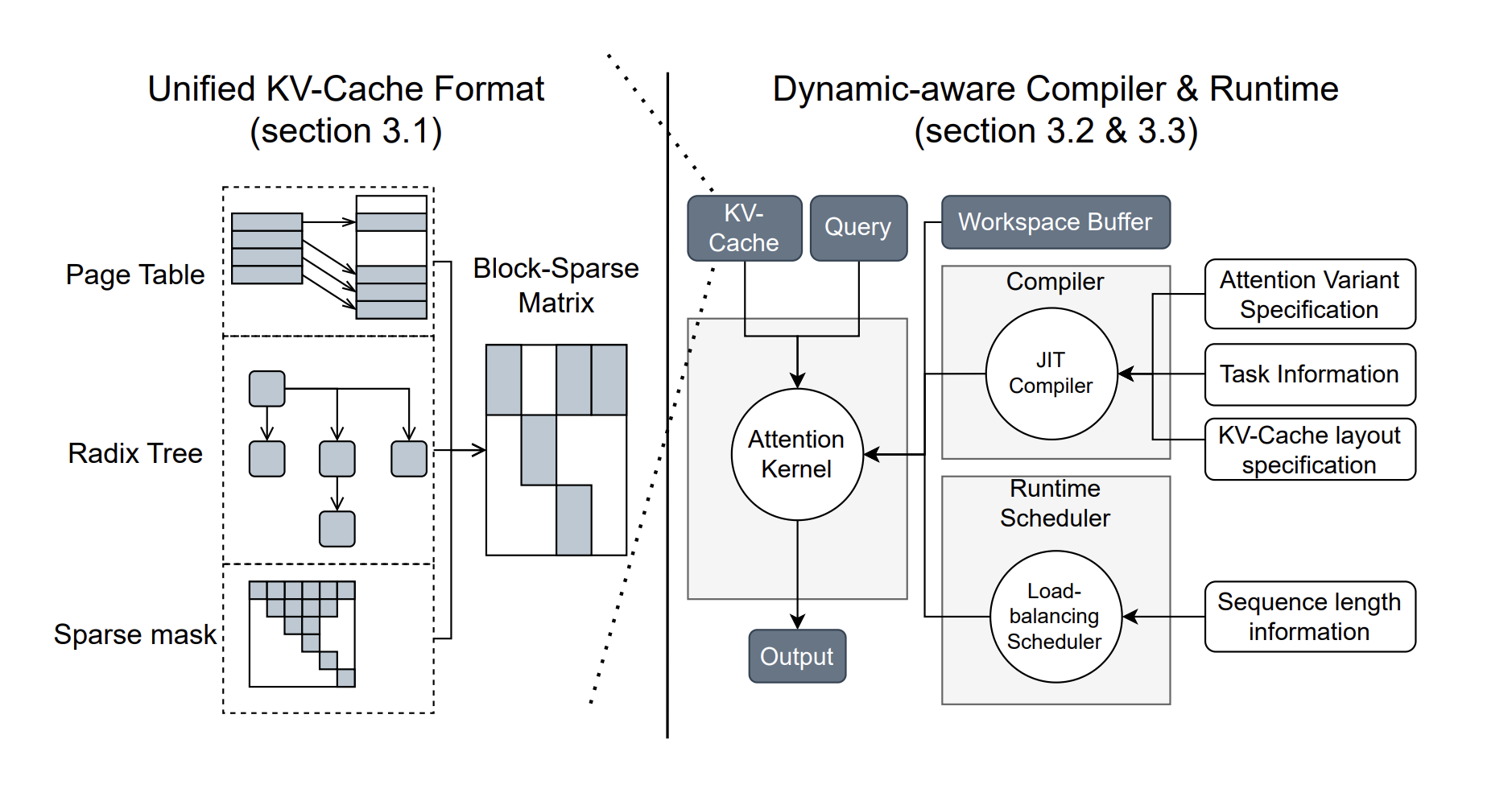
Введение в FlashInfer
Большие языковые модели (LLMs) играют важную роль в современных приложениях искусственного интеллекта, таких как чат-боты и генераторы кода. Однако, с ростом их использования стали проявляться недостатки в процессе обработки данных. Специальные механизмы внимания, такие как FlashAttention и SparseAttention, сталкиваются с проблемами производительности из-за разнообразных нагрузок и ограничений ресурсов.
Решение от FlashInfer
Исследователи из Университета Вашингтона, NVIDIA, Perplexity AI и Университета Карнеги Меллон разработали FlashInfer — библиотеку и генератор ядров, специализированный для обработки LLM. FlashInfer предлагает высокопроизводительные реализации ядров для различных механизмов внимания, включая FlashAttention и SparseAttention, что позволяет существенно повысить быстродействие.
Ключевые функции и преимущества
- Современные ядра внимания: FlashInfer поддерживает множество механизмов, что обеспечивает совместимость с различными форматами хранения данных.
- Оптимизированное декодирование: Значительное увеличение скорости благодаря группированию запросов и новым методам внимания.
- Динамическое управление нагрузкой: Автоматическая адаптация к изменениям, что позволяет оптимально использовать ресурсы GPU.
- Настраиваемая компиляция: Пользователи могут определять и компилировать собственные варианты внимания для специальных задач.
Повышение производительности
FlashInfer показывает заметное улучшение производительности:
- Снижение задержки: Уменьшение задержки обработки данных до 69% по сравнению с существующими решениями.
- Увеличение пропускной способности: До 17% прирост скорости на графических процессорах NVIDIA.
- Улучшенное использование GPU: Эффективное распределение ресурсов, особенно в сценариях с различными длинами последовательностей.
Заключение
FlashInfer предлагает практическое и эффективное решение для задач обработки LLM, обеспечивая значительные улучшения производительности. Его гибкий дизайн и возможность интеграции делают его ценным инструментом для развития AI-приложений. FlashInfer открывает новые горизонты для более доступных и масштабируемых решений в области искусственного интеллекта.
Как использовать AI в вашем бизнесе
Если вы хотите развивать свою компанию с помощью ИИ, рассмотрите следующие шаги:
- Проанализируйте, как ИИ может изменить вашу работу и выделите области для автоматизации.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить.
- Подберите подходящее решение и внедряйте его постепенно.
- На основе собранных данных расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, обращайтесь к нам. Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























