Исследование ИИ от Google DeepMind: разрыв в производительности между онлайн и оффлайн методами выравнивания ИИ
RLHF — стандартный подход для выравнивания LLMs. Однако недавние достижения в оффлайн методах выравнивания, таких как прямая оптимизация предпочтений (DPO) и его варианты, вызывают сомнения в необходимости онлайн-политики в RLHF. Оффлайн методы, которые выравнивают LLMs, используя существующие наборы данных без активного онлайн-взаимодействия, показали практическую эффективность и являются более простыми и дешевыми в реализации. Это поднимает вопрос о том, необходим ли онлайн RL для выравнивания ИИ. Сравнение онлайн и оффлайн методов сложно из-за их различных вычислительных требований, что требует тщательной калибровки бюджета, затраченного на измерение производительности.
Онлайн и оффлайн методы выравнивания
Исследователи из Google DeepMind продемонстрировали, что онлайн методы превосходят оффлайн методы в своих первоначальных экспериментах, что привело к дальнейшему изучению этого разрыва в производительности. Через контролируемые эксперименты они обнаружили, что факторы, такие как охват и качество оффлайн данных, должны полностью объяснять расхождение. В отличие от онлайн методов, оффлайн методы отлично справляются с попарной классификацией, но нуждаются в помощи в генерации. Разрыв сохраняется независимо от типа функции потерь и масштабирования модели. Это указывает на то, что онлайн-политика является ключевой для выравнивания ИИ, подчеркивая сложности оффлайн выравнивания.
Сравнение производительности методов
Исследование дополняет предыдущую работу по RLHF, сравнивая онлайн и оффлайн алгоритмы RLHF. Исследователи выявили устойчивый разрыв в производительности между онлайн и оффлайн методами, даже при использовании различных функций потерь и масштабирования сетей политики. В то время как предыдущие исследования отмечали сложности в оффлайн RL, их результаты подчеркивают, что они распространяются и на RLHF.
Использование IPO потерь
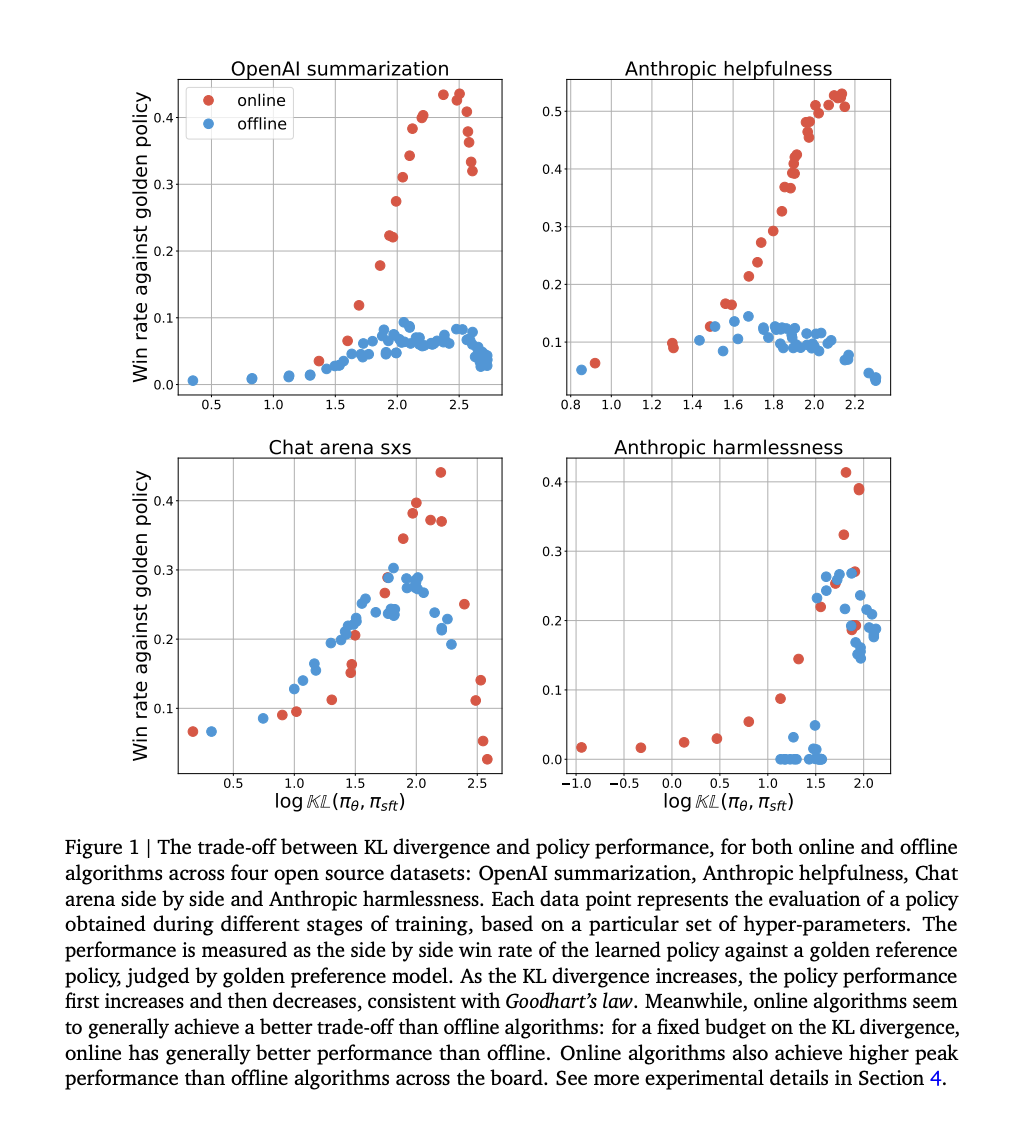
Исследование сравнивает онлайн и оффлайн методы выравнивания с использованием IPO потерь на различных наборах данных, изучая их производительность в рамках закона Гудхарта. IPO потери включают оптимизацию веса победных ответов над проигрышными, причем различия в процессах выборки определяют онлайн и оффлайн методы. Эксперименты показывают, что онлайн алгоритмы достигают лучших компромиссов между KL-дивергенцией и производительностью, более эффективно используя KL-бюджет и достигая более высокой пиковой производительности.
Гипотезы и заключение
Гипотеза предполагает, что разрыв в производительности между онлайн и оффлайн алгоритмами может быть частично объяснен точностью классификации модели предпочтений по сравнению с самой политикой. В заключение, исследование подчеркивает критическую роль онлайн-политики в эффективном выравнивании LLMs и выявляет сложности, связанные с оффлайн подходами. Оно опровергло несколько распространенных убеждений о разрыве в производительности между онлайн и оффлайн алгоритмами через тщательные эксперименты и проверку гипотез. Исследователи подчеркивают важность генерации данных онлайн для повышения эффективности обучения политики. Однако они также утверждают, что оффлайн алгоритмы могут улучшиться, принимая стратегии, имитирующие процессы онлайн обучения.

























