«`html
Потенциал самостоятельной игры для обучения языковых моделей в совместных задачах
Искусственный интеллект (ИИ) достиг значительных успехов благодаря агентам, играющим в игры, таким как AlphaGo, который достиг сверхчеловеческой производительности с помощью техник самостоятельной игры. Самостоятельная игра позволяет моделям улучшаться, обучаясь на данных, генерируемых из игр против себя, что оказалось эффективным в соревновательных средах, таких как Го и шахматы. Эта техника, которая ставит идентичные копии модели друг против друга, вывела возможности ИИ за рамки человеческой производительности в этих нулевых играх.
Применение в реальных задачах
Однако постоянным вызовом для ИИ является повышение производительности в сотрудничестве или частично сотрудничающих языковых задачах. В отличие от конкурентных игр, где цель очевидна, языковые задачи часто требуют сотрудничества и поддержания человеческой интерпретируемости. Вопрос заключается в том, может ли самостоятельная игра, успешная в соревновательных средах, быть адаптирована для улучшения языковых моделей в задачах, где сотрудничество с людьми необходимо. Это включает в себя обеспечение эффективного общения ИИ и понимание тонкостей человеческого языка без отклонения от естественных, похожих на человеческие стратегий коммуникации.
Практические решения и ценность
Существующие исследования включают модели, такие как AlphaGo и AlphaZero, использующие самостоятельную игру для конкурентных игр. Сотруднические диалоговые задачи, такие как Cards, CerealBar, OneCommon и DialOp, оценивают модели в совместных средах с использованием самостоятельной игры в качестве замены для человеческой оценки. Торговые игры, такие как DoND и Craigslist Bargaining, проверяют возможности моделей в переговорах. Однако эти фреймворки часто сталкиваются с проблемами поддержания интерпретируемости человеческого языка и неспособностью эффективно обобщать стратегии в смешанных сотруднических и конкурентных средах, что ограничивает их применимость в реальном мире.
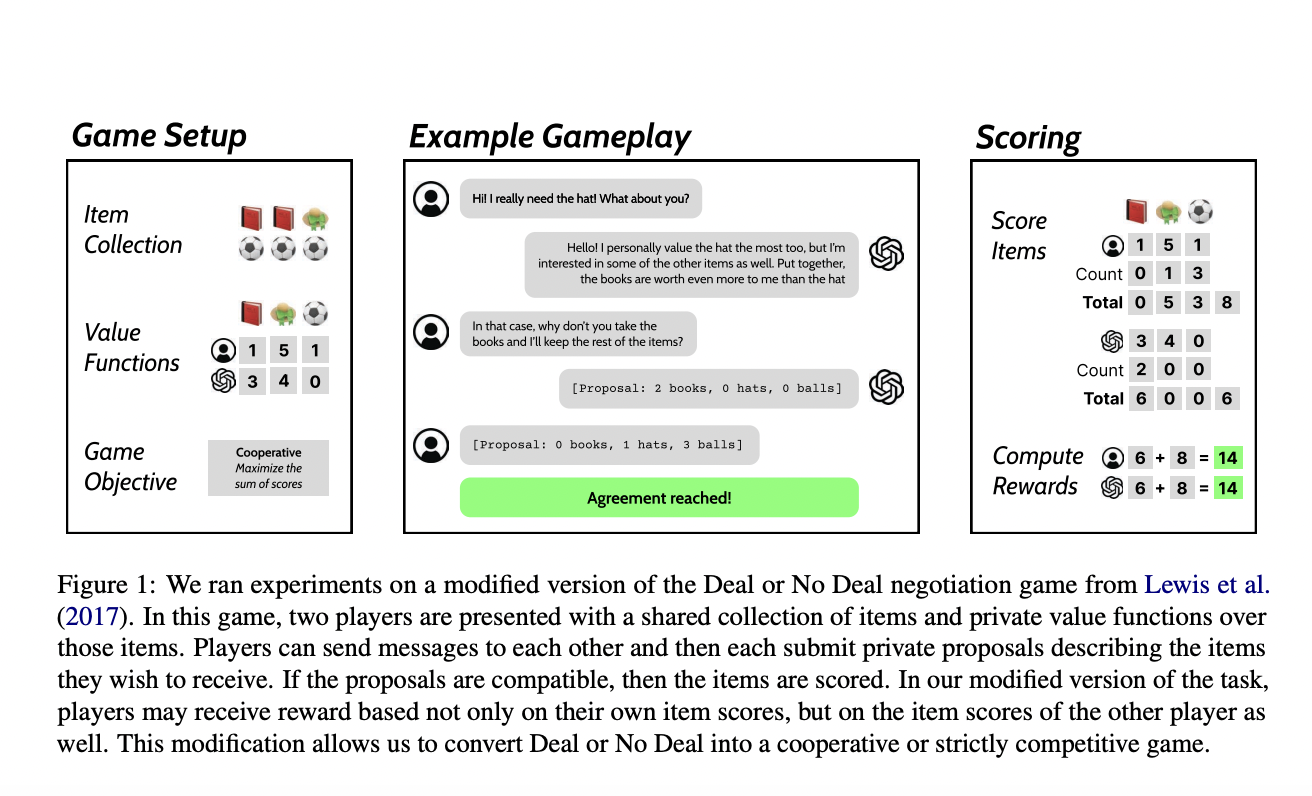
Исследователи из Университета Калифорнии, Беркли, предложили новый подход для тестирования самостоятельной игры в сотруднических и конкурентных средах с использованием модифицированной версии торговой игры «Deal or No Deal» (DoND). Эта игра, изначально полуконкурентная, была адаптирована для поддержки различных целей, что делает ее подходящей для оценки улучшений языковых моделей на разных уровнях сотрудничества. Путем модификации структуры вознаграждения игра могла имитировать полностью кооперативные, полуконкурентные и строго конкурентные среды, предоставляя универсальное поле для обучения ИИ.
