“`html
Интеграция мульти-модальных генеративных моделей: практические решения
Мульти-модальные генеративные модели интегрируют различные типы данных, такие как текст, изображения и видео, расширяя применение ИИ в различных областях. Оптимизация этих моделей представляет сложные задачи, связанные с обработкой данных и обучением моделей. Однако необходимость согласованных стратегий для улучшения как данных, так и моделей критически важна для достижения выдающейся производительности ИИ.
Проблема и решение
Один из крупных проблем в разработке мульти-модальных генеративных моделей заключается в изолированном развитии подходов, ориентированных на данные и на модели. Исследователи часто сталкиваются с трудностями при интеграции обработки данных и обучения моделей, что приводит к неэффективности и неоптимальным результатам. Данное разделение затрудняет возможность одновременного усовершенствования данных и моделей, что является важным для улучшения возможностей ИИ.
Текущие методы разработки мульти-модальных генеративных моделей обычно сосредоточены либо на улучшении алгоритмов и архитектур моделей, либо на совершенствовании техник обработки данных. Эти методы работают независимо друг от друга, полагаясь на эвристические подходы и человеческую интуицию. В результате они лишены системного руководства для совместной оптимизации данных и моделей, что ведет к фрагментированным и менее эффективным усилиям по разработке.
Решение Alibaba Group
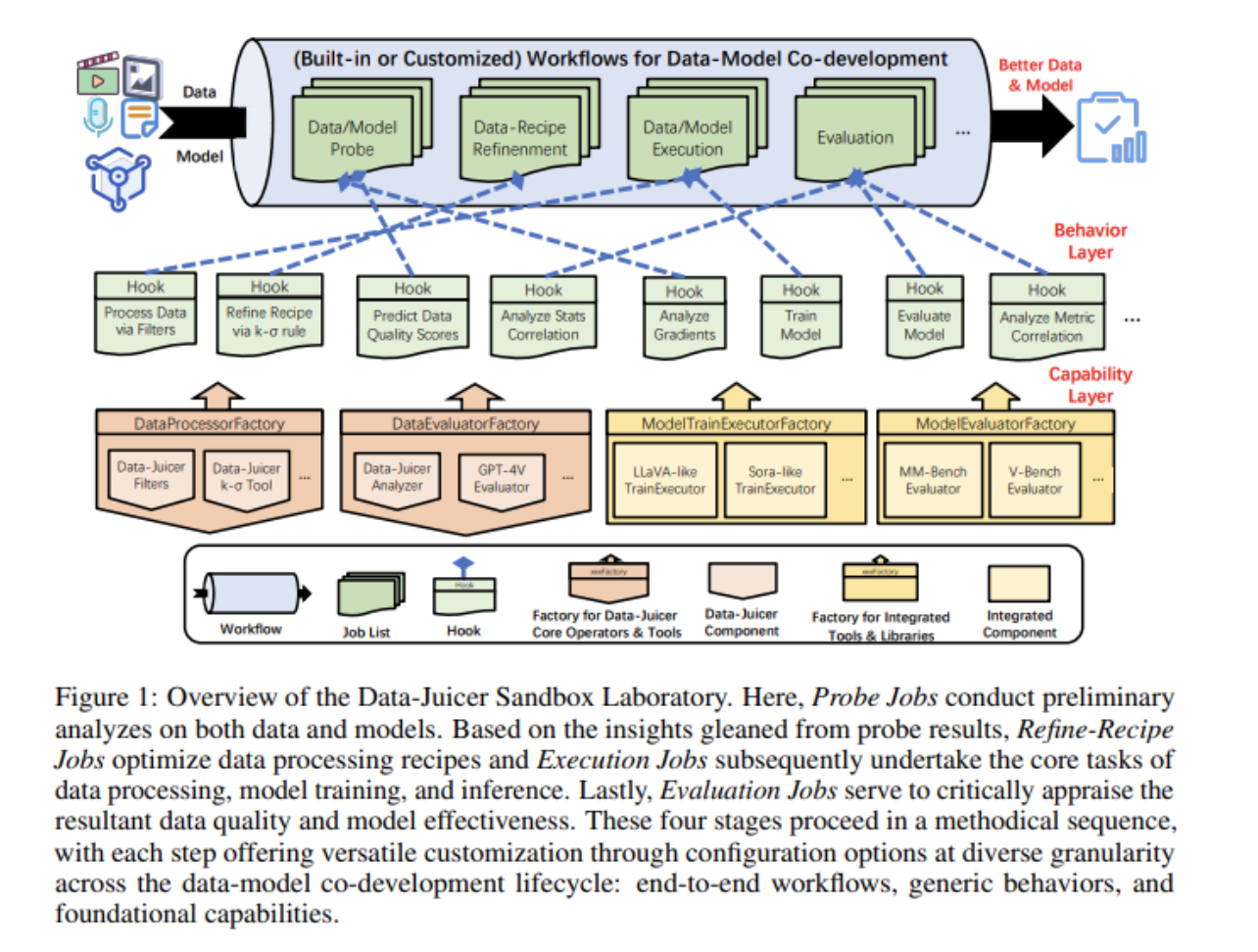
Исследователи из Alibaba Group представили Data-Juicer Sandbox – открытую платформу для совместной разработки мульти-модальных данных и генеративных моделей, объединяющую различные настраиваемые компоненты. Она предлагает гибкую платформу для системного изучения и оптимизации, устраняя разрыв между обработкой данных и обучением моделей. Этот набор инструментов разработан для упрощения процесса разработки и усиления синергии между данными и моделями.
При использовании Data-Juicer Sandbox применяется рабочий процесс “Probe-Analyze-Refine”, позволяющий исследователям систематически тестировать и усовершенствовать различные операторы обработки данных (OPs) и конфигурации моделей. Этот метод включает создание равных по размеру данных, каждый из которых обрабатывается уникальным OP. Модели обучаются на этих данных, что позволяет проводить глубокий анализ эффективности OP и его корреляции с производительностью модели по различным количественным и качественным показателям. Такой систематический подход улучшает как качество данных, так и производительность моделей, предоставляя ценные исследования сложной взаимосвязи между предварительной обработкой данных и поведением модели.
