Обзор проблемы обучения с подкреплением
Обучение с подкреплением (RL) широко используется, но сталкивается с трудностями, которые мешают пользователям полностью использовать его потенциал. Например, алгоритмы такие как PPO требуют много примеров для изучения базовых действий, что называется неэффективностью выборки.
Решения и преимущества
Методы Off-Policy, такие как SAC и DrQ, более эффективны, но требуют множества наград, что ограничивает их производительность в условиях нехватки наград. Простые схемы исследования, такие как ε-гриди и исследование Болтцмана, хотя и удобны, не всегда оптимальны.
Потенциал внутреннего исследования
Недавние исследования показывают, что внутренние награды, такие как получение информации и любопытство, могут улучшить исследование агентов RL. Подходы, направленные на максимизацию получения информации, показывают хорошие результаты.
MAXINFORL: Новая парадигма
Исследователи из ETH Цюрих и UC Беркли представили MAXINFORL, который улучшает старые методы исследования, сочетая их с внутренними наградами. Эта новая группа алгоритмов Off-Policy предназначена для непрерывных пространств состояния и действий, предлагая направленное исследование.
MAXINFORL использует стандартный метод исследования Болтцмана и улучшает его с помощью внутренней награды, упрощая баланс между исследованием и наградами. Алгоритмы, модифицированные с помощью MAXINFORL, исследуют пространства, получая максимальную информацию при решении задач.
Основные особенности MAXINFORL
MAXINFORL применяет внутренние награды для упрощения процесса исследования. Вместо случайной выборки, исследования направляются к слабо изученным областям. Это позволяет улучшить эффективность и скорость выполнения задач.
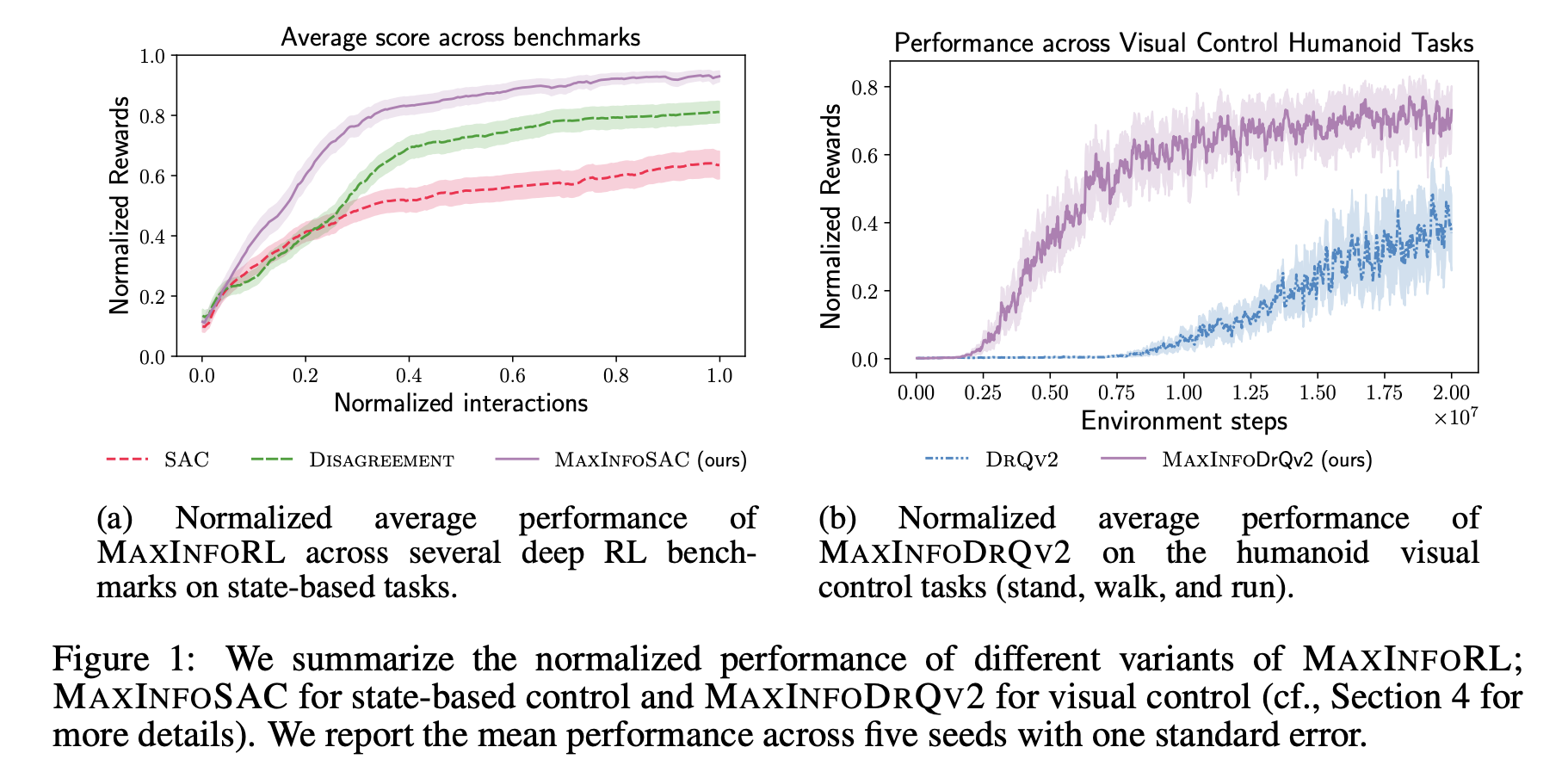
Проверка алгоритма
Исследователи проверили MAXINFORL на различных задачах глубокого RL и оценили его производительность по сравнению с другими методами. MAXINFORL показал лучшие результаты, даже в сложных для изучения условиях.
Выводы
MAXINFORL продемонстрировал, как можно улучшить простые методы исследования, достигая внутренних наград. Он превзошел другие методы в ряде задач. Тем не менее, обучение нескольких моделей может создавать дополнительную нагрузку на вычислительные ресурсы.
Применение AI в вашем бизнесе
Если вы хотите, чтобы ваша компания использовала искусственный интеллект, проанализируйте, как AI может изменить вашу работу. Определите, где возможно применение автоматизации и какие ключевые показатели эффективности можно улучшить.
Подберите подходящее AI-решение и внедряйте его постепенно, начиная с небольших проектов. На основе полученных данных расширяйте автоматизацию.
Если нужны советы по внедрению AI, напишите нам.
Попробуйте AI-ассистент в продажах, который поможет отвечать на вопросы клиентов и снижать нагрузку на первую линию.
Узнайте, как AI может улучшить ваши бизнес-процессы с решениями от Flycode.ru.

























