“`html
Мультиязычная обработка естественного языка (NLP)
Мультиязычная обработка естественного языка (NLP) – это быстро развивающаяся область, которая стремится разработать языковые модели, способные понимать и генерировать текст на нескольких языках. Эти модели облегчают эффективное общение и доступ к информации среди разноязычных пользователей. Важность этой области заключается в ее потенциале устранить разрыв между носителями разных языков, сделав технологические достижения в области ИИ доступными по всему миру. Однако разработка таких моделей представляет существенные трудности из-за сложностей одновременной обработки нескольких языков.
Проблемы и решения
Одной из основных проблем в мультиязычной NLP является преобладающее внимание к нескольким крупным языкам, таким как английский и китайский. Это узкое концентрация приводит к значительному разрыву в производительности моделей при применении к менее распространенным языкам. Решение этой проблемы требует инновационных подходов к улучшению качества и разнообразия мультиязычных наборов данных, гарантируя, что модели ИИ могут эффективно работать на широком спектре языков.
Традиционные методы улучшения мультиязычных языковых моделей часто включают перевод предпочтительных данных с английского на другие языки. Хотя эта стратегия в некоторой степени помогает, она вносит несколько проблем, включая переводные артефакты, которые могут ухудшить производительность модели. Сбор высококачественных мультиязычных предпочтительных данных через человеческую аннотацию является потенциальным решением, но это дорого и затратно по времени, что делает его непрактичным для масштабных приложений.
Исследователи из Cohere For AI разработали новый масштабируемый метод для генерации высококачественных мультиязычных предпочтительных данных. Этот метод стремится сбалансировать охват данных и улучшить производительность крупных мультиязычных языковых моделей (LLMs). Исследовательская группа представила уникальный подход, использующий разнообразные мультиязычные подсказки и завершения, сгенерированные несколькими LLMs. Эта стратегия не только увеличивает разнообразие данных, но также помогает избежать распространенных проблем, связанных с переводными артефактами.
Результаты и выводы
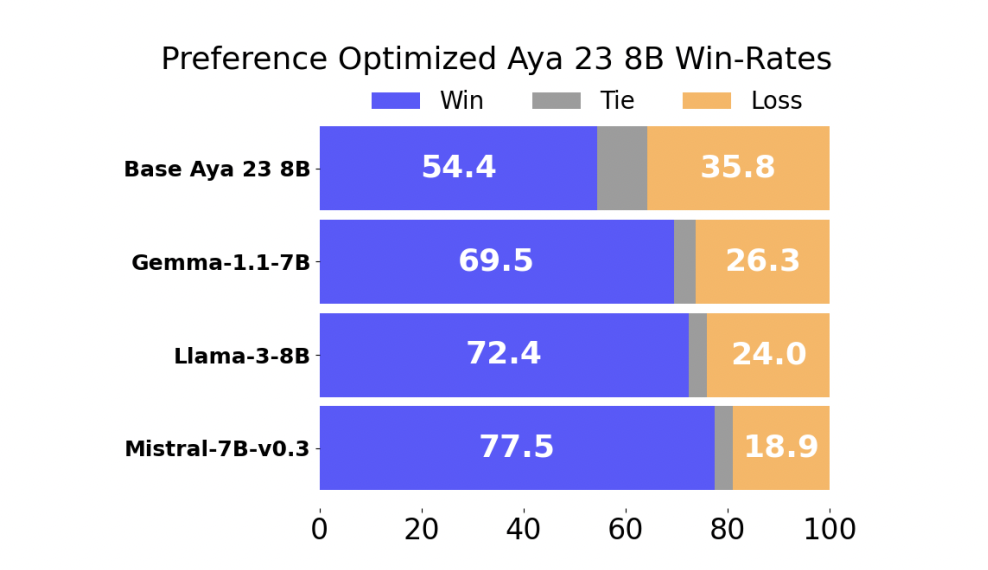
Эффективность модели, обученной на предпочтительных данных, была оценена по сравнению с несколькими передовыми мультиязычными LLMs. Результаты были впечатляющими, с моделью, обученной на предпочтительных данных, достигшей победы в 54,4% случаев против Aya 23 8B, ведущей на данный момент мультиязычной LLM в своем классе параметров. Кроме того, модель показала победу в 69,5% случаев или более против других широко используемых моделей, таких как Gemma-1.1-7B-it, Meta-Llama3-8B-Instruct и Mistral-7B-Instruct-v0.3. Эти результаты подчеркивают эффективность подхода исследователей в улучшении производительности мультиязычных LLMs через улучшенную оптимизацию предпочтительных данных.
Дополнительный анализ показал, что увеличение числа языков в обучающих данных последовательно улучшало производительность модели. Например, обучение на пяти языках привело к победе в 54,9% случаев на невидимых языках, по сравнению с 46,3%, когда обучение происходило только на английском. Более того, онлайн-методы оптимизации предпочтительных данных, такие как обучение с подкреплением от человеческой обратной связи (RLHF), оказались более эффективными, чем офлайн-методы, такие как прямая оптимизация предпочтительных данных (DPO). Онлайн-техники достигли более высоких побед, причем RLOO превзошел DPO с отрывом в 10,6% в некоторых случаях.
В заключение, проведенное исследование Cohere For AI демонстрирует критическую важность высококачественных, разнообразных, мультиязычных данных при обучении эффективных мультиязычных языковых моделей. Инновационные методы, представленные исследовательской группой, решают проблемы нехватки данных и их качества, что приводит к улучшению производительности на широком спектре языков. Это исследование не только устанавливает новый стандарт для мультиязычной оптимизации предпочтительных данных, но также подчеркивает ценность онлайн-методов обучения для достижения превосходного кросс-языкового трансфера и общей производительности модели.
“`


























