“`html
Исследование Стэнфордских ученых: Генерация социальных сетей LLM и предвзятость в политической гомофилии
Генерация социальных сетей находит широкое применение в различных областях, таких как моделирование эпидемий, симуляции социальных медиа и понимание социальных явлений, таких как поляризация. Создание реалистичных социальных сетей критично, когда реальные сети не могут быть прямо наблюдаемы из-за ограничений конфиденциальности или других ограничений. Эти сгенерированные сети важны для точного моделирования взаимодействий и прогнозирования результатов в этих контекстах.
Основные проблемы и решения
Основной вызов в генерации социальных сетей – это балансирование реализма и адаптивности. Традиционные подходы, такие как модели глубокого обучения, обычно требуют обширного обучения на сетях, специфичных для области. Эти модели нуждаются в помощи в обобщении к новым сценариям, где данные могут быть ограничены или недоступны. В то же время классические модели, такие как модели Эрдёша-Реньи и модели малого мира, полагаются на жесткие предположения о формировании сети, что часто не удается уловить сложные динамики реальных социальных взаимодействий.
Текущие методы генерации сетей включают комбинацию техник глубокого обучения и классических статистических моделей. Модели глубокого обучения мощны, но требуют больших наборов данных для обучения, что ограничивает их применимость в ситуациях, где такие данные недоступны. С другой стороны, классические модели, хотя более гибкие в отношении требований к данным, часто упрощают формирование социальных сетей.
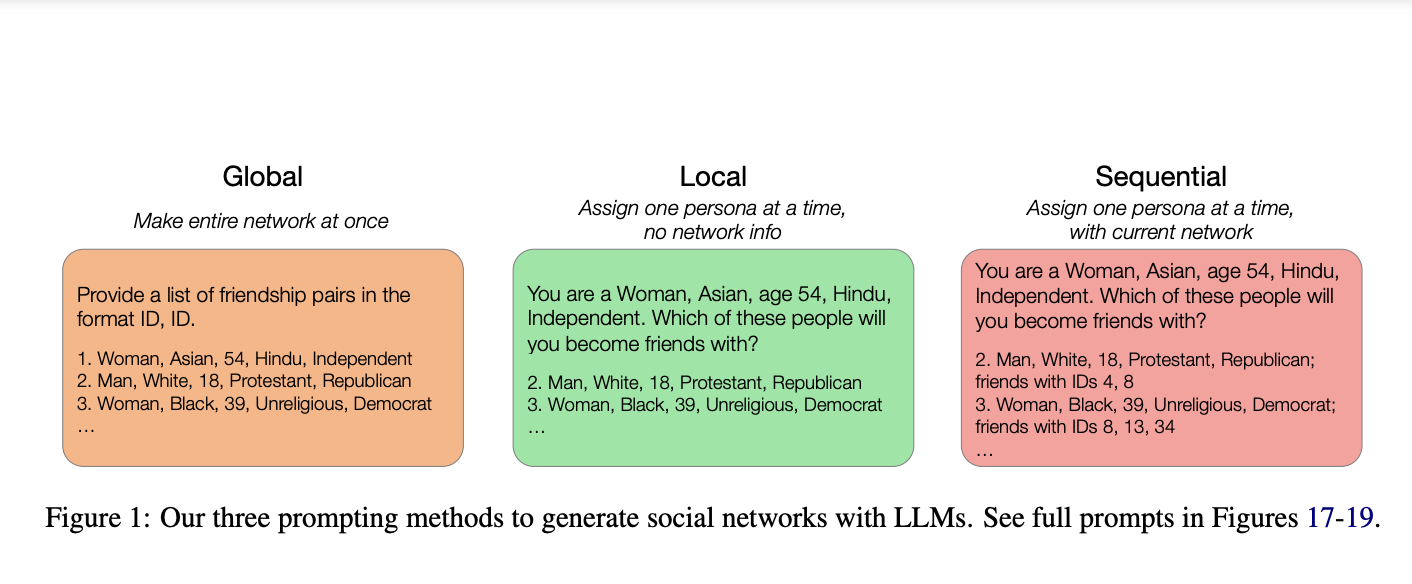
Исследователи из Стэнфордского университета, Университета Калифорнии и Корнеллского университета предложили инновационный подход, используя большие языковые модели (LLM) для генерации социальных сетей. Они использовали эти возможности для создания сетей на основе естественноязыковых описаний людей, предлагая гибкое и масштабируемое решение для преодоления многих ограничений традиционных моделей.
Оценка результатов
Результаты показали, что методы “Local” и “Sequential” производили сети, которые тесно соответствовали структурным характеристикам реальных социальных сетей. Особенно метод “Sequential” смог воспроизвести распределение степеней, являющееся ключевой особенностью реальных социальных сетей, где у некоторых людей значительно больше связей, чем у других.
Однако исследование также выявило значительное искажение в сгенерированных сетях: LLM переоценивали политическую гомофилию. Сети проявляли более высокий уровень кластеризации по политическим взглядам, чем обычно наблюдается в реальных социальных сетях.
Выводы
Исследование демонстрирует потенциал использования LLM для генерации социальных сетей, предлагая гибкий подход к созданию реалистичных сетей и преодолевая многие ограничения традиционных методов. Однако оно также подчеркивает необходимость борьбы с предвзятостями в сгенерированных сетях, особенно в отношении политической принадлежности.
“`