В модифицированной игре DoND два игрока ведут переговоры о разделе предметов с частными функциями стоимости. Игра адаптируется к кооперативным, полуконкурентным или конкурентным средам. Исследователи использовали фильтрованное клонирование поведения для обучения самостоятельной игре. Два идентичных языковых модели играли 500 игр в каждом раунде за десять раундов, и высокооцененные диалоги использовались для доработки. Исходные модели, включая GPT-3.5 и GPT-4, были оценены без нескольких образцов, чтобы избежать предвзятости. Подобно среде OpenAI Gym управляли правилами игры, обработкой сообщений и вознаграждениями. На Amazon Mechanical Turk были проведены человеческие эксперименты с предварительно отобранными работниками для проверки производительности модели.
Обучение самостоятельной игре привело к значительному улучшению производительности. В кооперативных и полуконкурентных средах модели показали существенный прирост, причем баллы увеличились до 2,5 раза в кооперативных и до шести раз в полуконкурентных сценариях по сравнению с исходными показателями. В частности, модели, обученные в кооперативной среде, улучшились с 0,7 до 12,1, а в полуконкурентной среде баллы увеличились с 0,4 до 5,8. Это демонстрирует потенциал самостоятельной игры для улучшения способности языковых моделей сотрудничать и конкурировать эффективно с людьми, что указывает на то, что эти техники могут быть адаптированы для более сложных задач в реальном мире.
Несмотря на многообещающие результаты в сотруднических и полуконкурентных средах, строго конкурентная среда представляла некоторые вызовы. Улучшения были минимальными, что указывает на то, что модели часто склонны к переобучению во время самостоятельной игры. В этой среде модели часто боролись с обобщением своих стратегий, не смогли достичь соглашений с другими агентами, такими как GPT-4. Предварительные человеческие эксперименты также показали, что эти модели редко достигали соглашений, что подчеркивает сложность применения самостоятельной игры в нулевых сценариях, где важны надежные и обобщаемые стратегии.
В заключение, данное исследование, проведенное командой Университета Калифорнии, Беркли, подчеркивает потенциал самостоятельной игры для обучения языковых моделей в сотруднических задачах. Полученные результаты оспаривают устоявшееся предположение о том, что самостоятельная игра неэффективна в сотрудничающих областях или что модели нуждаются в обширных данных от людей для поддержания интерпретируемости языка. Вместо этого значительные улучшения, наблюдаемые всего лишь после десяти раундов самостоятельной игры, указывают на то, что языковые модели с хорошими способностями к обобщению могут извлечь пользу из этих техник. Это может привести к более широкому применению самостоятельной игры за пределами конкурентных игр, потенциально улучшая производительность ИИ в различных сотруднических и реальных задачах.
«`

