В своей методологии исследователи реализовали иерархическую пирамиду данных, классифицируя данные на основе ранжированных метрических показателей модели. Это стратификация помогает выявить наиболее эффективные OP, которые затем объединяются в рецепты данных и масштабируются. Путем поддержания однородных гиперпараметров и использования экономичных стратегий, таких как уменьшение масштабов данных и ограничение числа итераций обучения, исследователи обеспечили эффективный и экономически обоснованный процесс разработки. Совместимость данного набора инструментов с существующей инфраструктурой, ориентированной на модели, делает его универсальным инструментом для развития ИИ.
Data-Juicer Sandbox достиг значительного улучшения производительности в нескольких задачах. Для генерации текста изображений средняя производительность на TextVQA, MMBench и MME увеличилась на 7,13%. В задаче генерации текста в видео с использованием модели EasyAnimate, песочница заняла первое место в рейтинге VBench, опередив сильных конкурентов. Эксперименты также продемонстрировали увеличение эстетических показателей на 59,9% и улучшение языковых показателей на 49,9% при использовании высококачественных наборов данных. Эти результаты подчеркивают эффективность песочницы в оптимизации мульти-модальных генеративных моделей.
Более того, песочница облегчила практическое применение в двух различных сценариях: генерации текста изображений и текста в видео. В задаче генерации текста изображений с использованием модели Mini-Gemini, песочница достигла первоклассной производительности в понимании содержания изображений. В задаче генерации текста в видео модель EasyAnimate продемонстрировала способность песочницы создавать видеоролики высокого качества по текстовым описаниям. Эти приложения отражают универсальность и эффективность песочницы в усилении совместной разработки мульти-модальных данных и моделей.
Завершение
Песочница Data-Juicer решает критическую проблему интеграции обработки данных и обучения моделей в мульти-модальных генеративных моделях. Предоставляя систематическую и гибкую платформу для совместной разработки, она позволяет исследователям достичь значительных улучшений в производительности ИИ. Этот инновационный подход представляет собой значительное развитие в области ИИ, предлагая всестороннее решение для преодоления вызовов оптимизации мульти-модальных генеративных моделей.
“`









