новый подход для изучения поведения обобщения при забывании навыков в LMs. Этот метод включает дообучение моделей на случайно размеченных данных для целевых задач, простой, но эффективный метод для вызывания забывания.
Результаты и выводы
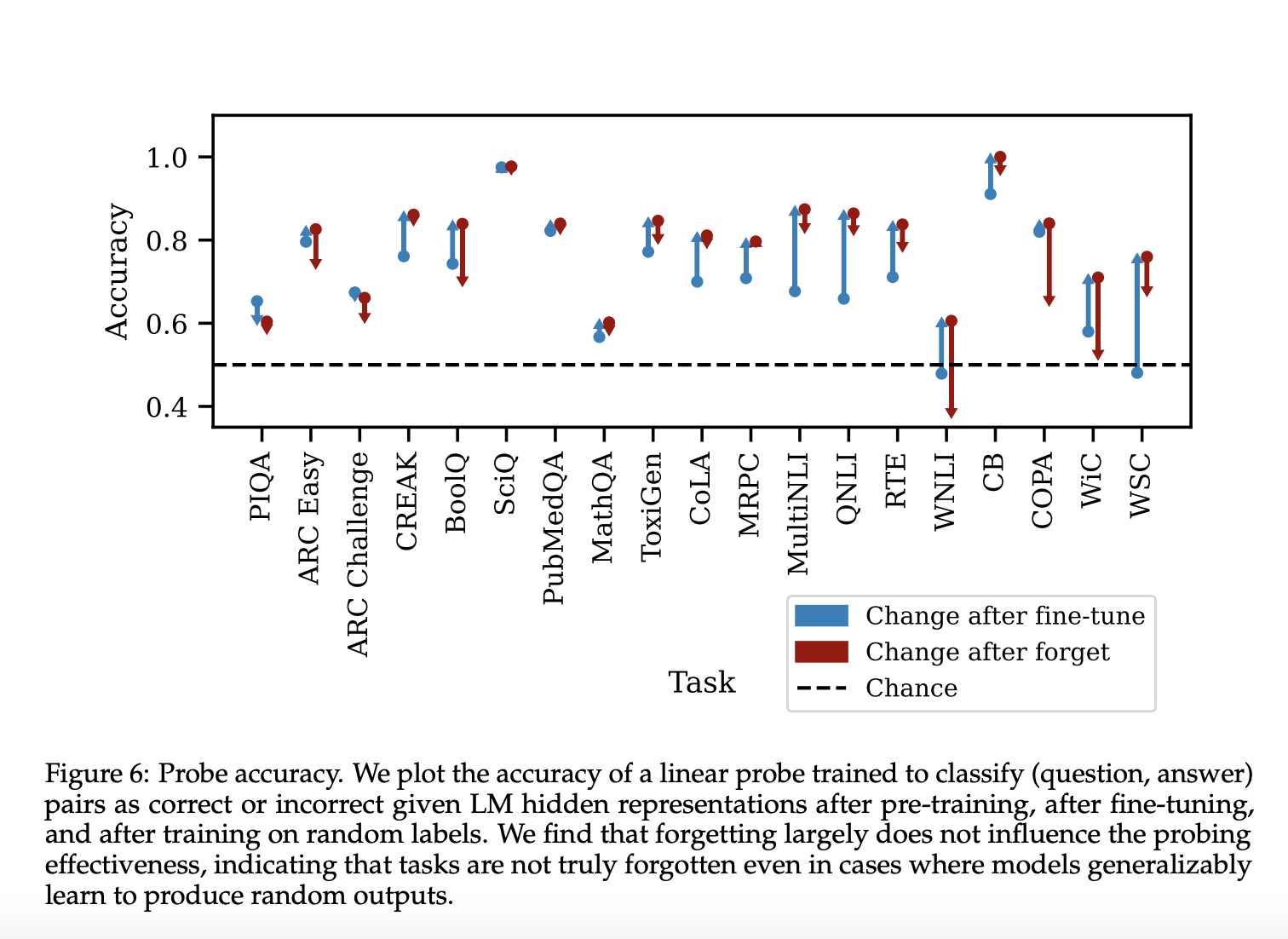
Результаты демонстрируют разнообразное поведение забывания в различных задачах. После дообучения точность теста увеличивается, хотя она может немного уменьшиться, поскольку набор проверки не идентичен набору теста. Забывание производит три различных категории поведения.
В заключение, исследователи из MIT представили подход для изучения поведения обобщения при забывании навыков в LMs. Эта статья подчеркивает эффективность дообучения LMs на случайных ответах для вызывания забывания конкретных навыков.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram.
Попробуйте ИИ ассистент в продажах здесь.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























