«`html
Автоматизированный процесс генерации разнообразных и проверяемых наборов данных для вызова функций API
Модели вызова функций агентов, представляющие значительный прогресс в рамках моделей обработки больших языковых корпусов (LLM), сталкиваются с проблемой необходимости высококачественных, разнообразных и проверяемых наборов данных. Эти модели интерпретируют естественно-языковые инструкции для выполнения вызовов API, что критически важно для мгновенного взаимодействия с различными цифровыми сервисами. Однако существующие наборы данных часто не обладают полной проверкой и разнообразием, что приводит к неточностям и неэффективности. Преодоление этих препятствий имеет важное значение для надежного внедрения агентов вызова функций в реальные приложения, такие как получение данных с фондового рынка или управление взаимодействием в социальных медиа.
Практические решения и ценность
Текущие методы обучения агентов вызова функций полагаются на статические наборы данных, которые не проходят тщательной проверки. Это часто приводит к недостаточным наборам данных, когда модели сталкиваются с новыми или невидимыми API, серьезно ограничивая их адаптивность и производительность. Например, модель, обученная в основном на API для бронирования ресторанов, может испытывать трудности с задачами, такими как получение данных с фондового рынка из-за нехватки соответствующих обучающих данных, что подчеркивает необходимость более надежных наборов данных.
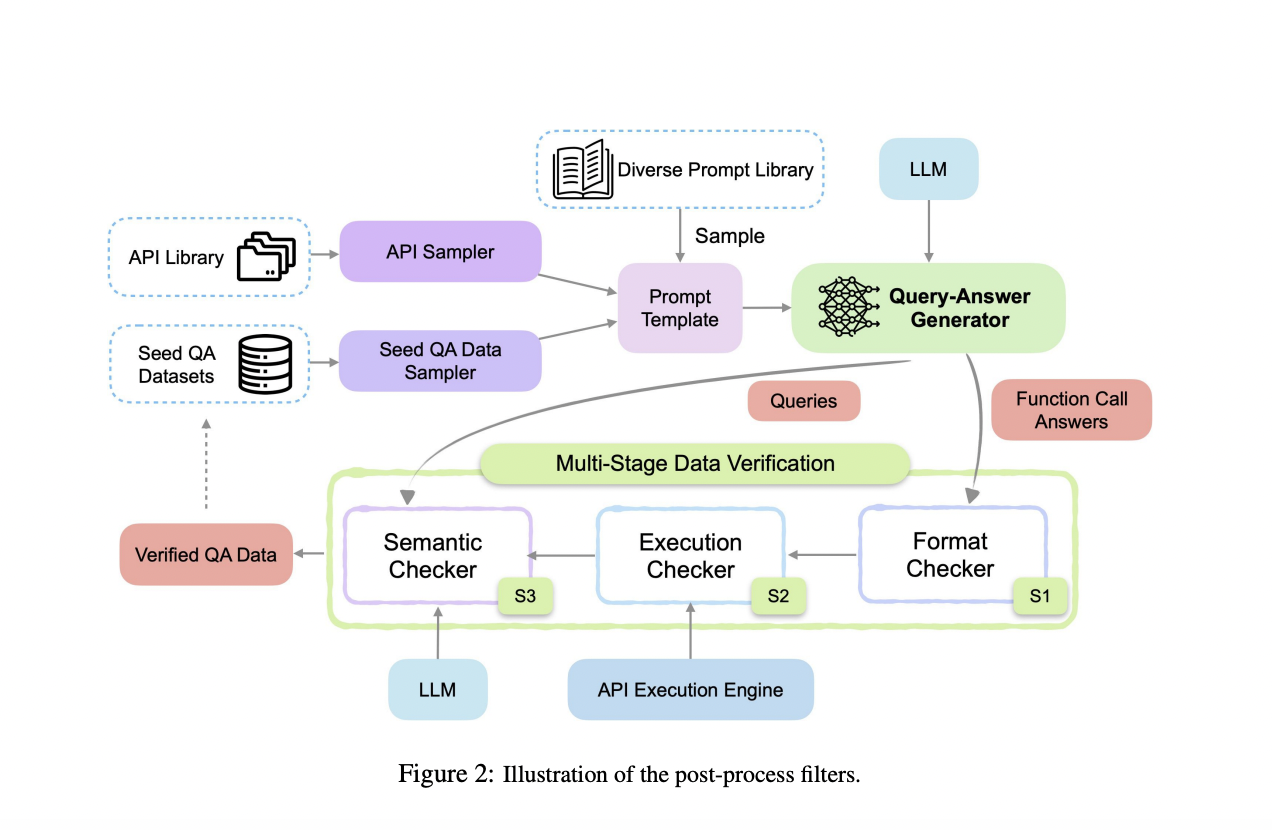
Исследователи из Salesforce AI Research предлагают APIGen, автоматизированный конвейер, предназначенный для генерации разнообразных и проверяемых наборов данных для вызова функций. APIGen решает ограничения существующих методов путем включения многоуровневого процесса проверки, обеспечивая надежность и правильность данных. Этот инновационный подход включает три иерархических этапа: проверка формата, фактическое выполнение функций и семантическая проверка. Тщательно проверяя каждую точку данных, APIGen производит высококачественные наборы данных, которые значительно улучшают обучение и производительность моделей вызова функций.
Процесс генерации данных APIGen начинается с выборки API и примеров запросов-ответов из библиотеки, форматируя их в стандартный JSON-формат. Затем конвейер использует многоуровневый процесс проверки. Этап 1 включает проверку формата, которая обеспечивает правильную структуру JSON. Этап 2 выполняет вызовы функций для проверки их операционной правильности. Этап 3 использует семантический проверятор для обеспечения соответствия между вызовами функций, результатами выполнения и целями запроса. Этот процесс приводит к обширному набору данных из 60 000 высококачественных записей, охватывающих 3673 API в 21 категории, доступных на Huggingface.
Наборы данных APIGen значительно улучшили производительность моделей, достигнув передовых результатов на бенчмарке Berkeley Function-Calling. Особенно модели, обученные с использованием этих наборов данных, превзошли несколько моделей GPT-4, демонстрируя значительное улучшение точности и эффективности. Например, модель с всего 7 млрд параметров достигла точности 87,5%, превзойдя предыдущие передовые модели с большим отрывом. Эти результаты подчеркивают надежность и надежность наборов данных, сгенерированных с помощью APIGen, в улучшении возможностей агентов вызова функций.
В заключение исследователи представляют APIGen, новую концепцию для генерации высококачественных и разнообразных наборов данных для вызова функций, решая критическую проблему в исследованиях по искусственному интеллекту. Предложенный многоуровневый процесс проверки обеспечивает надежность и правильность данных, значительно улучшая производительность модели. Наборы данных, сгенерированные с помощью APIGen, позволяют даже небольшим моделям достигать конкурентоспособных результатов, продвигая область агентов вызова функций. Этот подход открывает новые возможности для разработки эффективных и мощных языковых моделей, подчеркивая важность высококачественных данных в исследованиях по искусственному интеллекту.
«`

























